
Redis 總結精講
本文圍繞以下幾點進行闡述
1、為什麽使用redis
2、使用redis有什麽缺點
3、單線程的redis為什麽這麽快
4、redis的數據類型,以及每種數據類型的使用場景
5、redis的過期策略以及內存淘汰機制
6、redis和數據庫雙寫一致性問題
7、如何應對緩存穿透和緩存雪崩問題
8、如何解決redis的並發競爭問題
正文
1、為什麽使用redis
分析:博主覺得在項目中使用redis,主要是從兩個角度去考慮:性能和並發。當然,redis還具備可以做分布式鎖等其他功能,但是如果只是為了分布式鎖這些其他功能,完全還有其他中間件(如zookpeer等)代替,並不是非要使用redis。因此,這個問題主要從性能和並發兩個角度去答。
回答:如下所示,分為兩點
(一)性能
如下圖所示,我們在碰到需要執行耗時特別久,且結果不頻繁變動的SQL,就特別適合將運行結果放入緩存。這樣,後面的請求就去緩存中讀取,使得請求能夠迅速響應。
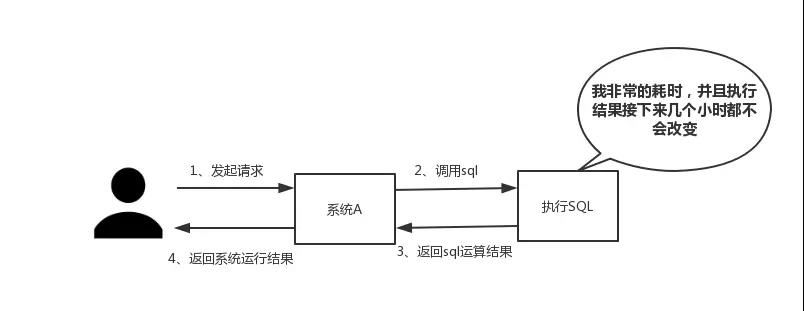
題外話:忽然想聊一下這個迅速響應的標準。其實根據交互效果的不同,這個響應時間沒有固定標準。不過曾經有人這麽告訴我:”在理想狀態下,我們的頁面跳轉需要在瞬間解決,對於頁內操作則需要在剎那間解決。另外,超過一彈指的耗時操作要有進度提示,並且可以隨時中止或取消,這樣才能給用戶最好的體驗。”
那麽瞬間、剎那、一彈指具體是多少時間呢?
根據《摩訶僧祗律》記載
一剎那者為一念,二十念為一瞬,二十瞬為一彈指,二十彈指為一羅預,二十羅預為一須臾,一日一夜有三十須臾。
那麽,經過周密的計算,一瞬間為0.36 秒,一剎那有 0.018 秒.一彈指長達 7.2 秒。
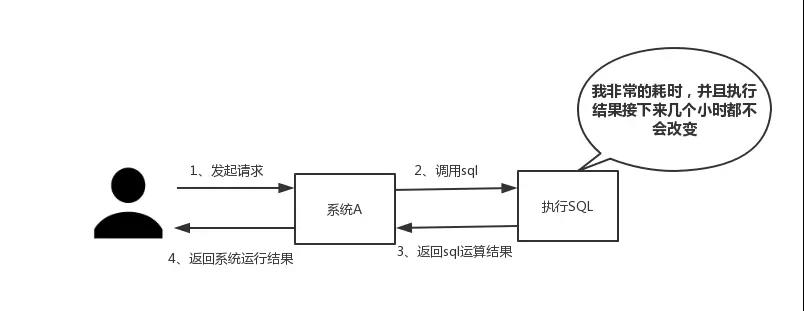
(二)並發
如下圖所示,在大並發的情況下,所有的請求直接訪問數據庫,數據庫會出現連接異常。這個時候,就需要使用redis做一個緩沖操作,讓請求先訪問到redis,而不是直接訪問數據庫。
2、使用redis有什麽缺點
分析:大家用redis這麽久,這個問題是必須要了解的,基本上使用redis都會碰到一些問題,常見的也就幾個。
回答:主要是四個問題
(一)緩存和數據庫雙寫一致性問題
(二)緩存雪崩問題
(三)緩存擊穿問題
(四)緩存的並發競爭問題
這四個問題,我個人是覺得在項目中,比較常遇見的,具體解決方案,後文給出。
3、單線程的redis為什麽這麽快
分析:這個問題其實是對redis內部機制的一個考察。其實根據博主的面試經驗,很多人其實都不知道redis是單線程工作模型。所以,這個問題還是應該要復習一下的。
回答:主要是以下三點
(一)純內存操作
(二)單線程操作,避免了頻繁的上下文切換
(三)采用了非阻塞I/O多路復用機制
題外話:我們現在要仔細的說一說I/O多路復用機制,因為這個說法實在是太通俗了,通俗到一般人都不懂是什麽意思。博主打一個比方:小曲在S城開了一家快遞店,負責同城快送服務。小曲因為資金限制,雇傭了一批快遞員,然後小曲發現資金不夠了,只夠買一輛車送快遞。
經營方式一
客戶每送來一份快遞,小曲就讓一個快遞員盯著,然後快遞員開車去送快遞。慢慢的小曲就發現了這種經營方式存在下述問題
-
幾十個快遞員基本上時間都花在了搶車上了,大部分快遞員都處在閑置狀態,誰搶到了車,誰就能去送快遞
-
隨著快遞的增多,快遞員也越來越多,小曲發現快遞店裏越來越擠,沒辦法雇傭新的快遞員了
-
快遞員之間的協調很花時間
綜合上述缺點,小曲痛定思痛,提出了下面的經營方式
經營方式二
小曲只雇傭一個快遞員。然後呢,客戶送來的快遞,小曲按送達地點標註好,然後依次放在一個地方。最後,那個快遞員依次的去取快遞,一次拿一個,然後開著車去送快遞,送好了就回來拿下一個快遞。
對比
上述兩種經營方式對比,是不是明顯覺得第二種,效率更高,更好呢。在上述比喻中:
-
每個快遞員——————>每個線程
-
每個快遞——————–>每個socket(I/O流)
-
快遞的送達地點————–>socket的不同狀態
-
客戶送快遞請求————–>來自客戶端的請求
-
小曲的經營方式————–>服務端運行的代碼
-
一輛車———————->CPU的核數
於是我們有如下結論
1、經營方式一就是傳統的並發模型,每個I/O流(快遞)都有一個新的線程(快遞員)管理。
2、經營方式二就是I/O多路復用。只有單個線程(一個快遞員),通過跟蹤每個I/O流的狀態(每個快遞的送達地點),來管理多個I/O流。
下面類比到真實的redis線程模型,如圖所示
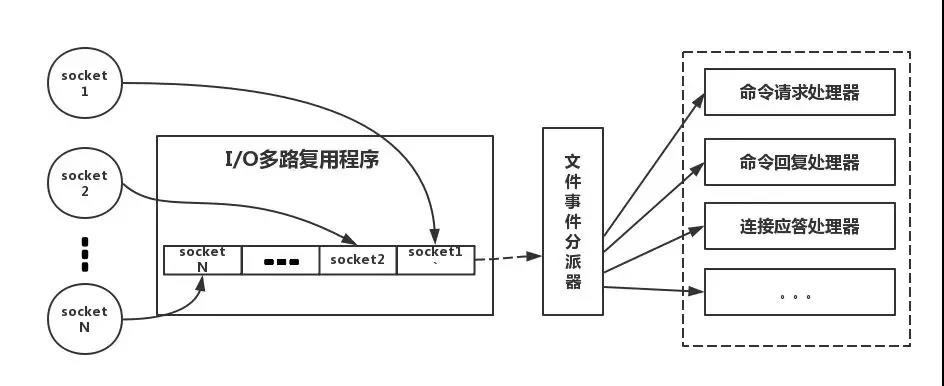
參照上圖,簡單來說,就是。我們的redis-client在操作的時候,會產生具有不同事件類型的socket。在服務端,有一段I/0多路復用程序,將其置入隊列之中。然後,文件事件分派器,依次去隊列中取,轉發到不同的事件處理器中。
需要說明的是,這個I/O多路復用機制,redis還提供了select、epoll、evport、kqueue等多路復用函數庫,大家可以自行去了解。
4、redis的數據類型,以及每種數據類型的使用場景
分析:是不是覺得這個問題很基礎,其實我也這麽覺得。然而根據面試經驗發現,至少百分八十的人答不上這個問題。建議,在項目中用到後,再類比記憶,體會更深,不要硬記。基本上,一個合格的程序員,五種類型都會用到。
回答:一共五種
(一)String
這個其實沒啥好說的,最常規的set/get操作,value可以是String也可以是數字。一般做一些復雜的計數功能的緩存。
(二)hash
這裏value存放的是結構化的對象,比較方便的就是操作其中的某個字段。博主在做單點登錄的時候,就是用這種數據結構存儲用戶信息,以cookieId作為key,設置30分鐘為緩存過期時間,能很好的模擬出類似session的效果。
(三)list
使用List的數據結構,可以做簡單的消息隊列的功能。另外還有一個就是,可以利用lrange命令,做基於redis的分頁功能,性能極佳,用戶體驗好。本人還用一個場景,很合適---取行情信息。就也是個生產者和消費者的場景。LIST可以很好的完成排隊,先進先出的原則。
(四)set
因為set堆放的是一堆不重復值的集合。所以可以做全局去重的功能。為什麽不用JVM自帶的Set進行去重?因為我們的系統一般都是集群部署,使用JVM自帶的Set,比較麻煩,難道為了一個做一個全局去重,再起一個公共服務,太麻煩了。
另外,就是利用交集、並集、差集等操作,可以計算共同喜好,全部的喜好,自己獨有的喜好等功能。
(五)sorted set
sorted set多了一個權重參數score,集合中的元素能夠按score進行排列。可以做排行榜應用,取TOP N操作。
5、redis的過期策略以及內存淘汰機制
分析:這個問題其實相當重要,到底redis有沒用到家,這個問題就可以看出來。比如你redis只能存5G數據,可是你寫了10G,那會刪5G的數據。怎麽刪的,這個問題思考過麽?還有,你的數據已經設置了過期時間,但是時間到了,內存占用率還是比較高,有思考過原因麽?
回答:
redis采用的是定期刪除+惰性刪除策略。
為什麽不用定時刪除策略?
定時刪除,用一個定時器來負責監視key,過期則自動刪除。雖然內存及時釋放,但是十分消耗CPU資源。在大並發請求下,CPU要將時間應用在處理請求,而不是刪除key,因此沒有采用這一策略.
定期刪除+惰性刪除是如何工作的呢?
定期刪除,redis默認每個100ms檢查,是否有過期的key,有過期key則刪除。需要說明的是,redis不是每個100ms將所有的key檢查一次,而是隨機抽取進行檢查(如果每隔100ms,全部key進行檢查,redis豈不是卡死)。因此,如果只采用定期刪除策略,會導致很多key到時間沒有刪除。
於是,惰性刪除派上用場。也就是說在你獲取某個key的時候,redis會檢查一下,這個key如果設置了過期時間那麽是否過期了?如果過期了此時就會刪除。
采用定期刪除+惰性刪除就沒其他問題了麽?
不是的,如果定期刪除沒刪除key。然後你也沒即時去請求key,也就是說惰性刪除也沒生效。這樣,redis的內存會越來越高。那麽就應該采用內存淘汰機制。
在redis.conf中有一行配置
# maxmemory-policy volatile-lru
該配置就是配內存淘汰策略的(什麽,你沒配過?好好反省一下自己)
1)noeviction:當內存不足以容納新寫入數據時,新寫入操作會報錯。應該沒人用吧。
2)allkeys-lru:當內存不足以容納新寫入數據時,在鍵空間中,移除最近最少使用的key。推薦使用,目前項目在用這種。
3)allkeys-random:當內存不足以容納新寫入數據時,在鍵空間中,隨機移除某個key。應該也沒人用吧,你不刪最少使用Key,去隨機刪。
4)volatile-lru:當內存不足以容納新寫入數據時,在設置了過期時間的鍵空間中,移除最近最少使用的key。這種情況一般是把redis既當緩存,又做持久化存儲的時候才用。不推薦
5)volatile-random:當內存不足以容納新寫入數據時,在設置了過期時間的鍵空間中,隨機移除某個key。依然不推薦
6)volatile-ttl:當內存不足以容納新寫入數據時,在設置了過期時間的鍵空間中,有更早過期時間的key優先移除。不推薦
ps:如果沒有設置 expire 的key, 不滿足先決條件(prerequisites); 那麽 volatile-lru, volatile-random 和 volatile-ttl 策略的行為, 和 noeviction(不刪除) 基本上一致。
6、redis和數據庫雙寫一致性問題
分析:一致性問題是分布式常見問題,還可以再分為最終一致性和強一致性。數據庫和緩存雙寫,就必然會存在不一致的問題。答這個問題,先明白一個前提。就是如果對數據有強一致性要求,不能放緩存。我們所做的一切,只能保證最終一致性。另外,我們所做的方案其實從根本上來說,只能說降低不一致發生的概率,無法完全避免。因此,有強一致性要求的數據,不能放緩存。
首先,采取正確更新策略,先更新數據庫,再刪緩存。其次,因為可能存在刪除緩存失敗的問題,提供一個補償措施即可,例如利用消息隊列。
7、如何應對緩存穿透和緩存雪崩問題
分析:這兩個問題,說句實在話,一般中小型傳統軟件企業,很難碰到這個問題。如果有大並發的項目,流量有幾百萬左右。這兩個問題一定要深刻考慮。
回答:如下所示
緩存穿透,即黑客故意去請求緩存中不存在的數據,導致所有的請求都懟到數據庫上,從而數據庫連接異常。
解決方案:
(一)利用互斥鎖,緩存失效的時候,先去獲得鎖,得到鎖了,再去請求數據庫。沒得到鎖,則休眠一段時間重試
(二)采用異步更新策略,無論key是否取到值,都直接返回。value值中維護一個緩存失效時間,緩存如果過期,異步起一個線程去讀數據庫,更新緩存。需要做緩存預熱(項目啟動前,先加載緩存)操作。
(三)提供一個能迅速判斷請求是否有效的攔截機制,比如,利用布隆過濾器,內部維護一系列合法有效的key。迅速判斷出,請求所攜帶的Key是否合法有效。如果不合法,則直接返回。
緩存雪崩,即緩存同一時間大面積的失效,這個時候又來了一波請求,結果請求都懟到數據庫上,從而導致數據庫連接異常。
解決方案:
(一)給緩存的失效時間,加上一個隨機值,避免集體失效。
(二)使用互斥鎖,但是該方案吞吐量明顯下降了。
(三)雙緩存。我們有兩個緩存,緩存A和緩存B。緩存A的失效時間為20分鐘,緩存B不設失效時間。自己做緩存預熱操作。然後細分以下幾個小點
-
I 從緩存A讀數據庫,有則直接返回
-
II A沒有數據,直接從B讀數據,直接返回,並且異步啟動一個更新線程。
-
III 更新線程同時更新緩存A和緩存B。
8、如何解決redis的並發競爭key問題
分析:這個問題大致就是,同時有多個子系統去set一個key。這個時候要註意什麽呢?大家思考過麽。需要說明一下,博主提前百度了一下,發現答案基本都是推薦用redis事務機制。博主不推薦使用redis的事務機制。因為我們的生產環境,基本都是redis集群環境,做了數據分片操作。你一個事務中有涉及到多個key操作的時候,這多個key不一定都存儲在同一個redis-server上。因此,redis的事務機制,十分雞肋。
回答:如下所示
(1)如果對這個key操作,不要求順序
這種情況下,準備一個分布式鎖,大家去搶鎖,搶到鎖就做set操作即可,比較簡單。
(2)如果對這個key操作,要求順序
假設有一個key1,系統A需要將key1設置為valueA,系統B需要將key1設置為valueB,系統C需要將key1設置為valueC.
期望按照key1的value值按照 valueA–>valueB–>valueC的順序變化。這種時候我們在數據寫入數據庫的時候,需要保存一個時間戳。假設時間戳如下
系統A key 1 {valueA 3:00}
系統B key 1 {valueB 3:05}
系統C key 1 {valueC 3:10}
那麽,假設這會系統B先搶到鎖,將key1設置為{valueB 3:05}。接下來系統A搶到鎖,發現自己的valueA的時間戳早於緩存中的時間戳,那就不做set操作了。以此類推。
其他方法,比如利用隊列,將set方法變成串行訪問也可以。總之,靈活變通
Redis 總結精講