
spark sql整合hive步驟
SPARK ON HIVE:讓spark sql通過sql的方式去讀取hive當中的資料
HIVE ON SPARK:讓hive的計算引擎由MapReduce改為SPARK
1、 先按官網的參考程式碼,構建
val conf = new SparkConf().setMaster("local[*]").setAppName("hotCount") val sc = new SparkContext(conf) //建立hive的例項 val hiveContext = new HiveContext(sc) hiveContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)") hiveContext.sql("LOAD DATA LOCAL INPATH 'E:/hive.txt' INTO TABLE src") // Queries are expressed in HiveQL hiveContext.sql("FROM src SELECT key, value").collect().foreach(println) |
出現:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V |
我們之後在windows當中配置的hadoop版本是從apache下載,但是我們現在所使用的hadoop版本是cdh的。所以出現的版本不一致的問題。
1、 需要去下載一個cdh版本的hadoop

配置HADOOP_HOME的環境變數
將外掛中的

中的hadoop.dll檔案 複製到C:/windows/system32目錄下
在外掛中的其它檔案,複製到hadoop目錄的/bin目錄下。
注意:有可能是外掛問題

現在可以保證,HiveContext可以操作相應的SQL。
但是該SQL操作的內容是來自於windows本地,沒有與hive表進行連線。
2、讓HiveContext與hive進行連線,出現下面樣式,表示配置已經成功
將hive-site.xml、hdfs-site.xml、core-site.xml檔案加入resource目錄
需要在cdh的版本下,去找到hive的配置檔案
2.1:find / -name ‘hive-site.xml’發現有多個配置檔案,建議使用/etc/目錄下的檔案
2.2:在Idea專案去建立一個resource目錄
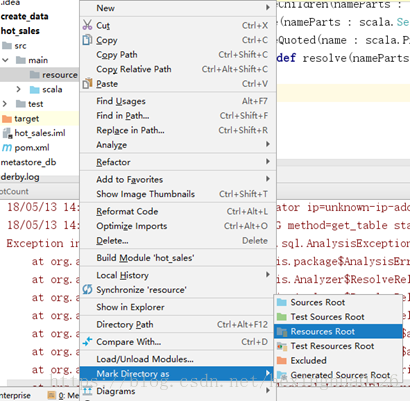
2.3將配置檔案複製到resource目錄下
注意:在sparksql去連線是通過主機名去訪問的,要讓本地的hosts的ip與主機名對應。
連線成功了。但是看不到相應的資料
在hive當中去建立了一個很簡單的表,通過spark sql去測試,發現是可以正常讀取出來的。
查詢不到結果與表結構有關。
flume到hive的表需要要求:分桶與orc格式。
在spark 1.6以及之前不支援。
在spark 2.*當中是可以通過spark sql來操作的。
將原始表中的資料,轉換成我們計算的單元【根據需求來確定】