
Python中關於列表嵌套列表的處理
阿新 • • 發佈:2019-02-28
lol mov frame 向上 分享圖片 嵌套列表 end size val
在處理列表的時候我們經常會遇到列表中嵌套列表的結構,如果我們要把所有元素放入一個新列表,或者要計算所有元素的個數的話應該怎麽做呢?
第一個例子
對於上圖中的這樣一組數據,如果我們要知道這個CSV文件中所有演員的數量(同一個人只能出現一次)應該怎麽做呢?
在pandas中我們可以先取Actors這一列,但是取出來之後我們會發現這是一個列表中嵌套列表的結構,要想將所有元素提取出來我們可以使用兩個for循環來解決這一問題。代碼如下:
# encoding = utf-8 import pandas as pd file_path = "d:/learning/pandas/IMDB-Movie-Data.csv" df = pd.read_csv(file_path) print(df.head(1)) # 讀平均評分 print(df["Rating"].mean()) # 導演的人數(下面兩個操作達到的效果是一樣的) print(len(set(df["Director"].tolist()))) print(len(df["Director"].unique())) # 獲取演員的人數 temp_list = df["Actors"].str.split(", ").tolist() # 將列表套列表轉為單列表 actors_list = [i for j in temp_list for i in j] # set函數是對列表作集合操作,可以去重 print(len(set(actors_list)))
第二個例子
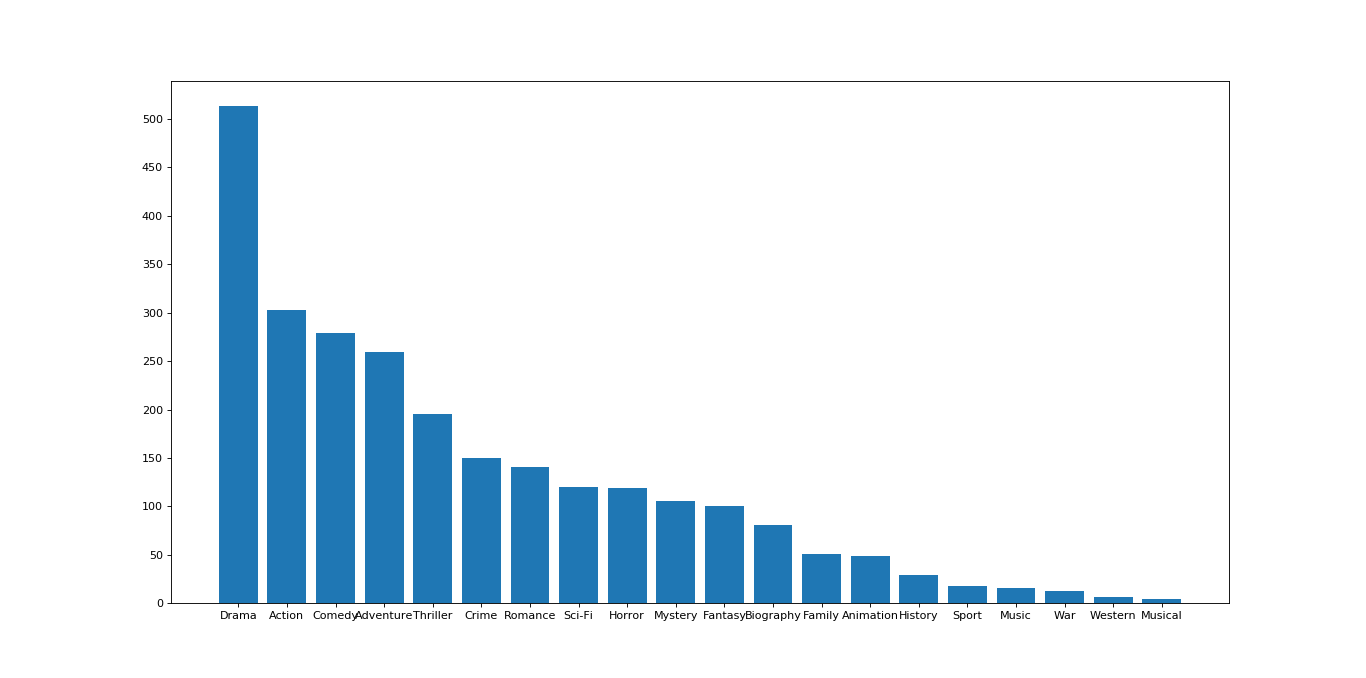
我們再來看第二組例子,還是上圖中的數據,如果我們想要統計各個分類的電影的數量,應該怎麽做呢?核心思想是:
- 先處理列表嵌套列表,將所有的分類統計出來;
- 建立一個值全為0的數組,這個數組的行數等於電影數,列數等於分類數;
- 在這個數組的列方向上進行求和,得出結果。
# coding=utf-8 import pandas as pd import numpy as np from matplotlib import pyplot as plt file_path = "~/桌面/IMDB-Movie-Data.csv" df = pd.read_csv(file_path) # 新建臨時列表,將數組中分類列讀取 temp_list = df["Genre"].str.split(",").tolist() # 處理列表嵌套列表的結構,去除重復元素 Genre_list = set([i for j in temp_list for i in j]) # 新建一個統計數組,即上文所說的第二步 a = pd.DataFrame(np.zeros((df.shape[0], len(Genre_list))), columns=Genre_list, dtype=int) # 賦值,將上述列表中對應的位置的值變為1 for i in range(len(temp_list)): a.loc[i, temp_list[i]] = 1 # 求和,統計每個分類的電影的數量 sum = a.sum(axis=0) sum = sum.sort_values(ascending=False) # 繪制條形統計圖 _x = sum.index _y = sum.values plt.figure(figsize=(20, 8), dpi=80) plt.yticks(range(max(sum.values)+50)[::50]) plt.bar(_x, _y) plt.show()
結果如圖:
這裏有一個重要的問題,如果原始數據的行數特別多,再采用for循環進行行遍歷就會耗費特別長的時間
Python中關於列表嵌套列表的處理