
在Transformer中加入相對位置信息
目錄
- 引言
- 動機
- 解決方案
- 概覽
- 註釋
- 實現
- 高效實現
- 結果
- 結論
- 參考文獻
本文翻譯自How Self-Attention with Relative Position Representations works, 介紹 Google的研究成果。
引言
? 本文基於Shaw 等人發表的論文 《Self-Attention with Relative Position Representations》 展開。論文介紹了一種在一個Transformer內部編碼輸入序列的位置信息的方法。特別的是,論文改進了Tranformer的自註意力機制,讓其能夠更有效地將序列中的詞之間的相對距離考慮進來。
? 本文旨在用易於理解的語言解釋論文中的要點。讀懂本文的前提是對 Recurrent Neural Networks(RNNs) 和Transformers 中的多頭註意力機制(multi-head self-attention mechanism)有基本的了解。
動機
? 利用隱狀態hidden state,RNN能夠讓模型隱式地編碼序列的順序信息。例如,下圖展示了RNN輸出輸入序列“I think therefore I am” 中每一個詞的向量表示。
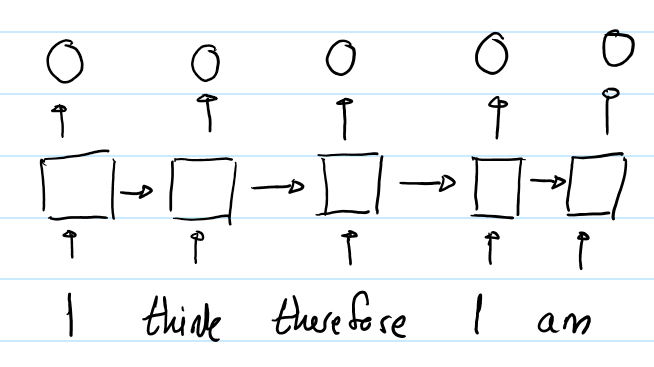
? 第二個“I”的輸出不同於第一個“I”的輸出,因為他們隱狀態的輸入是不一樣的。對第二個“I”而言,隱狀態經過了 “I think therefore”三個詞,而第一個“I” 的隱狀態僅是一個初始值。因此,RNN的隱狀態保證了在不同位置上的相同的詞會有不同的輸出向量表示。
? 相比之下,Transformer的自註意力層(不帶位置表示)對不同位置出現的相同詞給出的是同樣的輸出向量表示。例如:
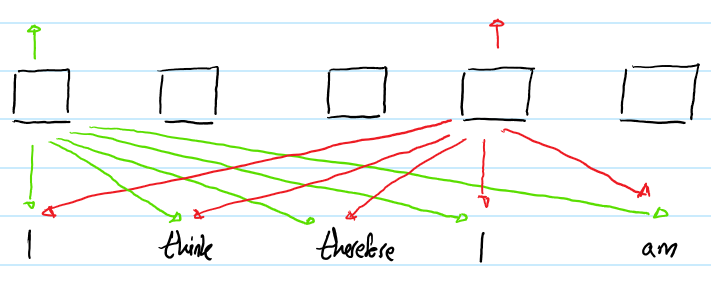
? 上圖展示了輸入序列“I think therefore I am”送入Transformer的過程。 為了方便閱讀,僅僅畫出兩個“I”的輸出。註意,盡管兩個“I”在不同輸入序列的不同位置上,他們對應的輸出向量表示還是相同的。
解決方案
概覽
? 作者提出的方法是,在Transformer中加入一組可訓練的嵌入表示,從而讓輸出帶有一定的順序信息。這一嵌入表示在計算第i個詞和第j個詞之間的註意力權重和註意力值的時候會用到。他們代表了第i個詞和第j個詞之間的距離(間隔多少個詞),因此將這種方法稱為相對位置表示(RPR)。
? 例如,一個句子由五個詞,一共會有9個嵌入表示需要學習(一個是當前詞的嵌入,有4個是上文4個詞的嵌入,4個是下文4個詞的嵌入。譯者註:k=4)。9個嵌入如下所示:

下圖清晰地展示了如何使用這些嵌入:
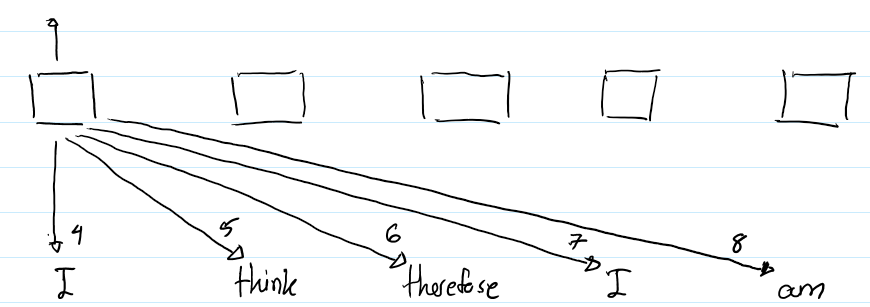
? 上圖描繪了第一個“I”的輸出表示的計算過程。箭頭旁的數字表示在計算註意力的時候使用的是哪一種相對位置表示。例如,當Transformer正在計算“I”和“therefore”之間的註意力時,它會利用包含在第6個RPR中的信息,因為“therefore” 是第一個“I”右邊的第2個詞。(譯者註:因為k設置為4,因此詞i到詞i的距離對應index4,詞i到詞i+1的距離對應index5,詞i到詞i+2的距離對應index6,以此類推)
? 下圖描繪了第二個“I”的輸出表示的計算過程。
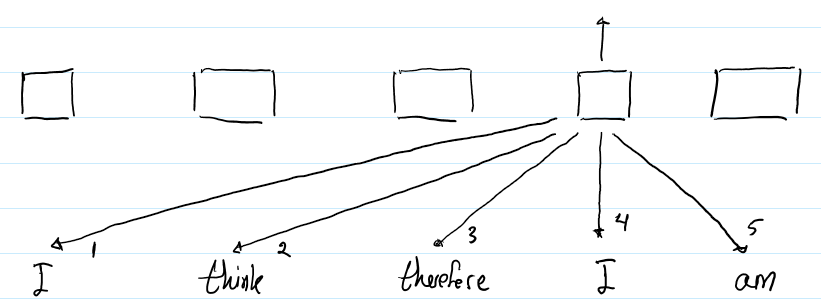
? 但是,每個詞的RPR又是不一樣的。例如,第3個RPR是用來計算 “I”和“therefore” 之間的註意力的,因為“therefore”是第二個“I”的左邊的第一個詞。這就是RPR幫助Transformer編碼輸入序列的順序信息。
註釋
? 下面的符號註釋在本文後面的闡述中會用到。

? 註意,這其中共有兩組RPR嵌入需要學習:一個用於計算詞i的輸出表示z?,另一個用於計算詞i到詞j的權重系數e??。不同於投影矩陣,這些嵌入在註意力頭間是共享的。
? 另一個值得註意的關鍵點是,需要考慮的詞間距離的最大值被限制在一個常數k。這意味著,需要學習的RPR嵌入的數量是2k+1(上文k個詞,下文k個詞以及當前詞)。向右間隔詞i超過k個詞的詞對應第2k個RPR, 向左間隔詞i超過k個詞的詞對應第0個RPR。例如,一個有10個詞的輸入序列,k設為3,那麽RPR嵌入的lookup表如下:
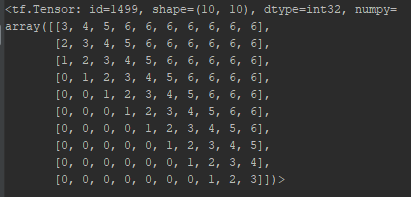
? 按照這種設計,行i對應第i個詞,列j代表第j個詞。索引號3對應第i個詞,索引號6對應第i個詞右邊第3個以及更右的詞,索引號0對應第i個詞左邊第3個以及更左的詞。第1個詞(第1行)的嵌入表示的通過查表可得。註意,從第i個詞右邊第3個詞起的所有詞的索引號都是6。這意味著即使輸入序列的第一個詞和最後一個詞之間的距離是9,最後一個詞使用的RPR嵌入也與右邊第3個詞的RPR嵌入相同。
? 這麽設計有兩個原因:
- 作者假定在一定距離之外,再精確的相對位置信息也是沒有用的。
- 限制住最長距離能夠提升模型對未在訓練階段出現過的長度的序列的泛化能力。
實現
? 下面的等式展示了在沒有使用RPR嵌入的情況下,計算 z? 的過程:

引入RPR嵌入後的式子 (1)變成了:
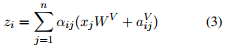
式子 (2)變成了 :
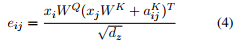
? 總而言之,式子3是當要計算詞i的輸出表示時,我們對相對詞j的value向量的權重的計算進行了改進,方法就是將相對於詞j的value向量加上詞i和詞j之間的RPR嵌入。同理,式子4告訴我們,如何改進詞i和詞j之間的縮放的點積操作,就是通過將相對於詞j的key向量加上詞i和詞j之間的RPR嵌入。根據作者的描述,使用加法作為一種將RPR嵌入整合進來的方法讓算法實現更高效,本文後面會繼續介紹。
高效實現
? Transformer的輸入是一個大小為 (batch_size, seq_length, embedding_dim)的張量。在不帶RPR嵌入的情況下,Transformer能夠利用batch_size * h 並行地進行矩陣乘法來計算 e?? (式子2) 。每一次矩陣乘法都會計算給定輸入序列和註意力頭中所有的元素的e?? 。這個過程使用下面的表達式實現的:
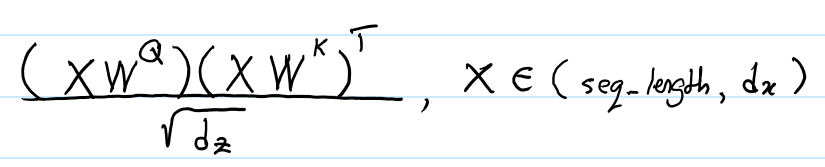
X是給定輸入序列中所有元素按行拼接起來的矩陣。
為了在加入了RPR嵌入之後也能有相近的計算效率(時間上和空間上),我們首先使用了矩陣乘法的性質將式子(4)重寫為:
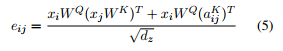
分子的左半部分和式子 (2)相同,因此在矩陣乘法中能夠高效運算。右半部分就有點技巧性了。這部分代碼實現定義在函數 relative_attention_inner 中,因此我會較簡單地把大體邏輯介紹一下。
- 分子左半部分的大小為 (batch_size, h, seq_length, seq_length)。這個張量的行i列j上的元素代表了詞i的query向量和詞j的key向量的點積的結果 。因此,我們的目標是產生另一個和這個張量大小相同的張量,而這個張量的各個元素應該是詞i的query向量和詞i與詞j之間的RPR嵌入的點積的結果(譯者註:也就是分子右半部分)。
- 首先,我們使用查表的形式為一個給定的輸入序列生成RPR嵌入張量A,A的形狀是(seq_length, seq_length, d?)。然後,我們對A進行轉置,使它的形狀變成 (seq_length, d? , seq_length) ,寫成 A?。
- 接下來,我們計算輸入序列所有元素的query向量,得到一個 (batch_size, h, seq_length, dz)形狀的張量。然後對其進行轉置,形狀變為 (seq_length, batch_size, h, dz) ,然後變形為 (seq_length, batch_size * h, dz)的張量。這個張量現在就能與 A?相乘了。這個乘法可以視為矩陣 (batch_size * h, dz) 和矩陣 (d?, seq_length)的乘法。基本上就是計算每個位置的query向量和對應的RPR嵌入的點積。
- 上面的乘法得到一個形狀為 (seq_length, batch_size * h, seq_length)的張量。我們只需要將其變形為(seq_length, batch_size, h, seq_length)的形狀,然後再轉置得到形狀為 (batch_size, h, seq_length, seq_length) 的張量,這樣我們就能將它和分子左半部分進行相加了。
同樣的邏輯也用在式子 (3)的計算中。
結果
? 作者在與Vaswani 等人發表的論文《Attention is All You Need》 中相同的機器翻譯任務上評價他的改進方法的對翻譯效果的影響。盡管每秒鐘的訓練步數下降了7個百分點,其模型在英譯德任務上的BLEU還是提高了1.3,在英譯法上提高了0.5。
結論
? 在本文中,筆者解釋了為什麽Transformer中的自註意力機制無法編碼輸入序列的位置信息,以及Shaw 等人相對位置表示嵌入(RPR)如何解決這一問題。筆者希望本文能幫助你更好的理解Shaw的文章。
參考文獻
Self-Attention with Relative Position Representations; Shaw et al. 2018.
Attention Is All You Need; Vaswani et al., 2017.
Transformer: A Novel Neural Network Architecture for Language Understanding; Uszkoreit. 2017
The Unreasonable Effectiveness of Recurrent Neural Networks; Karpathy. 2015.
在Transformer中加入相對位置信息