
[DeeplearningAI筆記]卷積神經網路3.1-3.5目標定位/特徵點檢測/目標檢測/滑動視窗的卷積神經網路實現/YOLO演算法
阿新 • • 發佈:2019-02-20
4.3目標檢測
覺得有用的話,歡迎一起討論相互學習~Follow Me
3.1目標定位
物件定位localization和目標檢測detection
- 判斷影象中的物件是不是汽車–Image classification 影象分類
- 不僅要判斷圖片中的物體還要在圖片中標記出它的位置–Classification with localization定位分類
- 當圖片中有 多個 物件時,檢測出它們並確定出其位置,其相對於影象分類和定位分類來說強調一張圖片中有 多個 物件–Detection目標檢測

物件定位localization
- 對於普通的影象分類問題:在最後的輸出層連線上softmax函式,其中softmax神經元的數量取決於分類類別數。
- 對於 定位分類 可以讓神經網路多輸出幾個單元,輸出一個邊界框(bounding box),
- 本節課程中將圖片左上角標記為(0,0),右下角標記為(1,1),邊界框中心標記為,邊界框寬度表示為,高度表示為
- 因此,訓練集中的資料不僅包括神經網路要預測的 物件分類標籤 還要有 物件的邊框位置的四個引數值

- 假設圖片中的物件有四類:1.pedestrian行人,2.car汽車,3.motorcycle摩托車,4.background背景,其中如果圖片中沒有1-3類物件,則預設其為背景。
- 對於目標標籤(target label),其可表示為一個向量,其中第一個元件Pc表示是否有物件。如果物件屬於前三類,則Pc=1,如果圖片中沒有目標物件,即是背景,則Pc=0.
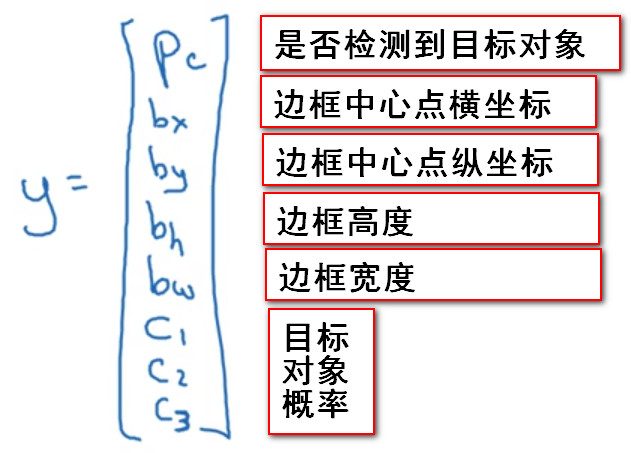
訓練樣本目標標籤

損失函式
- 對於目標標籤中不同的引數,也可以使用不同的損失函式,例如Pc使用邏輯迴歸而其餘的使用平方和誤差。
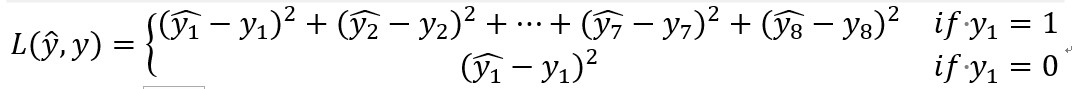
3.2特徵點檢測Landmark detection
- 對於特徵點檢測,給出一個識別面部表情的基本構造模組,即選取面部圖片當中的64個座標作為特徵點。
- 注意:所有的特徵點landmark在整個資料集中表示的含義應當一致
- 則目標標籤的向量可表示為:

- 訓練集中特徵點的座標都是人為辛苦標註的
人體姿態檢測people post-detection
- 通過神經網路標註人物姿態的關鍵特徵點,通過這些特徵點的座標可以辨別人物的姿態。
3.3目標檢測Object detection
基於滑動視窗的目標檢測演算法(sliding windows detection algorithm)
- 對於訓練集樣本,X使用經過裁剪的,檢測目標基本在影象中心的圖片。Y表示樣本圖片中是否有需要檢測的物件。訓練完這個卷積神經網路,接下來就可以用它來實現滑動視窗目標檢測。

- 首先選定一個特定大小的視窗,並使用以上的卷積神經網路判斷這個視窗中有沒有車,滑動目標檢測演算法會從左上角向右並向下滑動輸入視窗,並將擷取的影象都輸入到 已經訓練好的卷積神經網路中 以固定步幅滑動視窗,遍歷影象的每個區域
- 然後使用比以上使用的視窗大一些的視窗,重複進行以上操作。然後再使用比上一次更大的視窗進行影象的擷取與檢測。
- 所以無論目標在影象中的什麼位置,總有一個視窗可以檢測到它。

- 但是滑動視窗目標檢測演算法有十分消耗計算成本的缺點,因為使用視窗會在原始圖片中擷取很多小方塊,並且卷積神經網路需要一個個的進行處理。雖然使用較大的步長可以有效的節省計算成本,但是粗粒度的檢測會影響效能,小步幅和小視窗就會大量的耗費計算成本
- 早些時候在普通的線性分類器上使用滑動視窗目標檢測演算法可以有很好的效能,但是對於卷積神經網路這種對於影象識別相當耗費效能的演算法而言,需要對滑動視窗演算法進行重新設計。
3.4卷積的滑動視窗實現Convolutional implementation of sliding windows
- 3.3中使用的基於滑動視窗的目標檢測演算法效率很低十分消耗計算成本,本節將介紹使用於卷積神經網路的滑動視窗演算法。
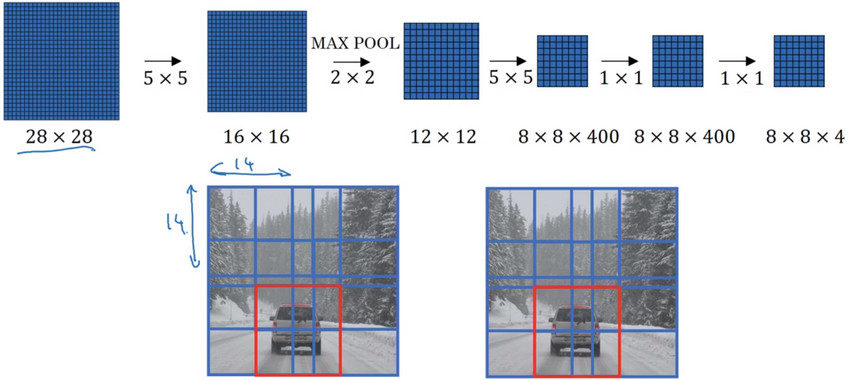
將全連線層轉換為卷積神經層Turning FC layer into convolutional layers
- 使用大小為的圖片作為圖片資料,使用16個的卷積核做卷積操作,得到的特徵圖,然後使用的max-pooling池化演算法,得到的特徵圖.將結果輸入到兩層具有400個神經元節點的全連線層中,然後使用softmax函式進行分類–表示softmax單元輸出的4個分類出現的概率。

- 接下來要將最後連線的兩個全連線層FC1和FC2轉換為卷積層。
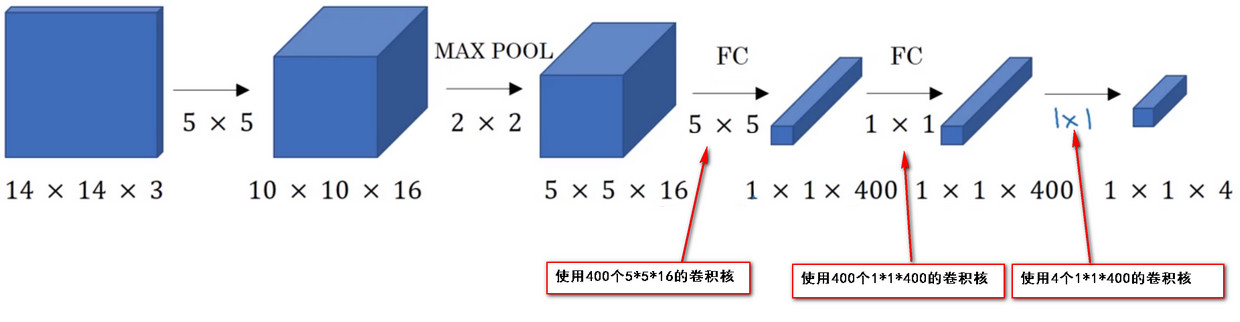
- 方法是 使用與得到的特徵圖大小相同的卷積核進行卷積,卷積核的數量對應全連線層中神經元節點的數量
卷積層的滑動視窗實現Convolution implementation of sliding windows
參考文獻
Sermanet P, Eigen D, Zhang X, et al. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks[J]. Eprint Arxiv, 2013.
- 使用卷積層代替全連線層的網路結構

- 假設的影象是從的影象中截取出來的,即原始影象的大小為.即首先擷取原始圖片中的紅色區域輸入網路,然後擷取綠色區域,接著是黃色區域,最後將紫色區域截取出來作為影象資料集。
- 結果發現,滑動視窗得到的圖片進行的這四次卷積運算中的很多計算都是重複的
- 得到的最終的的稠密特徵圖各不同顏色部分都對應了原始圖片中相同顏色的經過卷積操作後的結果。
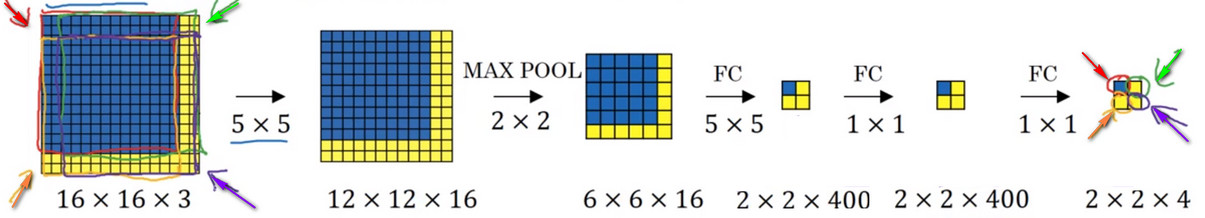
- 所以正確的卷積操作的原理是我們不需要把輸入圖片分割成四個子集,分別傳入卷積神經網路中進行前向傳播,而是把它們作為一張圖片輸入給卷積網路進行計算,其中共有的區域可以共享很多計算
總結
- 對於卷積神經網路的滑動視窗實現,不需要依靠連續的卷積操作來識別圖片中的汽車,而是可以對整張圖片進行卷積操作,一次得到所有的預測值。如果足夠幸運,神經網路便可以識別出汽車的位置。
補充
- 卷積神經網路的滑動視窗實現提高了整個演算法的效率,但是這個方法仍然存在一個缺點: 邊界框的位置可能不夠準確
3.5得到更精確的邊界框Bounding box predictions
- 有時邊界框並沒有完整的匹配圖片中的物件,或者最佳的邊界框並不是正方形,而是橫向略有延伸的長方形。
YOLO algorithm
Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:779-788.
- 其中一個可以得到較精確的邊界框的演算法時YOLO演算法–即You only look once
具體操作方式是:假設影象的大小是,然後在影象上放一個網格,為了描述的簡潔,在此使用的網格,實際中會使用更加精細複雜的網格,可能是.
- 基本思想是使用影象分類和定位演算法(image classification and Localization algorithm)然後將演算法應用到九個格子上。

- 更具體的是:你需要對每個小網格定義一個8維向量的目標標籤,
如何編碼邊界框how to encode the bounding boxes
- 基本思想是使用影象分類和定位演算法(image classification and Localization algorithm)然後將演算法應用到九個格子上。