
Perseus-BERT——業內效能極致優化的BERT訓練方案
【作者】 筍江(林立翔) 馭策(龔志剛) 蜚廉(王志明) 昀龍(遊亮)
一,背景——橫空出世的BERT全面超越人類
2018年在自然語言處理(NLP)領域最具爆炸性的一朵“蘑菇雲”莫過於Google Research提出的BERT(Bidirectional Encoder Representations from Transformers)模型。作為一種新型的語言表示模型,BERT以“摧枯拉朽”之勢橫掃包括語言問答、理解、預測等各項NLP錦標的桂冠,見圖1和圖2。
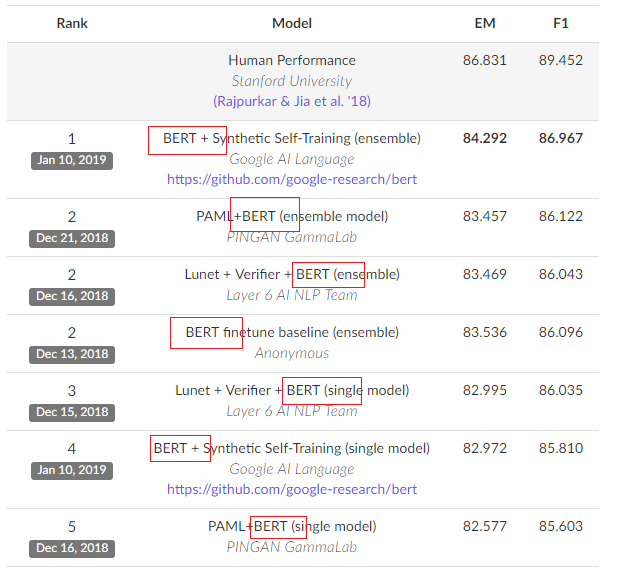
【圖1】SQuAD是基於Wikipedia文章的標準問答資料庫的NLP錦標。目前SQuAD2.0排名前十名均為基於BERT的模型(圖中列出前五名),前20名有16席均是出自BERT
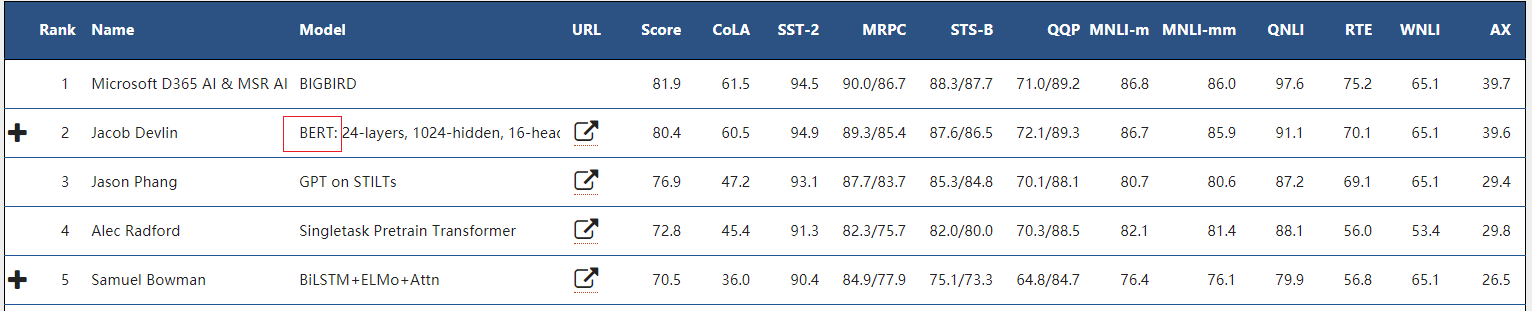
【圖2】GLUE是一項通用語言理解評估的benchmark,包含11項NLP任務。BERT自誕生日起長期壓倒性霸佔榜首(目前BERT排名第二,第一為Microsoft提交的BIGBIRD模型,由於沒有URL連結無從知曉模型細節,網傳BIGBIRD的名稱上有借鑑BERT BIG模型之嫌)
業內將BERT在自然語言處理的地位比作ResNet之於計算機視覺領域的里程碑地位。在BERT橫空出世之後,所有的自然語言處理任務都可以基於BERT模型為基礎展開。
一言以蔽之,現如今,作為NLP的研究者,如果不瞭解BERT,那就是落後的科技工作者;作為以自然語言處理為重要依託的科技公司,如果不落地BERT,那就是落後生產力的代表。
二,痛點——算力成為BERT落地的攔路虎
BERT強大的原因在哪裡?讓我們拂去雲靄,窺探下硝煙下的奧祕。
BERT模型分為預訓練模型(Pretrain)和精調模型(Finetune)。Pretrain模型為通用的語言模型。Finetune只需要在Pretrain的基礎上增加一層適配層就可以服務於從問答到語言推理等各類任務,無需為具體任務修改整體模型架構,如圖3所示。這種設計方便BERT預處理模型適配於各類具體NLP模型(類似於CV領域基於ImageNet訓練的各種Backbone模型)。
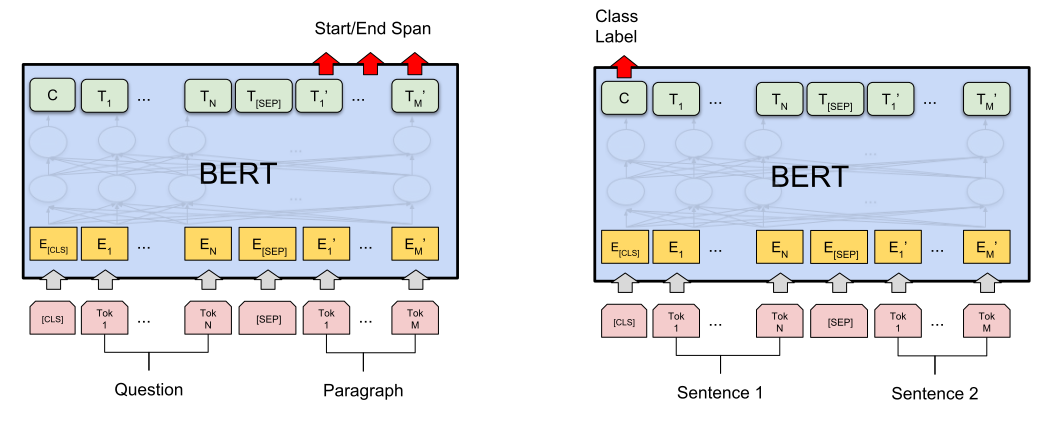
【圖3】左圖基於BERT pretrain的模型用於語句問答任務(SQuAD)的finetune模型,右圖為用於句對分類(Sentence Pair Classification Tasks)的finetune模型。他們均是在BERT Pretrain模型的基礎上增加了一層具體任務的適配層
因此,BERT的強大主要歸功於精確度和魯棒性俱佳的Pretrain語言模型。大部分的計算量也出自Pretrain模型。其主要運用了以下兩項技術,都是極其耗費計算資源的模組。
- 雙向Transformer架構
圖4可見,與其他pre-training的模型架構不同,BERT從左到右和從右到左地同時對語料進行transformer處理。這種雙向技術能充分提取語料的時域相關性,但同時也大大增加了計算資源的負擔。【關於Transformer是Google 17年在NLP上的大作,其用全Attention機制取代NLP常用的RNN及其變體LSTM等的常用架構,大大改善了NLP的預測準確度。本文不展開,該興趣的同學可以自行搜尋一下】。
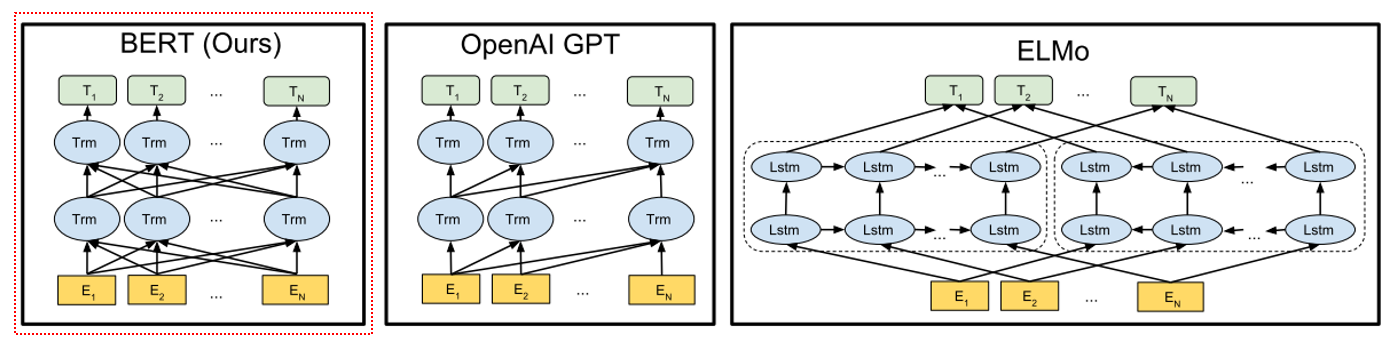
【圖4】Pretrain架構對比。其中OpenAI GPT採用從左到右的Transformer架構,ELMo採用部分從左到右和部分從右到左的LSTM的級聯方式。BERT採用同時從左到右和從右到左的雙向Transformer架構。
- 詞/句雙任務隨機預測
BERT預訓練模型在迭代計算中會同時進行單詞預測和語句預測兩項非監督預測任務。
其一,單詞預測任務對語料進行隨機MASK操作(Masked LM)。在所有語料中隨機選取15%的單詞作為Mask資料。被選中Mask的語料單詞在迭代計算過程中80%時間會被掩碼覆蓋用於預測、10%時間保持不變、10%時間隨機替換為其他單詞,如圖5所示。
其二,語句預測任務(Next Sentence Prediction)。對選中的前後句A和B,在整個迭代預測過程中,50%的時間B作為A的真實後續語句(Label=IsNext),另外50%的時間則從語料庫裡隨機選取其他語句作為A的後續語句(Label=NotNext),如圖5所示
![【圖5】詞/句雙任務隨機預測輸入語料例項。藍框和紅框為同一個語料輸入在不同時刻的隨機狀態。對單詞預測任務,藍框中的went為真實資料,到了紅框則被[MASK],紅框中的the 則相反;對於語句預測任務,藍框中的句組為真實的前後句,而紅框中的句組則為隨機的組合。](http://ata2-img.cn-hangzhou.img-pub.aliyun-inc.com/a5c711382fe42f2fce3dcc23c23e90e3.png)
【圖5】詞/句雙任務隨機預測輸入語料例項。藍框和紅框為同一個語料輸入在不同時刻的隨機狀態。對單詞預測任務,藍框中的“went”為真實資料,到了紅框則被[MASK],紅框中的“the” 則相反;對於語句預測任務,藍框中的句組為真實的前後句,而紅框中的句組則為隨機的組合。
這種隨機選取的單詞/語句預測方式在功能上實現了非監督資料的輸入的功能,有效防止模型的過擬合。但是按比例隨機選取需要大大增加對語料庫的迭代次數才能消化所有的語料資料,這給計算資源帶來了極大的壓力。
綜上,BERT預處理模型功能需要建立在極強的計算力基礎之上。BERT論文顯示,訓練BERT BASE 預訓練模型(L=12, H=768, A=12, Total Parameters=110M, 1000,000次迭代)需要1臺Cloud TPU工作16天;而作為目前深度學習主流的Nvidia GPU加速卡面對如此海量的計算量更是力不從心。即使是目前主流最強勁的Nvidia V100加速卡,訓練一個BERT-Base Pretrain模型需要一兩個月的時間。而訓練Large模型,需要花至少四五個月的時間。
花幾個月訓練一個模型,對於絕大部分在GPU上訓練BERT的使用者來說真是傷不起。
三,救星——擎天雲加速框架為BERT披荊斬棘
阿里雲彈性人工智慧團隊依託阿里雲強大的基礎設施資源打磨業內極具競爭力的人工智慧創新方案。基於BERT的訓練痛點,團隊打造了擎天優化版的Perseus-BERT, 極大地提升了BERT pretrain模型的訓練速度。在雲上一臺V100 8卡例項上,只需4天不到即可訓練一份BERT模型。
Perseus-BERT是如何打造雲上最佳的BERT訓練實踐?以下乾貨為您揭祕Perseus-BERT的獨門絕技。
1. Perseus 統一分散式通訊框架 —— 賦予BERT分散式訓練的輕功
Perseus(擎天)統一分散式通訊框架是團隊針對人工智慧雲端訓練的痛點,針對阿里雲基礎設施極致優化的分散式訓練框架。其可輕便地嵌入主流人工智慧框架的單機訓練程式碼,在保證訓練精度的同時高效地提升訓練的多機擴充套件性。擎天分散式框架的乾貨介紹詳見團隊另一篇文章《Perseus(擎天):統一深度學習分散式通訊框架》。
針對tensorflow程式碼的BERT,Perseus提供horovod的python api方便嵌入BERT預訓練程式碼。基本流程如下:
- 讓每塊GPU對應一個Perseus rank程序;
- 對global step和warmup step做基於rank數的校準;
- 對訓練資料根據rank-id做劃分;
- 給Optimizer增加DistributeOptimizer的wrapper。
值得注意的是,BERT原始碼用的自定義的Optimizer,在計算梯度時採用了以下api
grads = tf.gradients(loss, tvars)Perseus的DistributeOptimizer繼承標準的Optimizer實現,並在`compute_gradients` api 上實現分散式的梯度更新計算。因此對grads獲取做了如下微調
grads_and_vars = optimizer.compute_gradients(loss, tvars)
grads = list()
for grad, var in grads_and_vars:
grads.append(grad)
2. 混合精度訓練和XLA編譯優化——提升BERT單機效能的內功
混合精度
在深度學習中,混合精度訓練指的是float32和float16混合的訓練方式,一般的混合精度模式如圖6所示
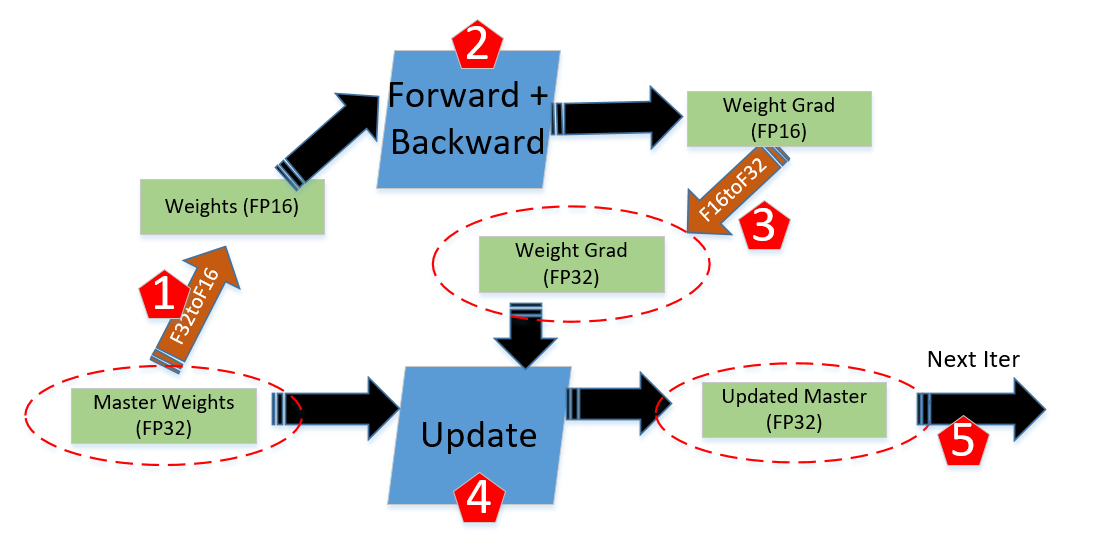
【圖6】混合精度訓練示例。在Forward+Backward計算過程中用float16做計算,在梯度更新時轉換為float32做梯度更新。
混合梯度對Bert訓練帶來如下好處,
- 增大訓練時的batch size和sequence_size以保證模型訓練的精度。
目前阿里雲上提供的主流的Nvidia顯示卡的視訊記憶體最大為16GB,對一個BERT-Base模型在float32模式只能最高設定為sequence_size=256,batch_size=26。BERT的隨機預測模型設計對sequence_size和batch_size的大小有一定要求。為保證匹配BERT的原生訓練精度,需要保證sequece_size=512的情況下batch_size不小於16。Float16的混合精度可以保證如上需求。
- 混合精度能充分利用硬體的加速資源。
NVidia從Volta架構開始增加了Tensor Core資源,這是專門做4x4矩陣乘法的fp16/fp32混合精度的ASIC加速器,一塊V100能提供125T的Tensor Core計算能力,只有在混合精度下計算才能利用上這一塊強大的算力。
受限於float16的表示精度,混合精度訓練的程式碼需要額外的編寫,NVidia提供了在Tensorflow下做混合精度訓練的教程 。其主要思路是通過tf.variable_scope的custom_getter 引數保證儲存的引數為float32並用float16做計算。
在BERT預訓練模型中,為了保證訓練的精度,Perseus-BERT沒有簡單的利用custom_getter引數,而是顯式指定訓地引數中哪些可以利用float16不會影響精度,哪些必須用float32已保證精度。我們的經驗如下:
- Embedding部分要保證float32精度;
- Attetion部分可以利用float16加速;
- Gradients相關的更新和驗證需要保證float32精度;
- 非線性啟用等模組需要保證float32精度。
XLA編譯器優化
XLA是Tensorflow新近提出的模型編譯器,其可以將Graph編譯成IR表示,Fuse冗餘Ops,並對Ops做了效能優化、適配硬體資源。然而官方的Tensorflow release並不支援xla的分散式訓練,為了保證分散式訓練可以正常進行和精度,我們自己編譯了帶有額外patch的tensorflow來支援分散式訓練,Perseus-BERT 通過啟用XLA編譯優化加速訓練過程並增加了Batch size大小。
3. 資料集預處理的加速
Perseus BERT 同時對文字預處理做的word embedding和語句劃分做了並行化的優化。這裡就不展開說明。
四,效能——計算時間單位從月降低到天
圖7展示了Perseus BERT在P100例項上的效能,與開源主流的horovod相比,Peseus-BERT雙機16卡的分散式效能是前者的5倍之多。
目前某大客戶已在阿里雲P100叢集上大規模上線了Perseus BERT,用10臺4卡P100只需要2.5天即可訓練完成業務模型,如果用開源的horovod(Tensorflow分散式效能優化版)大概需要1個月的時間。
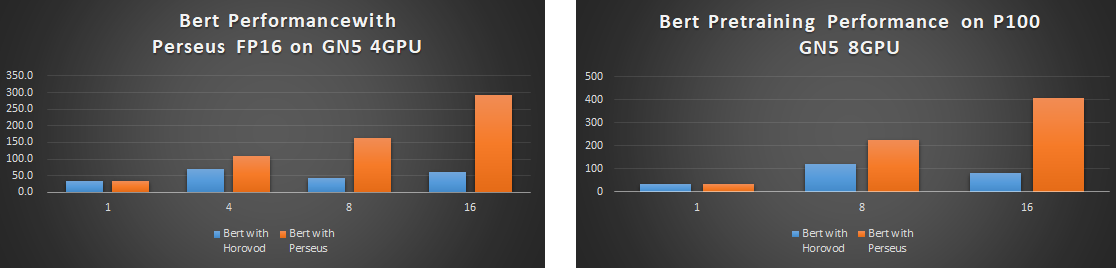
【圖7】Bert在阿里雲上P100例項的對比(實驗環境Bert on P100; Batch size: 22 ;Max seq length: 256 ;Data type:float32; Tensorflow 1.12; Perseus: 0.9.1;Horovod: 0.15.2)
為了和Google TPU做對比,我們量化了TPU的效能,效能依據如圖8。一個Cloud TPU可計算的BERT-Base效能 256 *(1000000/4/4/24/60/60) = 185 exmaples/s。 而一臺阿里雲上的V100 單機八卡例項在相同的sequence_size=512下, 通過Perseus-BERT優化的Base模型訓練可以做到 680 examples/s,接近一臺Cloud TPU的4倍效能。對一臺Cloud TPU花費16天才能訓練完的BERT模型,一臺阿里雲的V100 8卡例項只需要4天不到便可訓練完畢。

【圖8】BERT Pretain在Google Cloud TPU上的效能依據
五,總結——基於阿里雲基礎設施的AI極致效能優化
彈性人工智慧團隊一直致力基於阿里雲基礎設施的AI極致效能優化的創新方案。Perseus-BERT就是一個非常典型的案例,我們在框架層面上基於阿里雲的基礎設施做深度優化,充分釋放阿里雲上基礎資源的計算能力,讓阿里雲的客戶充分享受雲上的AI計算優勢,讓天下沒有難算的AI。
原文連結
本文為雲棲社群原創內容,未經