
Hadoop核心元件—MapReduce詳解
Hadoop 分散式計算框架(MapReduce)。
MapReduce設計理念:
- 分散式計算
- 移動計算,而不是移動資料
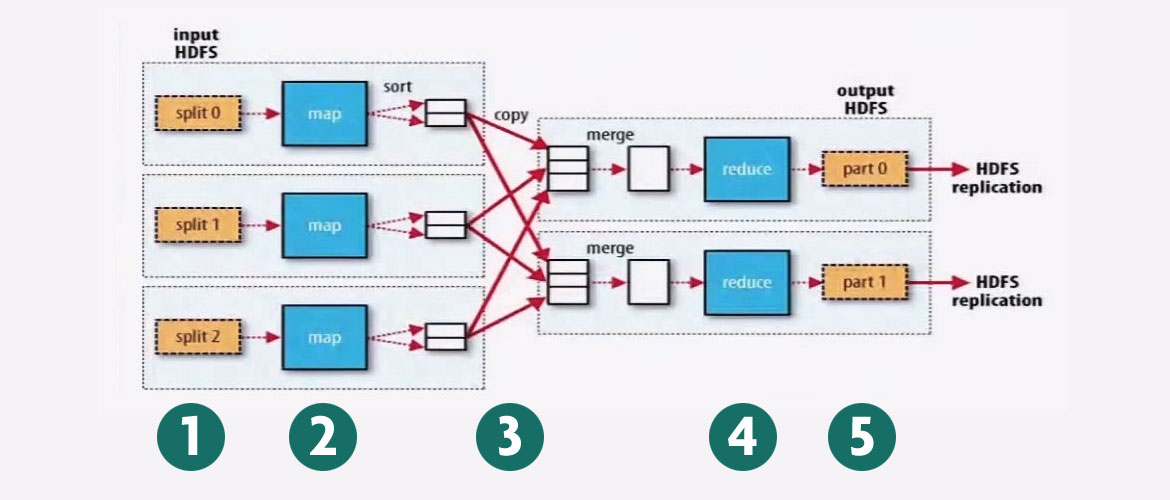
MapReduce計算框架
步驟1:split
split切分Block,得到很多資料片段例如圖中的split0, split1, split2。
步驟2:map
有多少個片段,就有多少個map,map是一個Java執行緒。
執行緒為硬體和物件。
資料按照鍵值對的形式傳給map。
map執行完畢,輸出是鍵值對格式。
步驟3:shuffle
步驟4:reduce
reduce執行緒
reduce task
在一個MapReduce任務中,預設情況下Reduce task只有一個。
步驟5:
part

MapReduce示例
Mapper
-Map-reduce的思想就是"分而治之"
Mapper負責"分",即把複雜的任務分解為若干個"簡單的任務"執行
- "簡單的任務"的含義:
資料或者計算規模相對於原任務要大大減小;
就近計算,即會被分配到存放了所需資料的節點進行計算
這些小任務可以平行計算,彼此間幾乎沒有依賴關係
Reducer
- 對map階段的結果進行彙總。
- Reduce的資料由mapred-site.xml配置檔案裡的專案mapred.reduce.tasks決定。預設值為1,使用者可以覆蓋。
Shuffler
- 在mapper和reducer中間的一個步驟
- 可以把mapper的輸出按照某種key值重新切分和組合成n份,把key值符合某種範圍的輸出送到特定的reducer那裡去處理。
- 可以簡化reducer過程
預設的partion演算法是,根據每一個數據中的key的hashcode / reduce數量得到分割槽號。
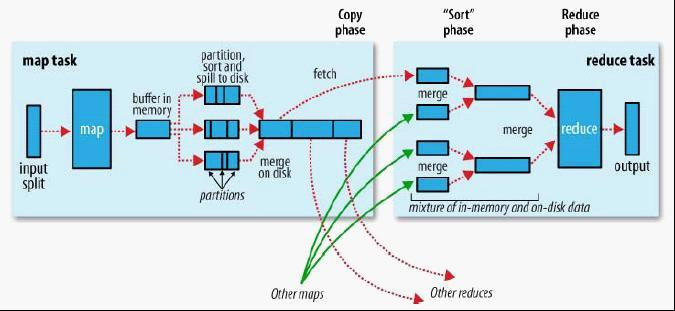
- 每個map task都有一個記憶體緩衝區(預設是100MB),儲存著map的輸出結果
- 當緩衝區快滿的時候需要將快取區的資料以一個臨時檔案的方式存放到磁碟
- 溢寫是單獨執行緒來完成,不影響往緩衝區寫map結果的執行緒(spill.percent,預設是0.8)
- 當溢寫執行緒啟動後,需要對這80MB空間內的key做排序(Sort)
– 假如client設定過Combiner,那麼現在就是使用Combiner的時候了。將有相同key的key/value對的value加起來,減少溢寫到磁碟 的資料量。(reduce1,word1,[8])。
– 當整個map task結束後再對磁碟中這個map task產生的所有臨時檔案做合併(Merge),對於“word1”就是像這樣的:{“word1”, [5, 8, 2, …]},假如有Combiner,{word1 [15]},最終產生一個檔案。
– reduce 從tasktracker copy資料
– copy過來的資料會先放入記憶體緩衝區中,這裡的緩衝區大小要比map端的更為靈活,它基於JVM的heap size設定
– merge有三種形式:1)記憶體到記憶體 2)記憶體到磁碟 3)磁碟到磁碟。merge從不同tasktracker上拿到的資料,{word1 [15,17,2]}
MapReduce的Split大小
– max.split(100M)
– min.split(10M)
– block(64M)
– max(min.split,min(max.split,block))
任何一個碎片段的大小不能超過Block。
YARN
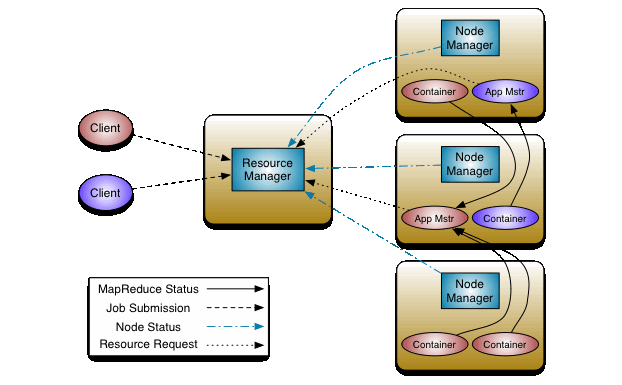
由ResourceManager、NodeManager、JobHistoryServer、Containers、Application Master、job、Task、Client組成。
ResourceManager:一個Cluster只有一個,負責資源排程、資源分配等工作。
NodeManager:執行在DataNode節點,負責啟動Application和對資源的管理。
JobHistoryServer:負責查詢job執行進度及元資料管理。
Containers:Container通過ResourceManager分配。包括容器的CPU、記憶體等資源。
Application Master:ResourceManager將任務給Application Master,然後Application Master再將任務給NodeManager。每個Application只有一個Application Master,執行在Node Manager節點,Application Master是由ResourceManager指派的。
job:是需要執行的一個工作單元:它包括輸入資料、MapReduce程式和配置資訊。job也可以叫作Application。
task:一個具體做Mapper或Reducer的獨立的工作單元。task執行在NodeManager的Container中。
Client:一個提交給ResourceManager的一個Application程式。

二、一個job執行處理的整體流程
使用者向YARN中提交作業,其中包括Application Master啟動、Application Master的命令及使用者程式等;ResourceManager為作業分配第一個Container,並與對應的NodeManager通訊,要求它在這個Container中啟動該作業的Application Master;Application
Master首先向ResourceManager註冊,這樣使用者可以直接通過ResourceManager查詢作業的執行狀態,然後它將為各個任務申請資源並監控任務的執行狀態,直到任務結束。Application通過RPC請求想ResourceManager申請和領取資源。
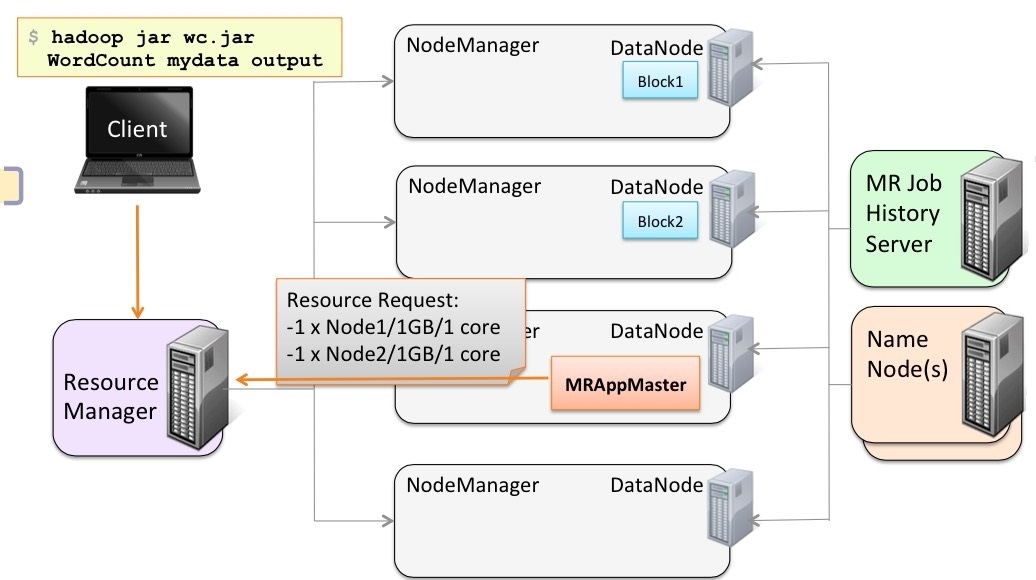
然後ApplicationMaster要求指定的NodeManager節點啟動任務。
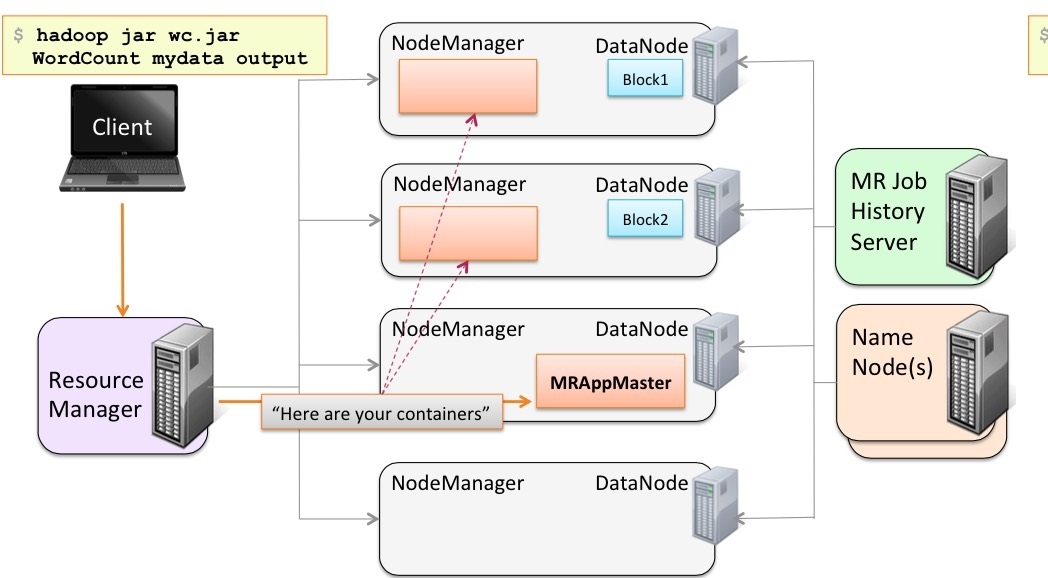
啟動之後,去幹ResoucrceManager指定的Map task。

等Map task幹完之後,通知Application Master。然後Application Master去告知Resource Manager。接下來Resource Manager分配新的資源給Application Master,讓它找人去幹其他的活。
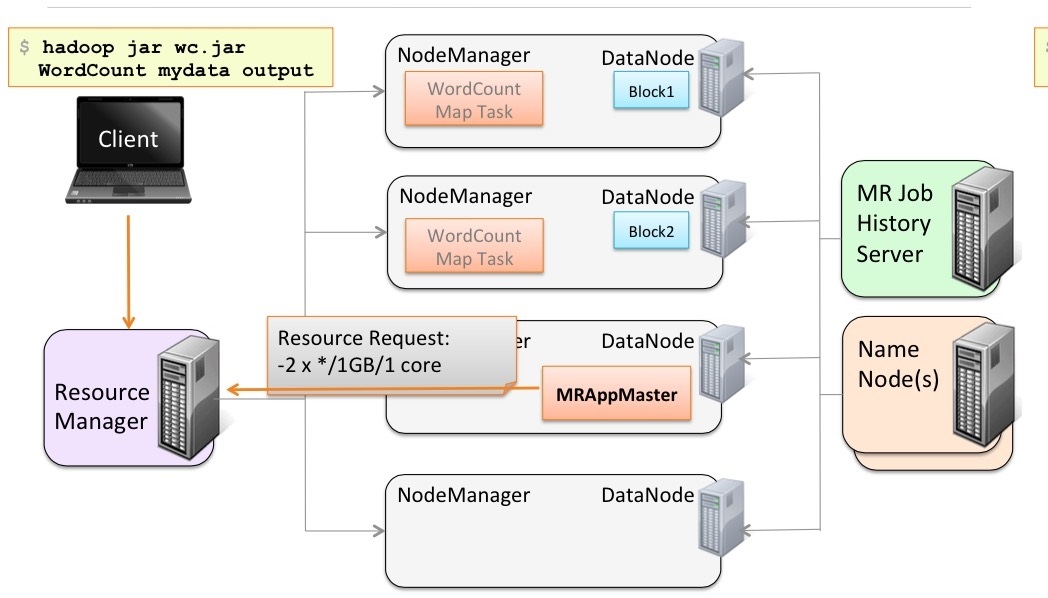
接下來Application Master通知NodeManager啟動新的Container準備幹新的活,該活的輸入是Map task的輸出。
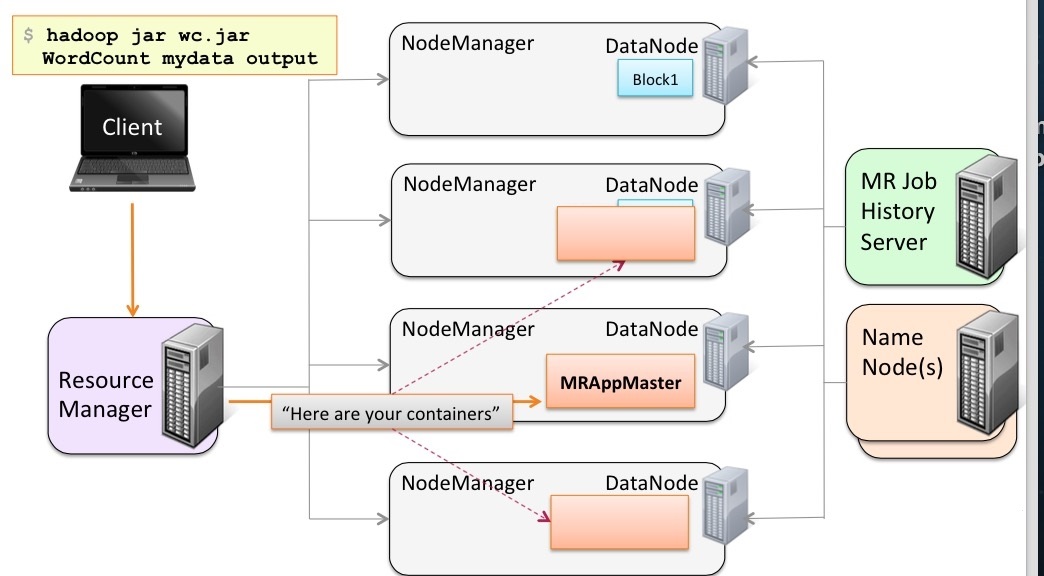
開始幹Reduce task任務。
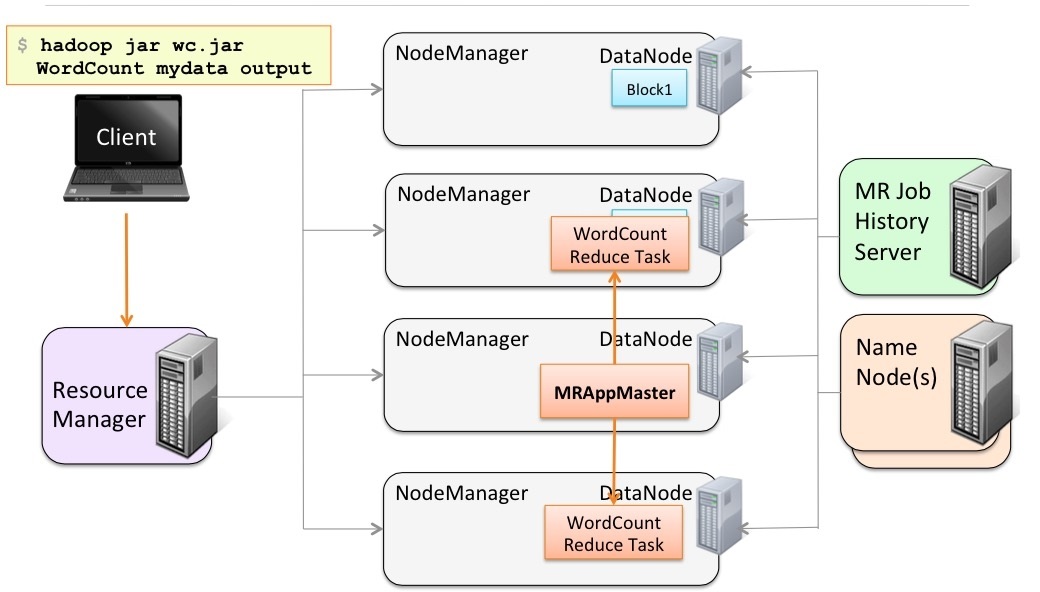
等各個節點的Reduce task都幹好了,將幹活的NodeManager的任務結果進行同步。做最後的Reduce任務。

等計算完了,最後將最終的結果輸出到HDFS。
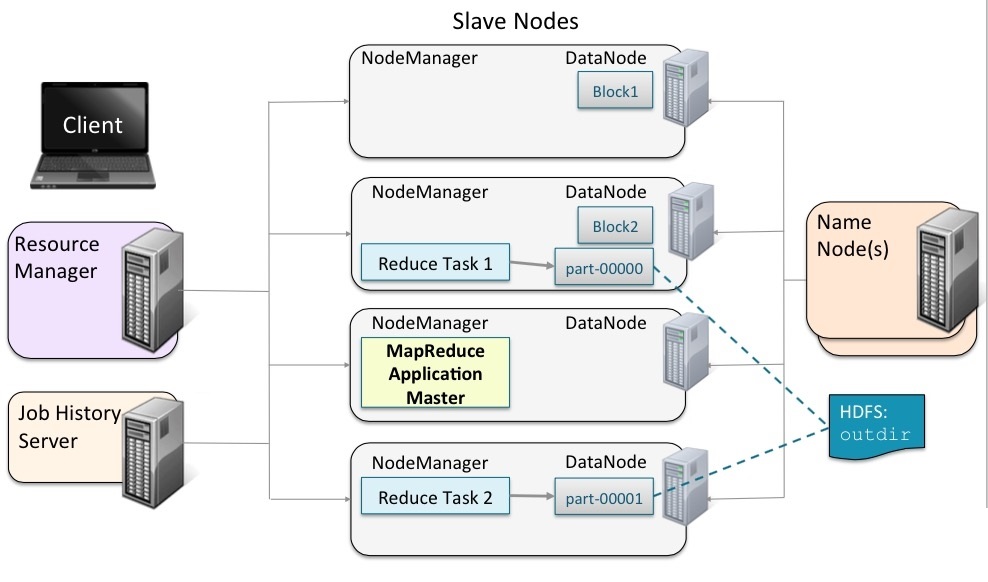
任務完成!