
快速生成JavaBean: .sql轉JavaBean一步到位
阿新 • • 發佈:2019-02-20
簡介
我一般資料表結構是用PowerDesigner來建, 建完就需要建Model也即一堆javaBean, 如果沒有輔助工具挨個建要累死, 於是用python寫了這樣一個輔助小工具, 僅需複製下PowerDesigner中Preview中的sql語句, 然後雙擊下工具就直接生成出所有資料表的javaBean了
效果如下
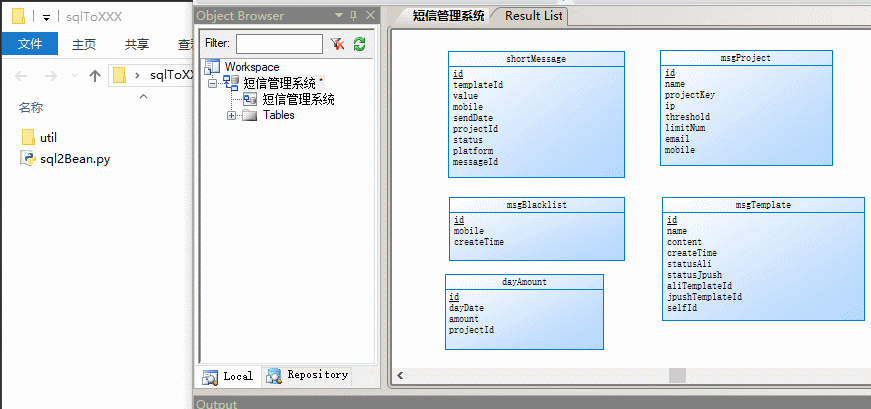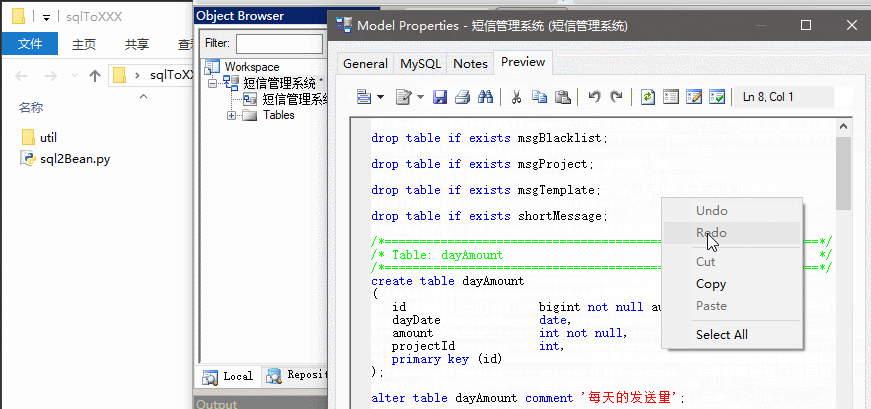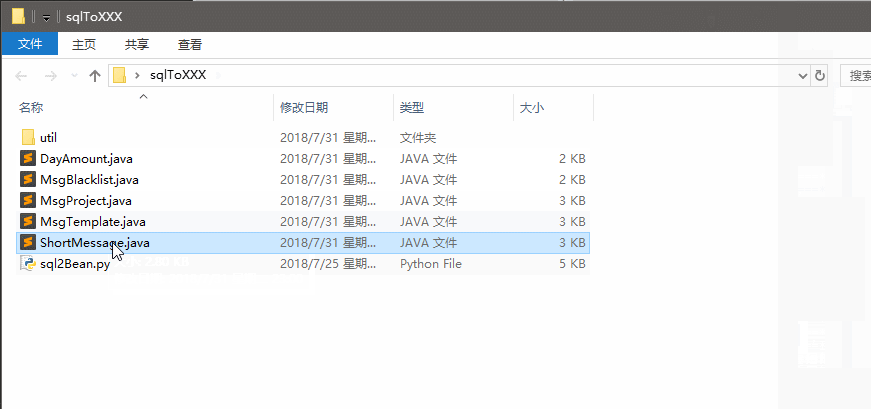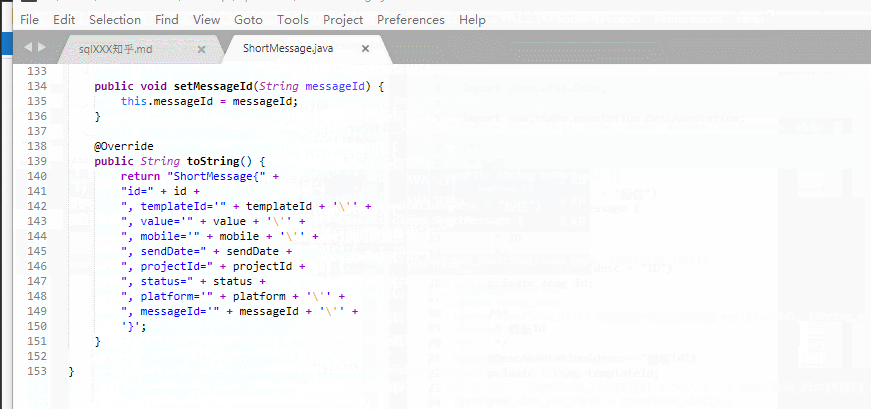
分析
原理很簡單, 解析SQL語句用了正則表示式, 將關鍵資訊封裝起來, 解析完返回後即可以進行拼湊成JavaBean了
SQL的解析如下, 其中get_tables即解析函式, 解析完最終返回一個Table物件的列表, 每張表對應一個Table物件, Table物件中有個Field列表, Field其實就是表裡面的列
class Field:
def __init__(self, name='', type='', comment=''):
self.name = name
self.type = type
self.comment = comment
self.is_not_null = False
self.is_key = False
self.is_auto_increase = False
def __repr__(self):
return "Field(name=%s, type=%s, comment=%s)" - 解析完得到Table的列表後, 剩下的就非常簡單了, toString也好getter setter也好最終也僅僅是字串的拼拼湊湊而已; 比較麻煩也就toString, 參照IDEA的toString格式的話, String型別在toString裡面兩邊還掛著對單引號, 加上各種縮排轉義啥的折騰起來有點亂. 程式碼如下
TO_STRING_TEMPLATE = """
@Override
public String toString() {{
return {}
}}
"""
def gen_tostring(class_name, typefield_list):
"""
生成並返回tostring
:param class_name
:param typefield_list: 欄位型別+名的元組列表 eg:[(int,id), (String,name), (Date,createTime)]
:return: str
"""
tostring = '\"' + class_name + '{\" +\n'
tostring += '\t\t\"' + \
typefield_list[0][1] + '=\" + ' + typefield_list[0][1] + ' +\n'
typefield_list_ext_first = typefield_list[1:]
for type_field in typefield_list_ext_first:
single_quote_left = r"'" if type_field[0] == 'String' else ""
single_quote_right = r" + '\''" if type_field[0] == 'String' else ""
tostring += '\t\t\", ' + type_field[1] + '=' + single_quote_left + '\" + ' + type_field[
1] + single_quote_right + ' + \n'
tostring += "\t\t\'}\';"
return TO_STRING_TEMPLATE.format(tostring)
- 最終生成的toString效果如下:
@Override
public String toString() {
return "Job{" +
"id=" + id +
", name='" + name + '\'' +
", description='" + description + '\'' +
", cronExpression='" + cronExpression + '\'' +
", startTime='" + startTime + '\'' +
", endTime='" + endTime + '\'' +
", exeCount=" + exeCount +
", maxExeCount=" + maxExeCount +
", status='" + status + '\'' +
", className='" + className + '\'' +
", methodName='" + methodName + '\'' +
", delayTime=" + delayTime +
", intervalTime=" + intervalTime +
'}';
}- 至於複製完直接雙擊就可以生成JavaBean, 這個則直接去拿剪貼簿的資料然後判斷是否是屬於sql語句, 如果是則直接生成JavaBean
Ps
- Sql2Bean本來給自己用的, 所以夾了點私貨, 如多了@DescAnnotation註解等, 只要把Sql2Bean裡面額IS_SIMBA變數置為False即可生成不帶私貨的JavaBean :)