
Nvidia GPU如何在Kubernetes 裡工作

本文介紹Nvidia GPU裝置如何在Kubernetes中管理排程。 整個工作流程分為以下兩個方面:
- 如何在容器中使用GPU
- Kubernetes 如何排程GPU
如何在容器中使用GPU
想要在容器中的應用可以操作GPU, 需要實兩個目標
- 容器中可以檢視GPU裝置
- 容器中執行的應用,可以通過Nvidia驅動操作GPU顯示卡
詳細介紹可見: https://devblogs.nvidia.com/gpu-containers-runtime/
Nvidia-docker
GitHub: https://github.com/NVIDIA/nvidia-docker
Nvidia提供Nvidia-docker專案,它是通過修改Docker的Runtime為nvidia runtime工作,當我們執行 nvidia-docker create 或者 nvidia-docker run 時,它會預設加上 --runtime=nvidia
當然,為了方便使用,可以直接修改Docker daemon 的啟動引數,修改預設的 Runtime為
nvidia-container-runtime
cat /etc/docker/daemon.json { "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } }
gpu-containers-runtime
GitHub: https://github.com/NVIDIA/nvidia-container-runtime
gpu-containers-runtime 是一個NVIDIA維護的容器 Runtime,它在runc的基礎上,維護了一份 Patch, 我們可以看到這個patch的內容非常簡單, 唯一做的一件事情就是在容器啟動前,注入一個 prestart 的hook 到容器的Spec中(hook的定義可以檢視 OCI規範 )。這個hook 的執行時機是在容器啟動後(Namespace已建立完成),容器自定義命令(Entrypoint)啟動前。nvidia-containers-runtime 定義的 prestart 的命令很簡單,只有一句 nvidia-container-runtime-hook prestart
gpu-containers-runtime-hook
GitHub: https://github.com/NVIDIA/nvidia-container-runtime/tree/master/hook/nvidia-container-runtime-hook
gpu-containers-runtime-hook 是一個簡單的二進位制包,定義在Nvidia container runtime的hook中執行。 目的是將當前容器中的資訊收集並處理,轉換為引數呼叫 nvidia-container-cli 。
主要處理以下引數:
- 根據環境變數
NVIDIA_VISIBLE_DEVICES判斷是否會分配GPU裝置,以及掛載的裝置ID。如果是未指定或者是void,則認為是非GPU容器,不做任何處理。 否則呼叫nvidia-container-cli, GPU裝置作為--devices引數傳入 - 環境環境變數
NVIDIA_DRIVER_CAPABILITIES判斷容器需要被對映的 Nvidia 驅動庫。 - 環境變數
NVIDIA_REQUIRE_*判斷GPU的約束條件。 例如cuda>=9.0等。 作為--require=引數傳入 - 傳入容器程序的Pid
gpu-containers-runtime-hook 做的事情,就是將必要的資訊整理為引數,傳給 nvidia-container-cli configure 並執行。
nvidia-container-cli
nvidia-container-cli 是一個命令列工具,用於配置Linux容器對GPU 硬體的使用。支援
- list: 列印 nvidia 驅動庫及路徑
- info: 列印所有Nvidia GPU裝置
- configure: 進入給定程序的名稱空間,執行必要操作保證容器內可以使用被指定的GPU以及對應能力(指定 Nvidia 驅動庫)。 configure是我們使用到的主要命令,它將Nvidia 驅動庫的so檔案 和 GPU裝置資訊, 通過檔案掛載的方式對映到容器中。
程式碼如下: https://github.com/NVIDIA/libnvidia-container/blob/master/src/cli/configure.c#L272
/* Mount the driver and visible devices. */
if (perm_set_capabilities(&err, CAP_EFFECTIVE, ecaps[NVC_MOUNT], ecaps_size(NVC_MOUNT)) < 0) {
warnx("permission error: %s", err.msg);
goto fail;
}
if (nvc_driver_mount(nvc, cnt, drv) < 0) {
warnx("mount error: %s", nvc_error(nvc));
goto fail;
}
for (size_t i = 0; i < dev->ngpus; ++i) {
if (gpus[i] != NULL && nvc_device_mount(nvc, cnt, gpus[i]) < 0) {
warnx("mount error: %s", nvc_error(nvc));
goto fail;
}
}
如果對其他模組感興趣,可以在 https://github.com/NVIDIA/libnvidia-container 閱讀程式碼。
以上就是一個nvidia-docker的容器啟動的所有步驟。
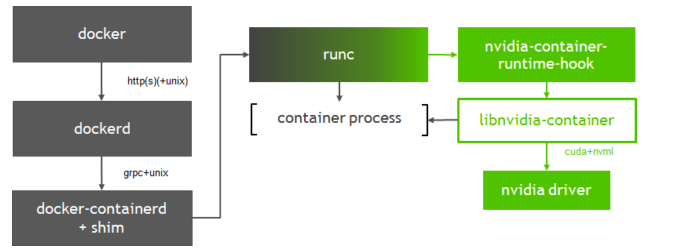
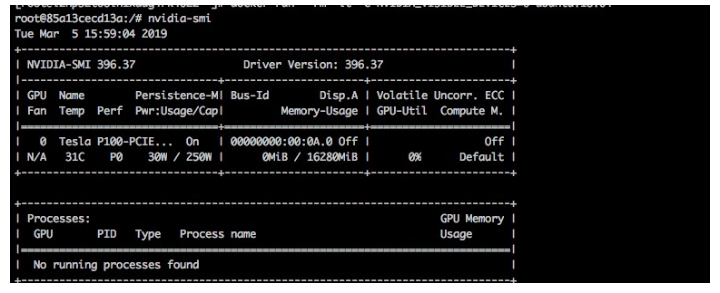
當我們安裝了nvidia-docker, 我們可以通過以下方式啟動容器
docker run --rm -it -e NVIDIA_VISIBLE_DEVICES=all ubuntu:18.04在容器中執行 mount 命令,可以看到名為 libnvidia-xxx.so 和 /proc/driver/nvidia/gpus/xxx 對映到容器中。 以及 nvidia-smi 和 nvidia-debugdump 等nvidia工具。
# mount
## ....
/dev/vda1 on /usr/bin/nvidia-smi type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-debugdump type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-persistenced type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-cuda-mps-control type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/bin/nvidia-cuda-mps-server type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-cfg.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libcuda.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-opencl.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-ptxjitcompiler.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-fatbinaryloader.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
/dev/vda1 on /usr/lib/x86_64-linux-gnu/libnvidia-compiler.so.396.37 type ext4 (ro,nosuid,nodev,relatime,data=ordered)
devtmpfs on /dev/nvidiactl type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
devtmpfs on /dev/nvidia-uvm type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
devtmpfs on /dev/nvidia-uvm-tools type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
devtmpfs on /dev/nvidia4 type devtmpfs (ro,nosuid,noexec,relatime,size=247574324k,nr_inodes=61893581,mode=755)
proc on /proc/driver/nvidia/gpus/0000:00:0e.0 type proc (ro,nosuid,nodev,noexec,relatime)我們可以執行nvidia-smi檢視容器中被對映的GPU卡
Kubernetes 如何排程GPU
之前我們介紹瞭如何在容器中使用Nvidia GPU卡。 那麼當一個叢集中有成百上千個節點以及GPU卡,我們的問題變成了如何管理和排程這些GPU。
Device plugin
Kubernetes 提供了Device Plugin 的機制,用於異構裝置的管理場景。原理是會為每個特殊節點上啟動一個針對某個裝置的DevicePlugin pod, 這個pod需要啟動grpc服務, 給kubelet提供一系列介面。
type DevicePluginClient interface {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
GetDevicePluginOptions(ctx context.Context, in *Empty, opts ...grpc.CallOption) (*DevicePluginOptions, error)
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disapears, ListAndWatch
// returns the new list
ListAndWatch(ctx context.Context, in *Empty, opts ...grpc.CallOption) (DevicePlugin_ListAndWatchClient, error)
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
Allocate(ctx context.Context, in *AllocateRequest, opts ...grpc.CallOption) (*AllocateResponse, error)
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as reseting the device before making devices available to the container
PreStartContainer(ctx context.Context, in *PreStartContainerRequest, opts ...grpc.CallOption) (*PreStartContainerResponse, error)
}DevicePlugin 註冊一個 socket 檔案到 /var/lib/kubelet/device-plugins/ 目錄下,kubelet 通過這個目錄下的socket檔案向對應的 Device plugin 傳送grpc請求。
本文不過多介紹Device Plugin 的設計, 感興趣可以閱讀這篇文章: https://yq.aliyun.com/articles/498185a
Nvidia plugin
Github: https://github.com/NVIDIA/k8s-device-plugin
為了能夠在Kubernetes中管理和排程GPU, Nvidia提供了Nvidia GPU的Device Plugin。 主要功能如下
- 支援ListAndWatch 介面,上報節點上的GPU數量
- 支援Allocate介面, 支援分配GPU的行為。
Allocate 介面只做了一件事情,就是給容器加上 NVIDIA_VISIBLE_DEVICES 環境變數。 https://github.com/NVIDIA/k8s-device-plugin/blob/v1.11/server.go#L153
// Allocate which return list of devices.
func (m *NvidiaDevicePlugin) Allocate(ctx context.Context, reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
devs := m.devs
responses := pluginapi.AllocateResponse{}
for _, req := range reqs.ContainerRequests {
response := pluginapi.ContainerAllocateResponse{
Envs: map[string]string{
"NVIDIA_VISIBLE_DEVICES": strings.Join(req.DevicesIDs, ","),
},
}
for _, id := range req.DevicesIDs {
if !deviceExists(devs, id) {
return nil, fmt.Errorf("invalid allocation request: unknown device: %s", id)
}
}
responses.ContainerResponses = append(responses.ContainerResponses, &response)
}
return &responses, nil
}前面我們提到, Nvidia的 gpu-container-runtime 根據容器的 NVIDIA_VISIBLE_DEVICES 環境變數,會決定這個容器是否為GPU容器,並且可以使用哪些GPU裝置。 而Nvidia GPU device plugin做的事情,就是根據kubelet 請求中的GPU DeviceId, 轉換為 NVIDIA_VISIBLE_DEVICES 環境變數返回給kubelet, kubelet收到返回內容後,會自動將返回的環境變數注入到容器中。當容器中包含環境變數,啟動時 gpu-container-runtime 會根據 NVIDIA_VISIBLE_DEVICES 裡宣告的裝置資訊,將裝置對映到容器中,並將對應的Nvidia Driver Lib 也對映到容器中。
總體流程
整個Kubernetes排程GPU的過程如下:
- GPU Device plugin 部署到GPU節點上,通過
ListAndWatch介面,上報註冊節點的GPU資訊和對應的DeviceID。 - 當有宣告
nvidia.com/gpu的GPU Pod創建出現,排程器會綜合考慮GPU裝置的空閒情況,將Pod排程到有充足GPU裝置的節點上。 - 節點上的kubelet 啟動Pod時,根據request中的宣告呼叫各個Device plugin 的 allocate介面, 由於容器聲明瞭GPU。 kubelet 根據之前
ListAndWatch介面收到的Device資訊,選取合適的裝置,DeviceID 作為引數,呼叫GPU DevicePlugin的Allocate介面 - GPU DevicePlugin ,接收到呼叫,將DeviceID 轉換為
NVIDIA_VISIBLE_DEVICES環境變數,返回kubelet - kubelet將環境變數注入到Pod, 啟動容器
- 容器啟動時,
gpu-container-runtime呼叫gpu-containers-runtime-hook gpu-containers-runtime-hook根據容器的NVIDIA_VISIBLE_DEVICES環境變數,轉換為--devices引數,呼叫nvidia-container-cli prestartnvidia-container-cli根據--devices,將GPU裝置對映到容器中。 並且將宿主機的Nvidia Driver Lib 的so檔案也對映到容器中。 此時容器可以通過這些so檔案,呼叫宿主機的Nvidia Driver。
開發十年,就只剩下這套架構體系了!
>>>
不像在Access裡的其它的物件,儲存過程沒有使用者介面,並且不能在Access的介面裡建立。 要建立它們的方法只有編碼。我將示範如何在ADO.NET中實現這些程式碼。
當一個儲存過程被新增到Access資料庫時,JET Engine會把儲存過程轉換到一個查詢物件。 對 我們在SAP GUI裡雙擊一個screen編號:
單擊Layout按鈕可以開啟Screen Painter:
這背後的工作原理是什麼?
是這個RFC destination在起作用:
Connection Type為T,當Layout按鈕被點選後,通過TCP/IP通知執行檔案gnetx
(1) 在SAP CRM裡建立一個Lead後,會觀察到有一個Opportunity自動生成,這是通過什麼後臺邏輯實現的呢?
檢查前臺日誌或者後臺事務碼SLG1,發現有很多屬於使用者WF-BATCH的日誌. Who is WF-BATCH? WF-BACTH is a Workf
很多時候,一個Eclipse中或多或少的都會有那麼幾個工作空間(workspace),但是久而久之你會發現有些工作空間你覺得不再需要了或者覺得礙眼,怎麼辦?
其實很簡單,方法有兩種。
1、開啟你的Eclipse,選單中找到:Window-->Prefere
今天再維護Jira系統時,部門主管認為敏捷開發的流程不能很好的表現出bug的處理流程,讓單獨整理一套bug處理流程,併發布到原有的敏捷專案裡面,在使用管理員進行工作流維護中增加了bug flow 後,進行釋出,提示進行狀態關聯(這時坑出現了,狀態關聯只關聯了已有 剛剛去醫院旁邊的賤行取錢,門口的取款機人很多,大家都在排隊晒太陽.但是奇怪的是裡面的營業廳卻只有一個顧客.,於是我走到一個視窗,對那個長的人模狗樣的職員說取800塊。那個人竟然說到外面的取款機取,我問他為什麼卡不能在櫃檯上取? 他說5000以下都到取款機上取,說這是為了節約時間,提高效率、分流,我當時就
在桌面用記事本新建一個"文字文件",輸入下列內容,儲存,並命名為"顯示桌面.scf",注意副檔名是scf而不是txt。裡面的內容為: Command=2 IconFile=explorer.exe,3 Command=ToggleDesktop 然後你就可以看到那個"顯示桌面
公司安全策略限制了橋接模式,一直只用NAT模式,沒有出國什麼問題,直到升級了lion(不是GM版,是appstore上下的正版)以後,就開始隨機性的發瘋,突然虛擬機器就不能訪問網路了,新增刪除網絡卡,改路由表,怎麼都搞不定,最後終於發現瞭解決之道:只要把Lion徹底重啟一下問
1. pb裡實現無標題欄
api解決:
SetWindowLong(Handle, // 當前窗體控制代碼
GWL_STYLE, // 表示當前是要設定新的窗體(普通)樣式
Windows cmd 批處理(cmd/bat)檔案的簡單使用介紹
前言
如果你想我一樣,要每天都需要在cmd上,用鍵盤去敲擊相同的命令,時間一長,你就覺得很無聊。有沒有什麼比較高效的方法,讓我
先試試下面這種:
1. 在 bios 把 音效卡選擇
AC'97 不要選 HDMI
http://zh.wikipedia.org/wiki/AC97http://zh.wikipedia.org/wiki/HDMI2. 安裝 pavucontrol 套件
# univ
因為是微信讚賞,又需要老闆來監管每天每月打賞了多少錢。所以用員工自己的胸牌不合適,這時就需要第三方開發。function is_wechat(){
if ( strpos($_SERVER['HTTP_USER_AGENT'], 'MicroMessenger') !==
這裡有個坑,不管是這麼寫 QDoubleValidator *doubleValidator=new QDoubleValidator();
doubleValidator->set
如今市面上的CRM普遍以機械式的記錄和歸納為主,沒有一款真正實現智慧化的CRM管理軟體為企業所用。想象一下,如果我們使用了融合類神經網路、工作圖譜、大資料、類人工智慧和內容視覺化等理念的CRM,那麼,我們的工作會變成什麼樣子?
人脈關係管理是企業CRM的主要功能,目前的C
Sub text1()Worksheet.Add.Name="彙總"For Each Sheet In Worksheetsk = k + 1x = y.usedRange.Rows.Countsheets("彙總").Cells(k, 1) = Sheet.Nameshee
如果你也同樣準大三,並且在這個暑假裡打算找個實習工作,那麼在這個分享下我的經歷。
本人2015級,成都三本大學在讀,電腦科學與技術專業,專業同樣是我的愛好。在周邊朋友的影響下決定早點出去實習哈,嘗試下也未嘗不可,首先說一下我這兩年的專業技能水平,學校本科前兩年學的是專業基 來阿里也有段時間了,這段時間學了很多東西,簡單說起來,就是一個走出舒適區的過程,從一開始的新手入門,到逐漸熟悉業務和技術,再到慢慢的適應環境,勝任工作。
總體來說,這幾個月還是學到了很多東西,感覺成長的很快,但同時工作的壓力也非常的大。總體來說,歸納幾個點吧。
第一點:就是阿里的技術。
大家都知道阿里的 Ja 作為初學者來說,在C#中使用API確是一件令人頭疼的問題。
在使用API之前你必須知道如何在C#中使用結構、型別轉換、安全/不安全程式碼,可控/不可控程式碼等許多知識。
在.Net Framework SDK文件中,關於呼叫Windows API的指示比較零散,並且其中稍全面一點的是針對Visual Basi 顯示 工作 退出 獲取數據 以及 困難 任務 軟件 屬性 昨天幹了什麽:
昨天確定了軟件的詳細功能點,以及各個功能點的實現細節。
今天準備幹什麽:
今天準備開始開發,我的任務是編寫活動詳情界面,建立一個Activity,然後編寫界面,以及排版,然後對內容進行顯示 相關推薦
Nvidia GPU如何在Kubernetes 裡工作
儲存過程如何在Access裡工作?
SAP GUI裡Screen Painter的工作原理
SAP CRM裡Lead通過工作流自動建立Opportunity的原理講解
如何刪除Eclipse裡某個工作空間?
Jira更改工作流後,敏捷看板裡無法顯示sprint對應的問題列表
對付銀行裡態度惡劣的工作人員的幾招
工作列裡的顯示桌面丟失了怎麼辦
Mac os 10.7.1(Lion) 下vmware fusion裡的windows有時無法工作在NAT模式下的問題
怎樣在pb裡實現無標題欄 如何使PB視窗總在最上層 顯示或隱藏Windows的工作列
Windows cmd 將命令(/指令)寫到一個檔案裡,直接執行這個檔案。提高工作效率
linux 解決安裝Nvidia驅動後,或者聲音選項裡只有HDMI,音效卡沒有聲音的方法[集錦]
設定只允許在微信裡開啟,做一個服務讚賞評價系統,提升服務質量,讓員工更積極參與工作
Qt工作筆記-QLineEdit中使用setValidator裡面的坑
類神經網路+工作圖譜+大資料+類人工智慧+內容視覺化:一款企業軟體裡的逆天思維
如何用VBA將一個工作簿裡多張表的名字與人數彙總在一張表裡
獻給準大三的童鞋們,想要在暑假裡找個java實習工作.
在阿里工作的日子裡,我都學到了哪些東西?
C#呼叫Windows API(示例:顯示工作管理員裡的程式名稱)
第一次沖刺--個人工作總結02