
Spark in action on Kubernetes
前言
Spark是非常流行的大資料處理引擎,資料科學家們使用Spark以及相關生態的大資料套件完成了大量又豐富場景的資料分析與挖掘。Spark目前已經逐漸成為了業界在資料處理領域的行業標準。但是Spark本身的設計更偏向使用靜態的資源管理,雖然Spark也支援了類似Yarn等動態的資源管理器,但是這些資源管理並不是面向動態的雲基礎設施而設計的,在速度、成本、效率等領域缺乏解決方案。隨著Kubernetes的快速發展,資料科學家們開始考慮是否可以用Kubernetes的彈性與面向雲原生等特點與Spark進行結合。在Spark 2.3中,Resource Manager中添加了Kubernetes原生的支援,而本系列我們會給大家介紹如何用更Kubernetes的方式在叢集中使用Spark進行資料分析。本系列不需要開發者有豐富的Spark使用經驗,對著系列的逐漸深入,會穿插講解使用到的Spark特性。
搭建Playground
很多的開發者在接觸Hadoop的時候,被安裝流程的複雜度打消了很多的積極性。為了降低學習的門檻,本系列會通過spark-on-k8s-operator作為Playground,簡化大家的安裝流程。spark-on-k8s-operator顧名思義是為了簡化Spark操作而開發的operator,如果對operator不是很瞭解的開發者,可以先自行搜尋瞭解下,理解operator能做什麼可以快速幫你掌握spark-on-k8s-operator的要領。
在講解內部原理前,我們先將環境搭建起來,通過一個簡單的demo,跑通整個的執行時環境。
1. 安裝spark-on-k8s-operator
官方的文件是通過Helm Chart進行安裝的,由於很多開發者的環境無法連通google的repo,因此此處我們通過標準的yaml進行安裝。
## 下載repo git clone [email protected]:AliyunContainerService/spark-on-k8s-operator.git ## 安裝crd kubectl apply -f manifest/spark-operator-crds.yaml ## 安裝operator的服務賬號與授權策略 kubectl apply -f manifest/spark-operator-rbac.yaml ## 安裝spark任務的服務賬號與授權策略 kubectl apply -f manifest/spark-rbac.yaml ## 安裝spark-on-k8s-operator kubectl apply -f manifest/spark-operator.yaml
驗證安裝結果
此時在spark-operator的名稱空間下的無狀態應用下,可以看到一個執行中的sparkoperator,表名此時元件已經安裝成功,接下來我們執行一個demo應用來驗證元件是否可以正常工作。
2. Demo驗證
學習Spark的時候,我們執行的第一個任務是官方文件中介紹的圓周率執行的例子。今天我們換一種方式,通過Kubernetes的方式再執行一次。
## 下發spark-pi任務
kubectl apply -f examples/spark-pi.yaml 任務下發成功後,可以通過命令列觀察任務的狀態。
## 查詢任務
kubectl describe sparkapplication spark-pi
## 任務結果
Name: spark-pi
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"sparkoperator.k8s.io/v1alpha1","kind":"SparkApplication","metadata":{"annotations":{},"name":"spark-pi","namespace":"defaul...
API Version: sparkoperator.k8s.io/v1alpha1
Kind: SparkApplication
Metadata:
Creation Timestamp: 2019-01-20T10:47:08Z
Generation: 1
Resource Version: 4923532
Self Link: /apis/sparkoperator.k8s.io/v1alpha1/namespaces/default/sparkapplications/spark-pi
UID: bbe7445c-1ca0-11e9-9ad4-062fd7c19a7b
Spec:
Deps:
Driver:
Core Limit: 200m
Cores: 0.1
Labels:
Version: 2.4.0
Memory: 512m
Service Account: spark
Volume Mounts:
Mount Path: /tmp
Name: test-volume
Executor:
Cores: 1
Instances: 1
Labels:
Version: 2.4.0
Memory: 512m
Volume Mounts:
Mount Path: /tmp
Name: test-volume
Image: gcr.io/spark-operator/spark:v2.4.0
Image Pull Policy: Always
Main Application File: local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar
Main Class: org.apache.spark.examples.SparkPi
Mode: cluster
Restart Policy:
Type: Never
Type: Scala
Volumes:
Host Path:
Path: /tmp
Type: Directory
Name: test-volume
Status:
Application State:
Error Message:
State: COMPLETED
Driver Info:
Pod Name: spark-pi-driver
Web UI Port: 31182
Web UI Service Name: spark-pi-ui-svc
Execution Attempts: 1
Executor State:
Spark - Pi - 1547981232122 - Exec - 1: COMPLETED
Last Submission Attempt Time: 2019-01-20T10:47:14Z
Spark Application Id: spark-application-1547981285779
Submission Attempts: 1
Termination Time: 2019-01-20T10:48:56Z
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SparkApplicationAdded 55m spark-operator SparkApplication spark-pi was added, Enqueuing it for submission
Normal SparkApplicationSubmitted 55m spark-operator SparkApplication spark-pi was submitted successfully
Normal SparkDriverPending 55m (x2 over 55m) spark-operator Driver spark-pi-driver is pending
Normal SparkExecutorPending 54m (x3 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is pending
Normal SparkExecutorRunning 53m (x4 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is running
Normal SparkDriverRunning 53m (x12 over 55m) spark-operator Driver spark-pi-driver is running
Normal SparkExecutorCompleted 53m (x2 over 53m) spark-operator Executor spark-pi-1547981232122-exec-1 completed此時我們發現任務已經執行成功,檢視這個Pod的日誌,我們可以到計算最終的結果為Pi is roughly 3.1470557352786765。至此,在Kubernetes上,已經跑通了第一個Job,接下來我們要來詳解一下剛才這一波操作到底都做了些什麼。
Spark Operator的基礎架構淺析
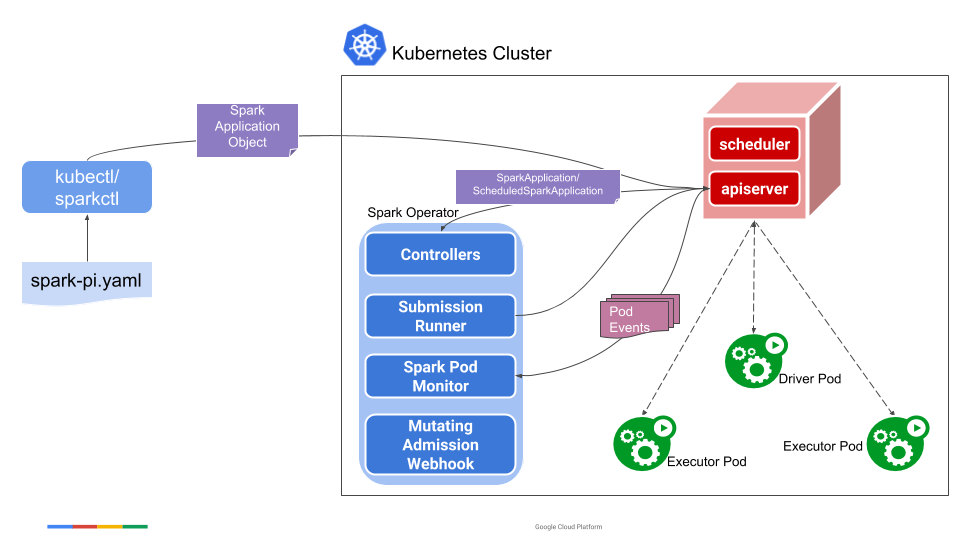
這張圖是Spark Operator的流程圖,在上面的操作中,第一個步驟裡面,實際上是將圖中的中心位置藍色的Spark Operator安裝到叢集中,Spark Opeartor本身即是是一個CRD的Controller也是一個Mutating Admission Webhook的Controller。當我們下發spark-pi模板的時候,會轉換為一個名叫SparkApplication的CRD物件,然後Spark Operator會監聽Apiserver,並將SparkApplication物件進行解析,變成spark-submit的命令並進行提交,提交後會生成Driver Pod,用簡單的方式理解,Driver Pod就是一個封裝了Spark Jar的映象。如果是本地任務,就直接在Driver Pod中執行;如果是叢集任務,就會通過Driver Pod再生成Exector Pod進行執行。當任務結束後,可以通過Driver Pod進行執行日誌的檢視。此外在任務的執行中,Spark Operator還會動態attach一個Spark UI到Driver Pod上,希望檢視任務狀態的開發者,可以通過這個UI頁面進行任務狀態的檢視。
最後
在本文中,我們討論了Spark Operator的設計初衷,如何快速搭建一個Spark Operator的Playground以及Spark Operator的基本架構與流程。在下一篇文章中,我們會深入到Spark Operator的內部,為大家講解其內部的實現原理以及如何與Spark更無縫的整合。
前言
Spark是非常流行的大資料處理引擎,資料科學家們使用Spark以及相關 傳統的應用都是“monoliths”,意思就是大應用,即所有邏輯和模組都耦合在一起的
這樣明顯很挺多問題的,比如只能scale up,升級必須整體升級,擴容
所以我們就想把大應用,broken down成小,獨立的模組或元件,這樣元件可以獨立的升級,擴容,元件也可以用不同的語言實現,元件間通過協議通訊,每 Volume解決Kubernetes的儲存的問題
對於Pod使用的儲存,抽象為volume,volume伴隨著Pod的建立而建立,消失而同時消失,不能單獨的建立
這樣的好處,是儲存的塑膠不會因為某個container重啟而丟失,因為volume是pod級別的
還有好處是,volume是pod資源,所以所 # 1 Kubernetes介紹
Kubernetes(以下簡稱K8s) 是一個部署和管理容器化應用的軟體系統。它將底層基礎設施抽象,簡化了應用的開發、部署,以及對開發和運維團隊的管理。
NIO(non-blocking IO,New IO), OIO(Old IO,blocking IO), Local(本地), turn fma 全部 pytho label -c log eps 數組 一.numpy()函數
1.shape[]讀取矩陣的長度
例:
import numpy as np
x = np.array([[1,2],[2,3],[3,4]])
print x round 思維 add -s size 分析 文本 cti 建立索引
文件夾
Part 1 初識 SOLR
1 Solr 簡單介紹
2 開始熟悉 Solr
3 Solr 核心概念
4 配置 Solr
5 建立索 包括 exec 我會 nco 程序 bool action list() 對比 對OOP編程人員來說,泛函狀態State是一種全新的數據類型。我們在上節做了些介紹,在這節我們討論一下State類型的應用:用一個具體的例子來示範如何使用State類型。以下是這個例子的 implement efi 事務隔離 簡單 視圖 適合 組成 .html bool
第一章
1.Spring採用4種策略減少Java開發復雜度
基於POJO的輕量級和最小侵入性編程
依賴註入和面向接口實現松耦合
基於切面和慣例進行聲明式編程
通過切面和模板降低樣板式 options 直升機 water 飛機 math mes 視頻 write mod
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = count rom sha group .get name imp diff mac 使用K-近鄰算法將某點[0.6, 0.6]劃分到某個類(A, B)中。
from numpy import *
import operator
def classify0(inX, 以及 span spa rar clas start 數據分析工具 blog 有效 R in action -- 第1章 R語言介紹
R:一個數據分析和圖形顯示的程序設計環境
R 環境
R 環境由一組數據操作,計算和圖形展示的工具構成。相對其他同類軟件,它的 特色在於:
ram style 處理 cells bsp 創建 通過 不同 div R in action -- 2.1 數據結構
1、R中用來存儲數據的結構:標量、向量、數組、數據框、列表。
2、R中可以處理的數據類型:數值、字符、邏輯、復數、原生(字節)。
3、向量:
向量是用來 ref cpp people 2.3 excel com 導入 data 輸入 R in action -- 2.3 數據輸入
1、從CSV文件導入數據
> gtades <- read.table("1.csv",header=TRUE,sep=",")
& .com aid nco 數據 參數 ttr stl exp http 因為回答百度知道的一個問題,仔細查看了《Struts2 In Action》,深入細致的看了 “數據轉移OGNL 和 構建視圖-標簽”,很多東西才恍然大悟。
一直覺得國外寫的書 php 報錯 php-fpm 從一臺服務器上拷貝php-fpm程序到另一臺後啟動提示錯誤:/etc/init.d/php-fpm-5.4 start
Starting php-fpm [27-Jul-2017 11:31:39] NOTICE: PHP message: PHP Warning: 進入 一起 table return 問題 匹配 核心 before cti 切面能幫助我們模塊化橫切關註點。簡而言之,橫切關註點可以被描述為影響應用多處的功能。例如,安全就是一個橫切關註點,應用中的許多方法都會涉及到安全規則。圖4.1直觀呈現了橫切關註點的概念。
交互式 就是 point 站點 -c 系統默認 而且 正在 expose 安裝Docker for Windows https://store.docker.com/editions/community/docker-ce-desktop-windows
要想將一個ASP 服務器 編程思想 href 地產 完全 負載 server 後臺 tsa 《Elixir in Action》是由Manning所出版的一本新書,本書為讀者介紹了Elixir這門語言以及Erlang虛擬機,同時也討論了與並發編程、容錯以及與高可用性相關的話題。InfoQ有幸 pla data prot template ack bin 通過 final span
源代碼鏈接:http://download.csdn.net/download/poiuy1991719/10117665
本代碼是基於數據庫表的操作,所以請先建立數據庫表
1 相關推薦
Spark in action on Kubernetes
kubernetes in action - Overview
kubernetes in action - Volumes
讀書筆記 | Kubernetes in Action
Netty In Action中文版 - 第四章:Transports(傳輸)
Machine Learning in Action-chapter2-k近鄰算法
自譯Solr in action中文版
泛函編程(17)-泛函狀態-State In Action
Spring In Action讀書筆記
<Machine Learning in Action >之二 樸素貝葉斯 C#實現文章分類
Machine Learn in Action(K-近鄰算法)
R in action -- 第1章
R in action -- 2.1 數據結構
R in action -- 2.3 數據輸入
Struts2 In Action筆記_頁面到動作的數據流入和流出
php-fpm啟動報錯:libgearman.so.8: No such file or directory in Unknown on line 0
Spring aop學習整理(spring in action)(一):了解AOP
NET Core 2.0 in Docker on Windows Containers
《Elixir in Action》書評及作者問答錄(作者 Sergio De Simone ,譯者 邵思華 發布於 2015年9月29日)
Spring4 In Action-5.2.3-Spring Web應用程序-向頁面輸出列表、接收參數、接收表單