
11.協程與非同步IO
1. 併發、並行、同步、非同步、阻塞、非阻塞
併發和並行:
併發: 一個時間段內,有幾個程式在同一個cpu上執行,但是任意時刻只有一個程式在cpu上執行
並行: 任意時刻點上, 有多個程式同時執行在多個cpu上
實際舉例說明:
問題 - 喝茶
情況: 開水沒有,水壺要洗,茶壺茶杯要洗;火生類, 茶葉也有了。怎麼辦?
所需時間:
洗水壺: 3
灌涼水: 1
洗茶壺: 3
洗茶杯: 3
拿茶葉: 1
泡茶: 1
燒開水: 30
併發版本:
老趙(cpu1):
辦法1: 洗水壺,灌涼水, 放在火上;等待水燒開的時間裡, 洗水壺,洗茶杯,拿茶葉;等水開了,泡茶喝。 同步和非同步:
同步: 程式碼呼叫IO操作時,必須等待IO操作完成才返回的呼叫方式
非同步: 程式碼呼叫IO操作時,不必等IO操作完成就返回的呼叫方式
阻塞和非阻塞:
阻塞: 呼叫函式時,當前執行緒被掛起 (比如前面socket程式設計中socket.connect就是阻塞的)
非阻塞: 呼叫函式時,當前執行緒不會被掛起,而是立即返回
例子:
小樂愛喝茶,廢話不說,煮開水。
出場人物:小樂,水壺兩把(普通水壺,簡稱水壺;會響的水壺,簡稱響水壺)。
1 小樂把水壺放到火上,立等水開。(同步阻塞)
—— 小樂覺得自己有點傻
2 小樂把水壺放到火上,去客廳看電視,時不時去廚房看看水開沒有。(同步非阻塞)
—— 小樂還是覺得自己有點傻,於是變高端了,買了把會響笛的那種水壺。水開之後,能大聲發出嗚嗚 2. I/O多路複用介紹(select, poll, epoll)
Unix下五種I/O模型:
1)阻塞I/O(blocking I/O)
2)非阻塞I/O (nonblocking I/O)
3)I/O複用(select 和poll) (I/O multiplexing)
4)訊號驅動I/O (signal driven I/O (SIGIO))
5)非同步I/O (asynchronous I/O (the POSIX aio_functions))
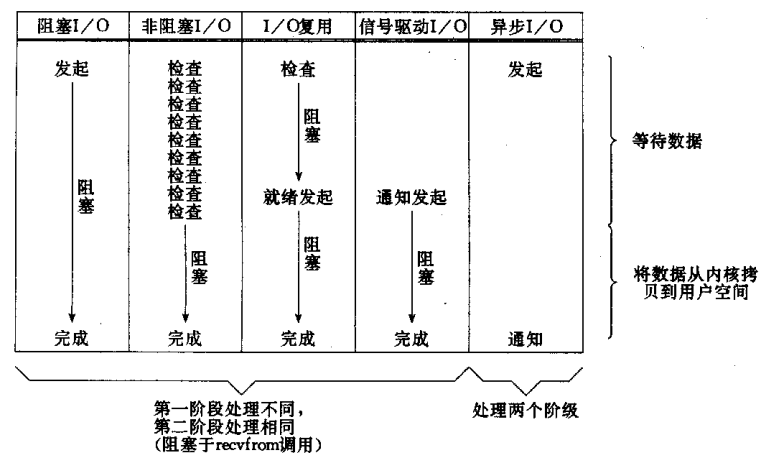
前四種都是同步,只有最後一種才是真正的非同步IO。阻塞I/O:
簡介:程序會一直阻塞,直到資料拷貝完成
描述:應用程式呼叫一個IO函式,導致應用程式阻塞,等待資料準備好。
如果資料沒有準備好,一直等待….資料準備好了,從核心拷貝到使用者空間,IO函式返回成功指示。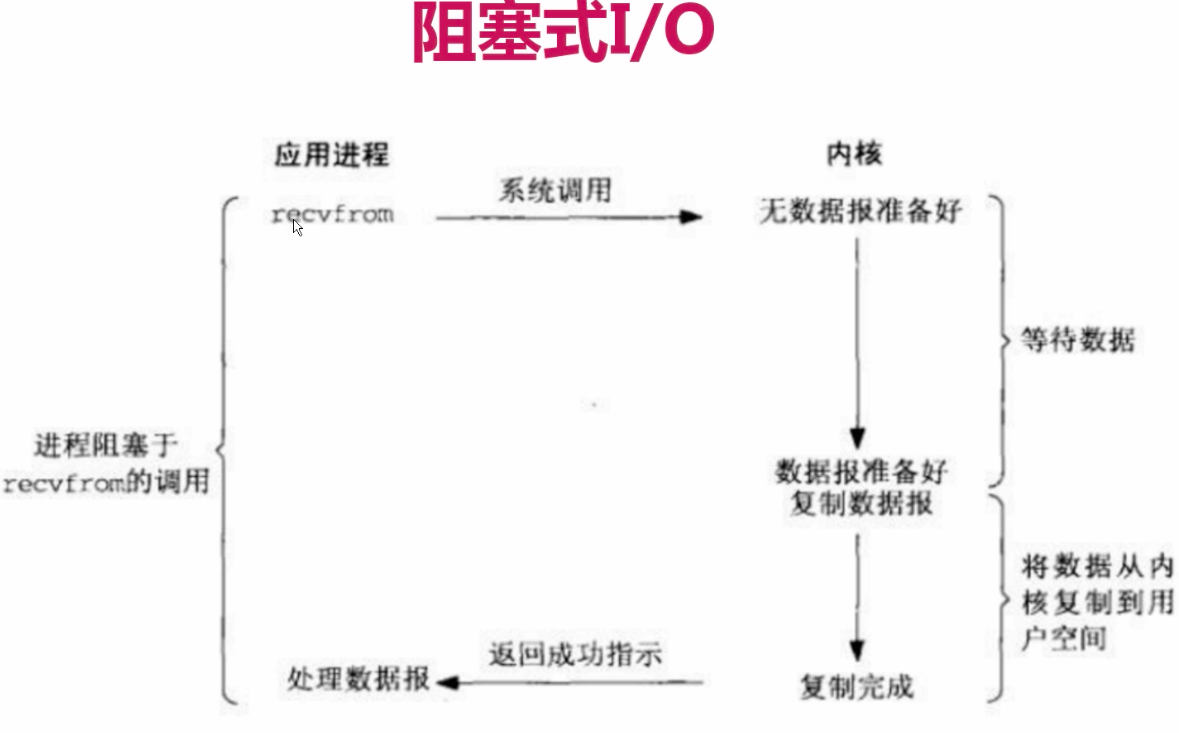
非阻塞IO:
簡介:非阻塞IO通過程序反覆呼叫IO函式(多次系統呼叫,並馬上返回);在資料拷貝的過程中,程序是阻塞的;
描述:我們把一個SOCKET介面設定為非阻塞就是告訴核心,當所請求的I/O操作無法完成時,
不要將程序睡眠,而是返回一個錯誤。這樣我們的I/O操作函式將不斷的測試資料是否已經準備好,
如果沒有準備好,繼續測試,直到資料準備好為止。在這個不斷測試的過程中,會大量的佔用CPU的時間。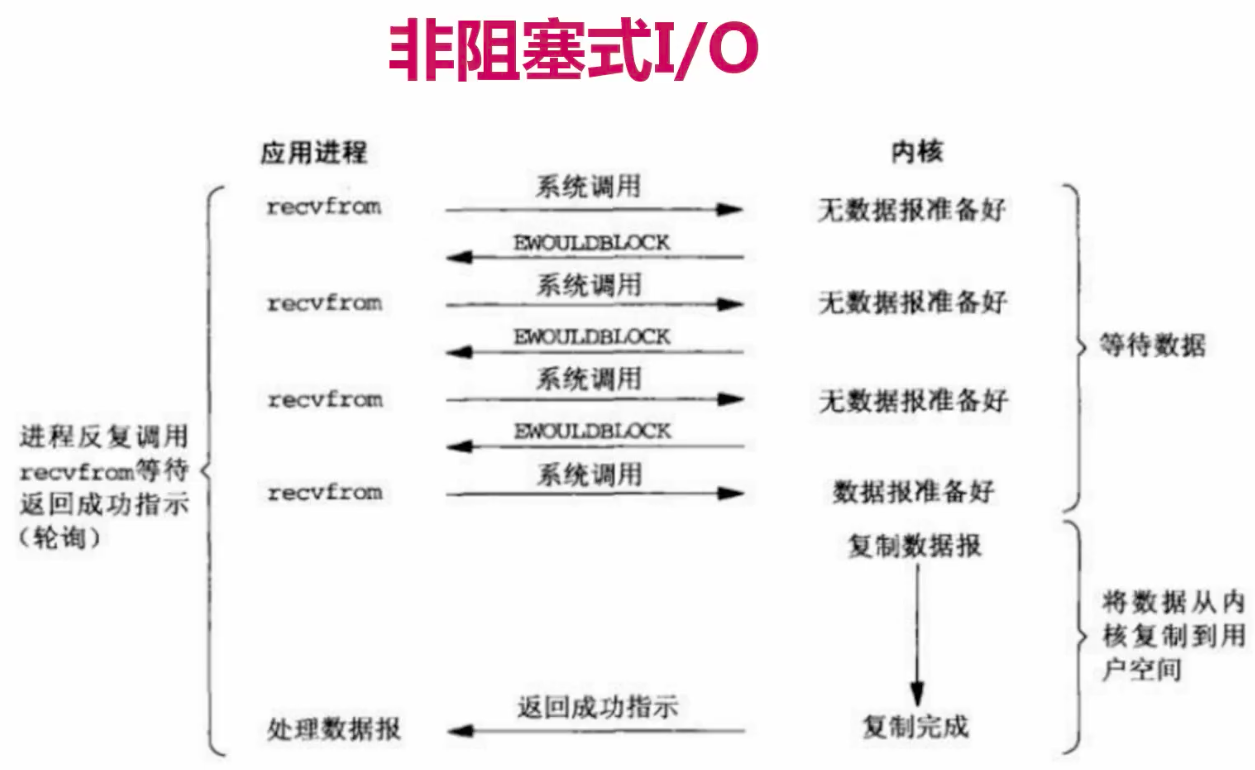
IO複用:
簡介:主要是select和epoll;對一個IO埠,兩次呼叫,兩次返回,
比阻塞IO並沒有什麼優越性;關鍵是能實現同時對多個IO埠進行監聽;
描述:I/O複用模型會用到select、poll、epoll函式,這幾個函式也會使程序阻塞,
但是和阻塞I/O所不同的的,這兩個函式可以同時阻塞多個I/O操作。而且可以同時對多個讀操作,
多個寫操作的I/O函式進行檢測,直到有資料可讀或可寫時,才真正呼叫I/O操作函式。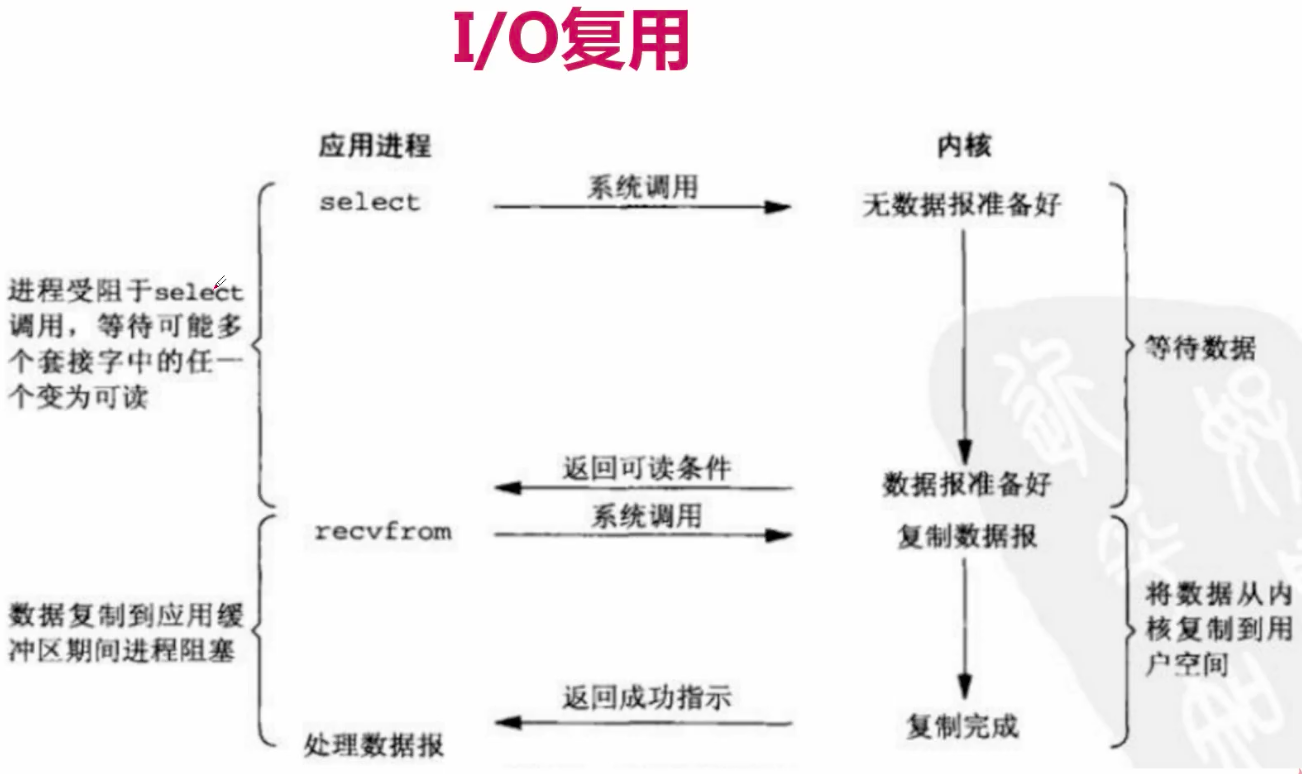
訊號驅動IO:
簡介:兩次呼叫,兩次返回;
描述:首先我們允許套介面進行訊號驅動I/O,並安裝一個訊號處理函式,程序繼續執行並不阻塞。
當資料準備好時,程序會收到一個SIGIO訊號,可以在訊號處理函式中呼叫I/O操作函式處理資料。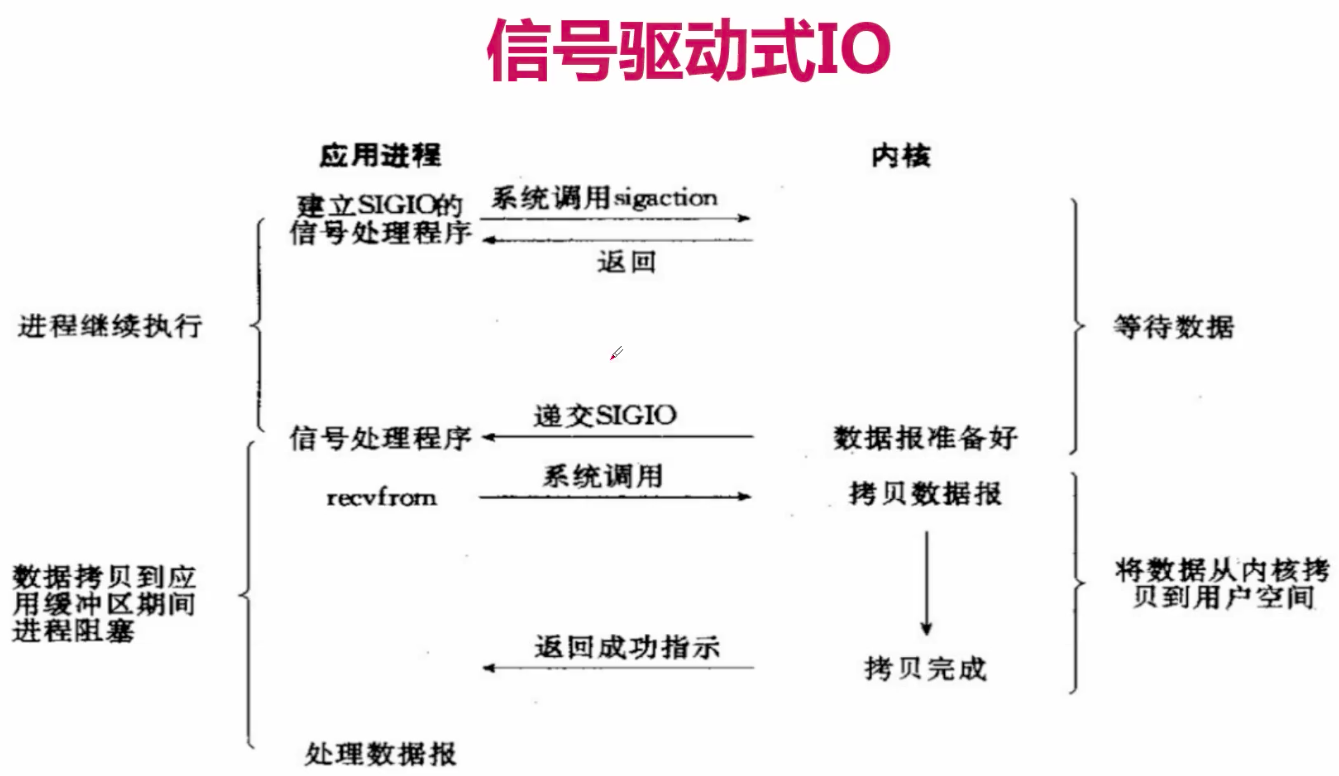
非同步IO模型
簡介:資料拷貝的時候程序無需阻塞。
描述:當一個非同步過程呼叫發出後,呼叫者不能立刻得到結果。實際處理這個呼叫的部件在完成後,
通過狀態、通知和回撥來通知呼叫者的輸入輸出操作同步IO引起程序阻塞,直至IO操作完成。
非同步IO不會引起程序阻塞。IO複用是先通過select呼叫阻塞。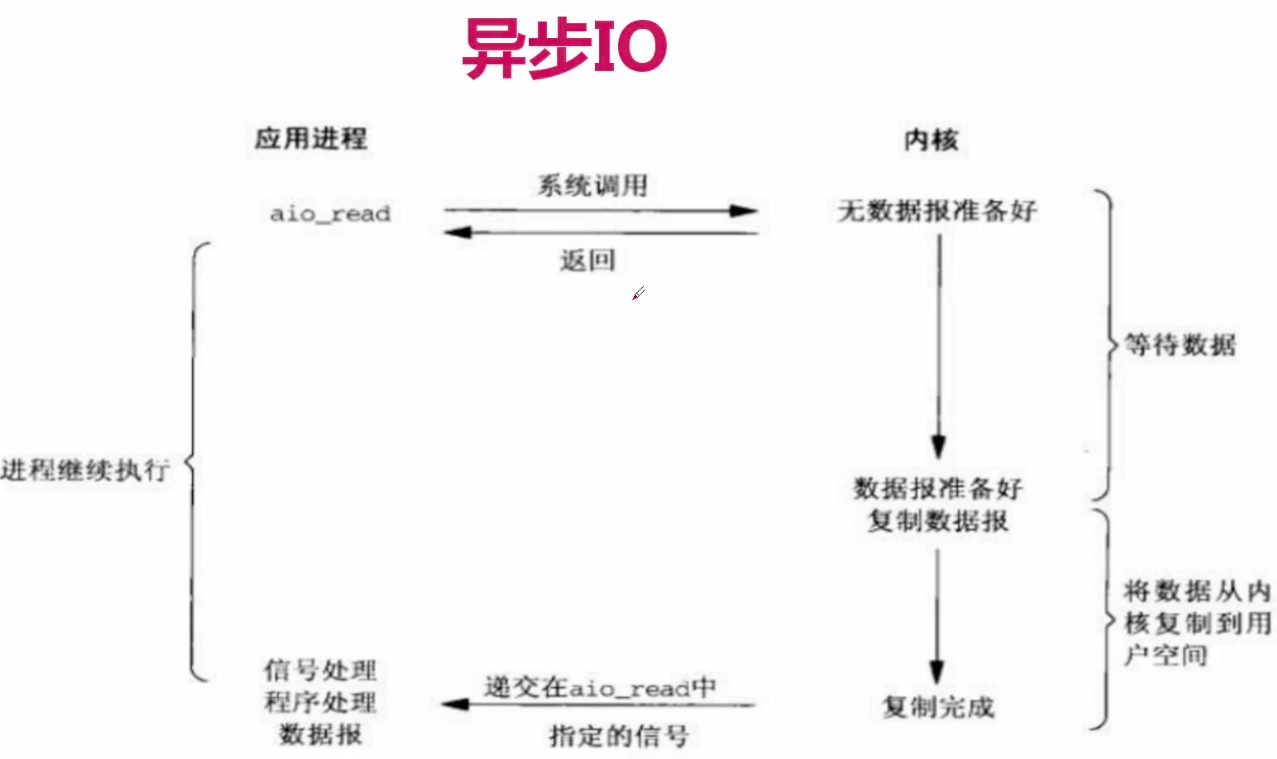
5種I/O模型的比較:
IO複用詳解:
I/O複用的典型應用場景:
1.處理多個描述字時,比如同時處理套接字和磁碟IO、終端IO
2.一個客戶同時處理多個套接字
3.伺服器既要處理監聽套接字,又要處理已連線套接字
4.既要處理TCP、也要處理UDP
5.一個伺服器要處理多個服務和協議
I/O多路複用不侷限於網路程式設計,也可以用於其他程式。select、poll、epoll簡介
epoll跟select都能提供多路I/O複用的解決方案。在現在的Linux核心裡有都能夠支援,其中epoll是Linux所特有,而select則應該是POSIX所規定,一般作業系統均有實現
select:
select函式進行IO複用伺服器模型的原理是:
當一個客戶端連線上伺服器時,伺服器就將其連線的fd加入fd_set集合,
等到這個連線準備好讀或寫的時候,就通知程式進行IO操作,與客戶端進行資料通訊。
大部分 Unix/Linux 都支select函式,該函式用於探測多個檔案控制代碼的狀態變化。
這樣所帶來的缺點是:
1、 單個程序可監視的fd數量被限制,即能監聽埠的大小有限。
一般來說這個數目和系統記憶體關係很大,具體數目可以cat /proc/sys/fs/file-max察看。32位機預設是1024個。64位機預設是2048.
2、 對socket進行掃描時是線性掃描,即採用輪詢的方法,效率較低:
當套接字比較多的時候,每次select()都要通過遍歷FD_SETSIZE個Socket來完成排程,不管哪個Socket是活躍的,都遍歷一遍。這會浪費很多CPU時間。如果能給套接字註冊某個回撥函式,當他們活躍時,自動完成相關操作,那就避免了輪詢,這正是epoll與kqueue做的。
3、需要維護一個用來存放大量fd的資料結構,這樣會使得使用者空間和核心空間在傳遞該結構時複製開銷大
poll:
poll本質上和select沒有區別,它將使用者傳入的陣列拷貝到核心空間,
然後查詢每個fd對應的裝置狀態,如果裝置就緒則在裝置等待佇列中加入一項並繼續遍歷,
如果遍歷完所有fd後沒有發現就緒裝置,則掛起當前程序,直到裝置就緒或者主動超時,
被喚醒後它又要再次遍歷fd。這個過程經歷了多次無謂的遍歷。
它沒有最大連線數的限制,原因是它是基於連結串列來儲存的,但是同樣有一個缺點:
1、大量的fd的陣列被整體複製於使用者態和核心地址空間之間,而不管這樣的複製是不是有意義。
2、poll還有一個特點是“水平觸發”,如果報告了fd後,沒有被處理,那麼下次poll時會再次報告該fd。
epoll:
epoll支援水平觸發和邊緣觸發,最大的特點在於邊緣觸發,它只告訴程序哪些fd剛剛變為就需態,
並且只會通知一次。還有一個特點是,epoll使用“事件”的就緒通知方式,通過epoll_ctl註冊fd,
一旦該fd就緒,核心就會採用類似callback的回撥機制來啟用該fd,epoll_wait便可以收到通知
epoll的優點:
1、沒有最大併發連線的限制,能開啟的FD的上限遠大於1024(1G的記憶體上能監聽約10萬個埠);
2、效率提升,不是輪詢的方式,不會隨著FD數目的增加效率下降。只有活躍可用的FD才會呼叫callback函式;
即Epoll最大的優點就在於它只管你“活躍”的連線,而跟連線總數無關,因此在實際的網路環境中,Epoll的效率就會遠遠高於select和poll。
3、 記憶體拷貝,利用mmap()檔案對映記憶體加速與核心空間的訊息傳遞;即epoll使用mmap減少複製開銷。
綜上,在選擇select,poll,epoll時要根據具體的使用場合以及這三種方式的自身特點。
在高併發情況下, 連線活躍度不是很高, epoll比select好
在併發不高情況下, 連線活躍度高, select比epoll好3. select+回撥+時間迴圈獲取html
先用非阻塞IO的方式實現 模擬http請求:
import socket
from urllib.parse import urlparse
def get_url(url):
# 通過socket請求html
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = '/'
# 建立socket連線
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.setblocking(False) # 非阻塞IO
try:
client.connect((host, 80))
except BlockingIOError as e:
pass
while True:
try:
client.send(
"GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode('utf8'))
break
except OSError as e:
pass
data = b""
while True:
try:
d = client.recv(1024)
except BlockingIOError as e:
continue
if d:
data += d
else:
break
data = data.decode('utf8')
html_data = data.split('\r\n\r\n')[1] # 把請求頭資訊去掉, 只要網頁內容
print(html_data)
client.close()
if __name__ == '__main__':
get_url('http://www.baidu.com')
結論:
在模擬http請求的情形下:
在client.setblocking(False)設定為非阻塞IO之後, client.connect和 client.send依然需要不停的嘗試,
直到成功。實際效果並不比阻塞式IO好。接下來嘗試使用select/epoll方法:
# 通過非阻塞IO實現http請求
# select/epoll + 回撥 + 事件迴圈方式編碼
# 好處: 併發性高
# 在抓取多個網站時,使用單執行緒代替了多執行緒。省去了多執行緒間切換和計算資源的開銷。
import socket
from urllib.parse import urlparse
from selectors import DefaultSelector, EVENT_WRITE, EVENT_READ
# DefaultSelector會自動選擇select還是epoll,windows是select,linux是epoll。但最好還是linux下執行
selector = DefaultSelector()
urls = ['http://www.baidu.com']
stop = False
class Fetcher:
def connected(self, key):
selector.unregister(key.fd)
self.client.send(
"GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(self.path, self.host).encode('utf8'))
selector.register(self.client.fileno(), EVENT_READ, self.readable)
def readable(self, key):
d = self.client.recv(1024)
if d:
self.data += d
else:
selector.unregister(key.fd)
data = self.data.decode('utf8')
html_data = data.split('\r\n\r\n')[1] # 把請求頭資訊去掉, 只要網頁內容
print(html_data)
self.client.close()
urls.remove(self.spider_url)
if not urls:
global stop
stop = True
def get_url(self, url):
self.spider_url = url
url = urlparse(url)
self.host = url.netloc
self.path = url.path
self.data = b""
if self.path == "":
self.path = '/'
# 建立socket連線
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.client.setblocking(False)
try:
self.client.connect((self.host, 80))
except Exception as e:
pass
# 註冊到select中去
selector.register(self.client.fileno(), EVENT_WRITE, self.connected)
def loop():
# 事件迴圈,不停請求socket狀態並呼叫對應的回撥函式
# 1. secletor本身不支援register模式
# 2. socket狀態變化後的回撥是由程式設計師完成的
while not stop:
ready = selector.select()
for key, mask in ready:
call_back = key.data
call_back(key)
# 回撥+事件迴圈+select(poll/epoll)
if __name__ == '__main__':
fetcher = Fetcher()
fetcher.get_url('http://www.baidu.com')
loop() # 事件迴圈
4. 回撥之痛
回撥實現了單執行緒的併發,但卻伴隨一系列問題:
根據select/epoll的回撥編碼方式, 我們可以看出:
相關推薦
11.協程與非同步IO
1. 併發、並行、同步、非同步、阻塞、非阻塞併發和並行:併發: 一個時間段內,有幾個程式在同一個cpu上執行,但是任意時刻只有一個程式在cpu上執行並行: 任意時刻點上, 有多個程式同時執行在多個cpu上實際舉例說明:問題 - 喝茶
情況: 開水沒有,水壺要洗,茶壺茶
協程、非同步IO
協程
協程,又稱微執行緒,纖程。英文名Coroutine。一句話----協程是一種使用者態的輕量級執行緒。
協程擁有自己的暫存器上下文和棧。協程排程切換時,將暫存器上下文和棧儲存到其他地方,在切換回來的時候,恢復先前儲存的暫存器上下文和棧。因此,協程能保留上一次呼叫的狀態(即所有區域性狀態的
python# 程序/執行緒/協程 # IO:同步/非同步/阻塞/非阻塞 # greenlet gevent # 事件驅動與非同步IO # Select\Poll\Epoll非同步IO 以及selector
# 程序/執行緒/協程
# IO:同步/非同步/阻塞/非阻塞
# greenlet gevent
# 事件驅動與非同步IO
# Select\Poll\Epoll非同步IO 以及selectors模組
# Python佇列/RabbitMQ佇列
###########
執行緒,程序,協程,非同步和同步,非阻塞IO
1.執行緒,程序,協程
程序定義:程序是具有一定獨立功能的程式在一個數據集上的一次動態執行的過程,是系統進行資源分配和排程的一個獨立單位
執行緒定義:執行緒是CPU排程和分派的基本單位,是比程序更小能獨立執行的單位,執行緒佔有系統。但是它可以與它同屬的程序和其他在該程序中的執行緒共享
Tornado非同步之-協程與回撥
回撥處理非同步請求
回撥 callback 處理非同步官方例子
# 匯入所需庫
from tornado.httpclient import AsyncHTTPClient
def asynchronous_fetch(url, callback): http
Python37 協程、阻塞IO、非阻塞IO、同步IO、異步IO
python協成又稱為微線程CPU是無法識別協程的,只能識別是線程,協成是由開發人員自己控制的。協成可以在單線程下實現並發的效果(實際計算還是串行的方式)。
如果使用線程在多個函數之間進行上下文切換,那麽這個上下文的邏輯位置是保存在CPU中的,而協程也有上下文切換的操作,但是協成的上下文邏輯位置不是通過CPU
Python開發——15.協程與I/O模型
沒有 mage F5 quest 資源 輸入數據 準備 cor 異步 一、協程(Coroutine)
1.知識背景
協程又稱微線程,是一種用戶態的輕量級線程。子程序,或者稱為函數,在所有語言中都是層級調用,比如A調用B,B在執行過程中又調用了C,C執行完畢返回,B執行完畢返
【PYTHON模塊】:協程與greenlet、gevent
left imp test bind lse 調用 編程模型 send 地址 協程:又稱為微線程,英文名稱Coroutine。作用:它擁有自己的寄存器上下文和棧,能保留上一次調用時的狀態,可以隨時暫停程序,隨時切換回來。優點: ?無需線程上下文切換的開銷 ?無需
Python協程與asyncio
asyncio(解決非同步io程式設計的一整套解決方案,它主要用於非同步網路操作、併發和協程)協程(Coroutine一種使用者態的輕量級微執行緒,它是程式級別的,在執行過程中可以中斷去執行其它的子程式,別的子程式也可以中斷回來繼續執行之前的子程式,無需執行緒上下文切換的開銷)
get_event_loop
python 多程序/多執行緒/協程 同步非同步
這篇主要是對概念的理解:
1、非同步和多執行緒區別:二者不是一個同等關係,非同步是最終目的,多執行緒只是我們實現非同步的一種手段。非同步是當一個呼叫請求傳送給被呼叫者,而呼叫者不用等待其結果的返回而可以做其它的事情。實現非同步可以採用多執行緒技術或則交給另外的程序來處理。多執行緒的好處,比較容易的實現了 非
python用協程池非同步爬取音樂的json資料
# -*- coding: utf-8 -*-
# @Author : Acm
import gevent.monkey
gevent.monkey.patch_all()
from gevent.pool import Pool
from Queue import Queue
imp
swoole 協程與go 協程對比
date: 2018-5-30 14:31:38 title: swoole| swoole 協程初體驗 description: 通過協程的執行初窺 swoole 中協程的排程; 理解協程為什麼快; swoole 協程和 go 協程對比
折騰 swoole 協程有一段時間了, 總結一篇入門貼,
Netty學習之路(一)- 同步與非同步IO
本篇部落格主要是講一些基礎,記錄我的學習過程,同時嘗試養成寫部落格的習慣。內容基本來自Netty權威指南加上一丟丟的個人理解。。。。
I/O基礎入門
在jdk1.4以前,java對i/o的支援並不完善,開發人員在開發高效能i/o時會遇到巨大的挑戰與困難,主要問題如下:
沒
golang語言漸入佳境[20]-協程與通道
協程引入
通過狀態檢查器checkLink,不斷的獲取切片當中的網址,並且列印了出來。順序執行。這也就意味著,一旦我訪問google.com等網站就會陷入到等待的狀況中。後面的網址無法訪問。
1234567891011121314151617181920212223242526
c#Coroutine協程 WebClient非同步下載靜態資源
/// <summary>
/// 非同步下下載靜態資源
/// </summary>
/// <param name="url"></param>
/// <retur
Tornado異步之-協程與回調
tin sync value out 網絡 mark comm 請求 clas
回調處理異步請求
回調 callback 處理異步官方例子
# 導入所需庫
from tornado.httpclient import AsyncHTTPClient
def asyn
python協程與同步
協程與非同步
協程簡介: 協程又稱之為微執行緒,協程看上去也是子程式,但在執行的過程中,在子程式內部可中斷,然後轉而執行別的子程式,在適當的時候返回來接著執行程式。當然子程式是協程的特列。 個人見解:協程相當與在子程式(假設稱之為A程式)執行的過程中執行到一定的步驟後可以進
Python 協程與多工排程
協程與多工排程
時間 2016-03-31 23:02:15
IT技術部落格大學習
原文
在電腦科學中,多工(multitasking)是指在同一個時間段內執行多個任務,現代計算機作為一個複雜的系統,執行的任務往往不止一個,所以多工排程對於計算機來說尤為重要。現階段
libco和tornado、協程和非同步的一些理解
看了些libco的實現,感覺和tornado差不多,基本的思想還是線上程被阻塞的時候能夠去做其他的事情,此時還是用epoll來排程掛起和恢復
從這點看協程依然是基於非同步的,且是純非同步的,只是協程框架提供了更好的語義表達,程式碼書寫更方便了,因此,協程的使用也是用在有一
協程與go語言併發
https://www.cnblogs.com/liang1101/p/7285955.html
https://studygolang.com/articles/10112
簡而言之,協程與執行緒主要區別是它將不再被核心排程,而是交給了程式自己排程(意味著程式設計師需要自己編寫排程程式