
TensorFlow學習筆記(UTF-8 問題解決 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: in
今天在跑跑程式碼時,遇到了標題的問題,然後網上查了下,在此處:
http://www.cnblogs.com/Qt-Chao/p/7474360.html 剛剛好講解了解決該問題的辦法,這裡當作一個筆記,記錄下來。
我使用VS2013 Python3.5 TensorFlow 1.3 的開發環境
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
在是使用Tensorflow讀取圖片檔案的情況下,會出現這個報錯
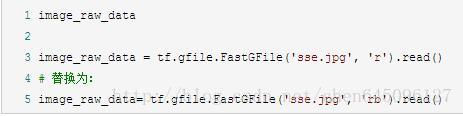
程式碼如下

報錯如下:

度娘沒有查詢到結果,Google上找到了相應的解決方案:
相關推薦
TensorFlow學習筆記(UTF-8 問題解決 UnicodeDecodeError- 'utf-8' codec can't decode byte 0xff in position 0- in
我使用VS2013 Python3.5 TensorFlow 1.3 的開發環境 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte 在
TensorFlow學習筆記(UTF-8 問題解決 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: in
今天在跑跑程式碼時,遇到了標題的問題,然後網上查了下,在此處: http://www.cnblogs.com/Qt-Chao/p/7474360.html 剛剛好講解了解決該問題的辦法,這裡當作一個筆記,記錄下來。 我使用VS2013 Python3.5 Tenso
解決UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte問題
本文最後更新於2018-6-20,可能會因為沒有更新而失效。如已失效或需要修正,請聯絡我! 早上在用Flask框架時出現了這個問題,我在原始碼裡寫的是 @app.route('/hello') def hello(): return render_te
'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
‘utf-8’ codec can’t decode byte 0xff in position 0: invalid start byte 覺得有用的話,歡迎一起討論相互學習~Follow Me 今天使用語句 image_raw_data_jpg
部署django中出現UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8 in position 3解決方案
在《Python入門到實踐》18.3例程中,編寫好index.html <p>Learning Log</p><p>Learning Log helps you keep track of your learning,for any to
Python3解決UnicodeDecodeError: 'utf-8' codec can't decode byte..問題 終極解決方案
0x00 問題引出: 最近在做一個買房自動化分析Python指令碼,需要爬取網頁。 在使用urllib獲取reqest的response的時候,還要進行解碼。 見語句: result = res.decode('utf-8') 當執行該語句的時候,
py檔案增加encoding='utf-8',errors='ignore' 後仍然沒解決UnicodeDecodeError: 'gbk' codec can't decode byte
感覺和oracle的輸出字符集有關,gbk,gb18030都試了沒解決,注意紅色部分,修改後解決問題 #!/usr/bin/env python import sys import csv import cx_Oracle import codecs import os
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte解決方法
最近在學機器學習,看《機器學習實戰》,因為書上的程式碼是在Python2下編寫的,所以轉到Python3會有許多問題需要修改。 第3章決策樹有一個函式如下: def grabTree(filename): import pickle fr = open(f
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa8 in position 怎麼辦
如題,我遇到了要讀取csv結果發生: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa8 in position 2987: invalid start byte 怎麼辦呢? 原來的csv儲存命令是: df.t
python 讀取資料出現UnicodeDecodeError:: 'utf-8' codec can't decode byte 0xc8 in position 0: invalid contin
之前寫程式時也出現過類似錯誤,每次解決了到第二次遇見又忘了具體方法,這次記錄一下。 一、字元編碼問題 先介紹一下字元編碼問題 1.ASCLL與GB2312 由於計算機是美國人發明的,因此,最早只有127個字元被編碼到計算機裡,也就是大小寫英文字母、數字和一些符號,這個
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte...
其他 編碼問題 nbsp pan utf-8 erro can 問題 報錯 1. 編碼問題, 如果來源為編碼為其他的,而是用utf-8去解碼就會報錯。 2. 如果只是有部分無法解碼, 則添加 ‘ingnore’ 參數 a = b‘...‘ result = a.d
【轉】UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc7 in position 1: invalid continuation 漢字編碼
如果在python 3裡面碰到下面的Error message: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc7 in position 1: invalid continuation byte。 你很可
VS2015 下python程式設計,報錯:'utf-8' codec can't decode byte,解決辦法?
問題描述,形如以下的C++呼叫python程式碼,在vs2015下報中文編碼錯誤 #include <iostream> using namespace std; int main() { Py_Initialize(); /*初始化
解決UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128)
style 資料 spa 和數 cnblogs ref lib utf 其中 今天做網頁到了測試和數據庫交互的地方,其中HTML和數據庫都是設置成utf-8格式編碼,插入到數據庫中是正確的,但是當讀取出來的時候就會出錯,原因就是Python的str默認是ascii編碼,
python3 'utf-8' codec can't decode byte 0xb3
問題:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb3 in position 109: invalid start byte 該問題發生於decode解碼; 編碼與解碼: 編碼就是將字串轉換成位元組碼,涉
python執行時出現UnicodeDecodeError: 'gbk' codec can't decode byte 0x89 in position 14: illegal ...的解決辦法
在python第四次實驗作業時: python在讀取檔案時出現“UnicodeDecodeError: 'gbk' codec can't decode byte 0x89 in position 14: illegal multibyte sequence”錯誤 翻譯為
python報錯"utf-8 codec can't decode byte 0x"
望文生義,報錯的內容就是說utf-8的編碼方式不能解碼0x的位元組,選擇正確的解碼方式就可以解決。 深入些理解,可以把編碼就是編成位元組資料,就是二進位制的東西,解碼以後就是我們看懂的字串,python裡面就是unicode型別。但是打碼的方式有很多,需要採用適合的方法(打
[python]解決Windows下安裝第三方外掛報錯:UnicodeDecodeError: 'ascii' codec can't decode byte 0xcb in position 0:
系統:win10 IDE:pycharm Python版本:2.7 安裝第三方外掛是報錯: 報錯原因與編碼有關,pip把下載的臨時檔案存放在了使用者臨時檔案中,這個目錄一般是C:\Users
webpy 解決中文出現UnicodeDecodeError: 'ascii' codec can't decode byte 問題
學習webpy過程中,出現 UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 29: ordinal not in range(128) 錯誤 百度之後參考如下文章解決: http://
解決UnicodeDecodeError: 'utf8' codec can't decode byte 0x9c
問題 with open(file, 'rb') as f: for raw_line in f: # process 但是我在執行時會報TypeError錯誤: TypeError: sequence