
使用vectorizer.fit_transform時出現AttributeError: 'file' object has no attribute 'lower'
阿新 • • 發佈:2019-02-20
問題
最近在讀書《Building Machine Learning Systems with Python》1第一版,發現其中的一個程式碼錯誤,
AttributeError: ‘file’ object has no attribute ‘lower’
產生該錯誤的程式碼為:
import os
os.listdir('./data/toy/')
posts = [open(os.path.join('./data/toy/',f)) for f in os.listdir('./data/toy/')]
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1 解決方法
感謝網站提供的解決方法,即將vectorizer = CountVectorizer(min_df=1)改為
vectorizer = CountVectorizer(min_df=1,input="file")即可解決上面的錯誤。
由於我使用的是Ipython notebook執行環境,在同一個cell裡面將程式碼改變了以後,重新執行,則出現了新的錯誤:
ValueError: empty vocabulary; perhaps the documents only contain stop words嘗試了半天也沒有找到合適的解決辦法。最後,我找到了解決辦法:刪除所有含有之前程式碼的cell,新建一個cell,在裡面寫入更新的程式碼,即可解決 “empty vocabularty”錯誤。這個錯誤與程式碼本身無關,而與使用的Ipython notebook環境有關。希望大家在以後使用Ipython notebook時,注意這類的問題。
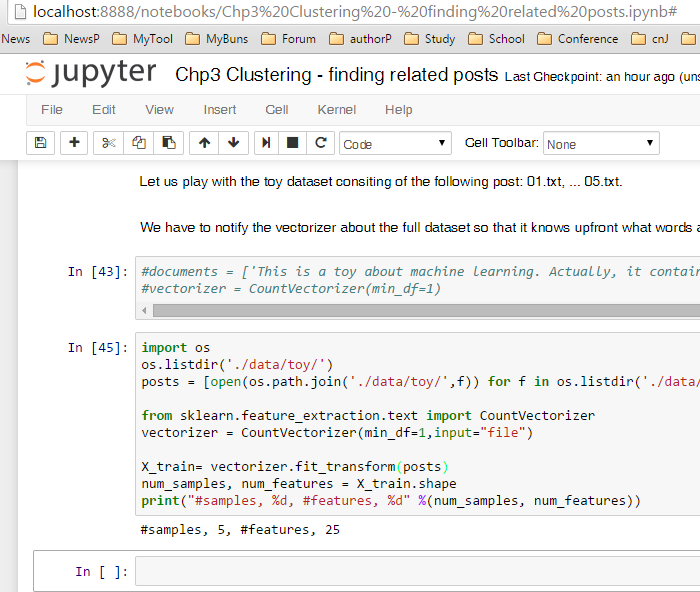
執行成功的介面為:
- Building Machine Learning Systems with Python. 2013. Willi Ricchert, Luis Pedro Coelho. Packt publishing. ↩