
一個例子讓你瞭解MapReduce中shuffle的過程
Shuffle
Shuffle基本概念
Shuffle的本義是洗牌、混洗,把一組有一定規則的資料儘量轉換成一組無規則的資料,越隨機越好。MapReduce中的Shuffle更像是洗牌的逆過程,把一組無規則的資料儘量轉換成一組具有一定規則的資料。
MapReduce 過程為什麼需要shuffle過程呢?
我們都知道MapReduce計算模型一般包括兩個重要的階段:Map是對映,負責資料的過濾分發;Reduce是規約,負責資料的計算歸併。Reduce的資料來源於Map,Map的輸出即是Reduce的輸入,Reduce需要通過Shuffle來獲取資料。Map和Reduce輸出的個格式都是一致,但是我們Reduce的輸入可能和Map的輸出不一樣,這時候需要shuffle聚集
廣義來說:Map的輸出到Reduce輸入這段稱為shuffle過程,由hadoop預設執行,中間執行步驟有Combiner和Partitioner,sort和Merge。如下圖:
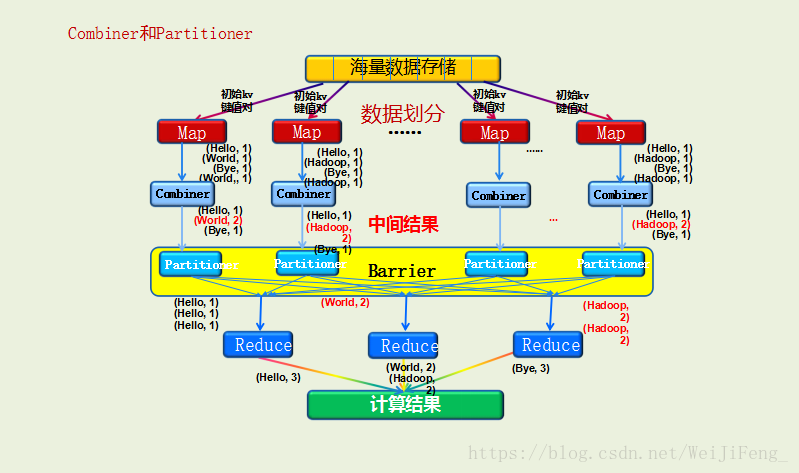
Combiner
- 一個可選的本地reducer,可以在map階段聚合資料
- 可以明顯減少通過網路傳輸的資料量
- 使用combiner可以產生特別大的效能提升,並且沒有副作用
- 不能保證執行,不能作為整個演算法的一部分
- 並不是所有情況下都能使用combiner,combiner使用於對記錄彙總的場景(如求和,但是求平均數的場景就不能使用了
Combiner對系統的優化
問題:大量的鍵值對資料在傳送給Reduce節點時會引起較大的通訊頻寬開銷。
解決方案:
每個Map節點處理完成的中間鍵值隊將由combiner做一個合併壓縮,即把那些鍵名相同的鍵值對歸併為一個鍵名下的一組數值。

Partitioner
- 將mapper(如果使用了combiner就是combiner)輸出的鍵/值對拆分為分片(shard),每個reducer對應一個分片。
- (1)partitioner元件可以讓Map對Key進行分割槽,從而可以根據不同的key來分發到不同的reduce中去處理;
- (2)你可以自定義key的一個分發股則,如資料檔案包含不同的省份,而輸出的要求是每個省份輸出一個檔案;
- (3)提供了一個預設的HashPartitioner。
用資料分割槽解決資料相關性問題:
問題:
一個Reduce節點上的計算資料可能會來自多個Map節點,因此,為了在進入Reduce節點計算之前,需要把屬於一個Reduce節點的資料歸併到一起。
解決方按:
在Map階段進行了Combining以後,可以根據一定的策略對Map輸出的中間結果進行分割槽(partitioning),這樣既可解決以上資料相關性問題避免Reduce計算過程中的資料通訊。
例如:
有一個巨大的陣列,其最終結果需要排序,每個Map節點資料處理好後,為了避免在每個Reduce節點本地排序完成後還需要進行全域性排序,我們可以使用一個分割槽策略如:(d%R),d為資料大小,R為Reduce節點的個數,則可根據資料的大小將其劃分到指定資料範圍的Reduce節點上,每個Reduce將本地資料排好序後即為最終結果。
Partitioner主要作用:
就是將map的結果傳送到相應的reduce。這就對partitioner有兩個要求:
1)均衡負載,儘量的將工作均勻的分配給不同的reduce。
2)效率,分配速度一定要快。
Shuffle過程的期望
- 完整地從map task端拉取資料到reduce 端。
- 在跨節點拉取資料時,儘可能地減少對頻寬的不必要消耗。
- 減少磁碟IO對task執行的影響。
Shuffle描述著資料從map task輸出到reduce task輸入的這段過程。
每個map task都有一個 記憶體緩衝區,儲存著map的輸出結果,當緩衝區快滿的時候需要將緩衝區的資料以一個臨時檔案的方式存放到磁碟,當整個map task結束後再對磁碟中這個map task產生的所有臨時檔案做合併,生成最終的正式輸出檔案,然後等待reduce task來拉資料。
Sort
先把 緩衝區中的資料按照partition值和key兩個關鍵字升序排序,移動的只是索引資料,排序結果是Kvmeta中資料按照partition為單位聚集在一起,同一partition內的按照key有序。
Merge
對於資料量非常大,Map task的記憶體緩衝區不夠,達到一定容量時候,就要把記憶體緩衝區的內容寫入out檔案。
對於很多out檔案,此時Merge就閃亮登場了。
然後為merge過程建立一個叫file.out的檔案和一個叫file.out.Index的檔案用來儲存最終的輸出和索引。
根據file.out.index檔案和file.out檔案提供out檔案的路徑和索引,指出之前記憶體快取區寫出的out檔案結果進行掃描。
最後一個partition一個partition的進行合併輸出。對於某個partition來說,從索引列表中查詢這個partition對應的所有索引資訊,每個對應一個段插入到段列表中。也就是這個partition對應一個段列表,記錄所有的Spill檔案中對應的這個partition那段資料的檔名、起始位置、長度等等。