
一文快速瞭解MaxCompute

很多剛初次接觸MaxCompute的使用者,面對繁多的產品文件內容以及社群文章,往往很難快速、全面瞭解MaxCompute產品全貌。同時,很多擁有大資料開發經驗的開發者,也希望能夠結合自身的背景知識,將MaxCompute產品能力與開源專案、商業軟體之間建立某種關聯和對映,以快速尋找或判斷MaxCompute是否滿足自身的需要,並結合相關經驗更輕鬆地學習和使用產品。
本文將站在一個更巨集觀的視角來分主題地介紹MaxCompute產品,以期讀者能夠通過本文快速獲取對MaxCompute產品的認識。
概念篇
產品名稱:大資料計算服務(英文名:MaxCompute)
產品說明:MaxCompute(原ODPS)是一項大資料計算服務,它能提供快速、完全託管的PB級資料倉庫解決方案,使您可以經濟並高效的分析處理海量資料。
產品說明的前半部分,將MaxCompute定義為大資料計算服務,可以理解為它的功能定位於支援大資料計算,同時是一款基於雲的服務化的產品。後半部分,說明了它的適用場景:大規模資料倉庫、海量資料處理、分析。
單從這裡還不能瞭解到大資料計算服務提供了哪些的計算能力,具備怎樣的服務化?產品定義中出現了資料倉庫字眼,我們能夠了解到MaxCompute能夠處理較大規模(這裡提到了PB級別)結構化資料。而“海量資料處理”除了資料規模大之外,對於非結構化資料的處理有待驗證,同時”分析”是否在常見的SQL分析能力之外,提供了其他複雜分析的能力。
帶著這樣的問題,我們繼續開始介紹,希望在後面的內容中能夠清晰地回答這些問題。
架構篇
在介紹功能前,先提綱挈領從產品整體邏輯結構開始,讓讀者有個全貌瞭解。
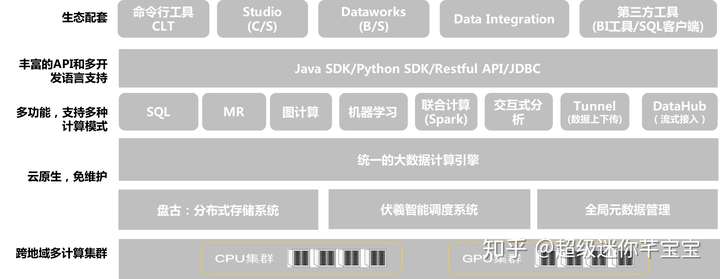
MaxCompute提供了雲原生、多租戶的服務架構,在底層大規模計算、儲存資源之上預先構建好了MaxCompute計算服務、服務介面,提供了配套的安全管控手段和開發工具管理工具,產品開箱即用。
使用者可以在阿里雲控制檯,在幾分鐘內完成服務開通並建立MaxCompute專案,無需進行底層資源開通、軟體部署、基礎設施運維,系統自動進行(由阿里雲專業團隊)版本升級、問題修復。
功能篇
資料儲存
- 支援大規模計算儲存,適用於TB以上規模的儲存及計算需求,最大可達EB級別。同一個MaxCompute專案支援企業從創業團隊發展到獨角獸的資料規模需求;
- 資料分散式儲存,多副本冗餘,資料儲存對外僅開放表的操作介面,不提供檔案系統訪問介面
- 自研資料儲存結構,表資料列式儲存,預設高度壓縮,後續將提供相容ORC的Ali-ORC儲存格式
- 支援外表,將儲存在OSS物件儲存、OTS表格儲存的資料對映為二維表
- 支援Partition、Bucket的分割槽、分桶儲存
- 更底層不是HDFS,是阿里自研的盤古檔案系統,但可藉助HDFS理解對應的表之下檔案的體系結構、任務併發機制
- 使用時,儲存與計算解耦,不需要僅僅為了儲存擴大不必要的計算資源
多種計算模型
需要說明的是,傳統資料倉庫場景下,實踐中有大部分的資料分析需求可以通過SQL+UDF來完成。但隨著企業對資料價值的重視以及更多不同的角色開始使用資料時,企業也會要求有更豐富的計算功能來滿足不同場景、不同使用者的需求。
MaxCompute不僅僅提供SQL資料分析語言,它在統一的資料儲存和許可權體系之上,支援了多種計算型別。
MaxCompute SQL:
TPC-DS 100% 支援,同時語法高度相容Hive,有Hive背景開發者直接上手,特別在大資料規模下效能強大。
- 完全自主開發的compiler,語言功能開發更靈活,迭代快,語法語義檢查更加靈活高效
- 基於代價的優化器,更智慧,更強大,更適合複雜的查詢
- 基於LLVM的程式碼生成,讓執行過程更高效
- 支援複雜資料型別(array,map,struct)
- 支援Java、Python語言的UDF/UDAF/UDTF
- 語法:Values、CTE、SEMIJOIN、FROM倒裝、Subquery Operations、Set Operations(UNION /INTERSECT /MINUS)、SELECT TRANSFORM 、User Defined Type、GROUPING SET(CUBE/rollup/GROUPING SET)、指令碼執行模式、引數化檢視
- 支援外表(外部資料來源+StorageHandler 支援非結構化資料)
MapReduce:
- 支援MapReduce程式設計介面(提供優化增強的MaxCompute MapReduce,也提供高度相容Hadoop的MapReduce版本)
- 不暴露檔案系統,輸入輸出都是表
- 通過MaxCompute客戶端工具、Dataworks提交作業
MaxCompute Graph圖模型:
- MaxCompute Graph是一套面向迭代的圖計算處理框架。圖計算作業使用圖進行建模,圖由點(Vertex)和邊(Edge)組成,點和邊包含權值(Value)。
- 通過迭代對圖進行編輯、演化,最終求解出結果
- 典型應用有:PageRank,單源最短距離演算法,K-均值聚類演算法等
- 使用MaxCompute Graph提供的介面Java SDK編寫圖計算程式並通過MaxCompute客戶端工具通過jar命令提交任務
PyODPS:
用熟悉的Python利用MaxCompute大規模計算能力處理MaxCompute資料。
PyODPS是MaxCompute 的 Python SDK,同時也提供 DataFrame 框架,提供類似 pandas 的語法,能利用 MaxCompute 強大的處理能力來處理超大規模資料。
- PyODPS 提供了對 ODPS 物件比如 表 、資源 、函式 等的訪問。
- 支援通過 run_sql/execute_sql 的方式來提交 SQL。
- 支援通過 open_writer 和 open_reader 或者原生 tunnel API 的方式來上傳下載資料
- PyODPS 提供了 DataFrame API,它提供了類似 pandas 的介面,能充分利用 MaxCompute 的計算能力進行DataFrame的計算。
- PyODPS DataFrame 提供了很多 pandas-like 的介面,但擴充套件了它的語法,比如增加了 MapReduce API 來擴充套件以適應大資料環境。
- 利用map 、apply 、map_reduce 等方便在客戶端寫函式、呼叫函式的方法,使用者可在這些函式裡呼叫三方庫,如pandas、scipy、scikit-learn、nltk
Spark:
MaxCompute提供了Spark on MaxCompute的解決方案,使MaxCompute提供的相容開源的Spark計算服務,讓它在統一的計算資源和資料集許可權體系之上,提供Spark計算框架,支援使用者以熟悉的開發使用方式提交執行Spark作業。
- 支援原生多版本Spark作業:Spark1.x/Spark2.x作業都可執行;
- 開源系統的使用體驗:Spark-submit提交方式(暫不支援spark-shell/spark-sql的互動式),提供原生的Spark WebUI供使用者檢視;
- 通過訪問OSS、OTS、database等外部資料來源,實現更復雜的ETL處理,支援對OSS非結構化進行處理;
- 使用Spark面向MaxCompute內外部資料開展機器學習,擴充套件應用場景;
互動式分析(Lightning)
MaxCompute產品的互動式查詢服務,特性如下:
- 相容PostgreSQL:相容PostgreSQL協議的JDBC/ODBC介面,所有支援PostgreSQL資料庫的工具或應用使用預設驅動都可以輕鬆地連線到MaxCompute專案。支援主流BI及SQL客戶端工具的連線訪問,如Tableau、帆軟BI、Navicat、SQL Workbench/J等。
- 顯著提升的查詢效能:提升了一定資料規模下的查詢效能,查詢結果秒級可見,支援BI分析、Ad-hoc、線上服務等場景;
機器學習:
- MaxCompute內建支援的上百種機器學習演算法,目前MaxCompute的機器學習能力由PAI產品進行統一提供服務,同時PAI提供了深度學習框架、Notebook開發環境、GPU計算資源、模型線上部署的彈性預測服務。PAI產品與MaxCompute在專案和資料方面無縫整合。
對比篇
為便於讀者,特別是有開源社群經驗的讀者快速建立對MaxCompute主要功能的瞭解,這裡做簡單地對映說明。
專案
MaxCompute產品
對開源社群的一些比較說明
SQL
MaxCompute SQL
阿里自研SQL引擎,語法相容Hive,功能和效能更優
MapReduce
MaxCompute MR
阿里自研,類似並支援Hadoop MapReduce,MaxCompute Open MR做了優化和提升
互動式
MaxCompute Lightning
Serverless的互動式查詢服務,功能類似開源生態的Presto、Hawk等
Spark
Spark on MaxCompute
支援原生Spark執行在MaxCompute上,類似Spark on Yarn形態
機器學習
PAI
不同於開源社群的演算法庫,PAI有更豐富的演算法,超大規模處理能力,更是覆蓋了ML/DL全流程需求的平臺服務。
儲存
Pangu
阿里自研分散式儲存服務,類似HDFS。MaxCompute對外目前只暴露表介面,不能直接訪問檔案系統。
資源排程
Fuxi
阿里自研的資源排程系統,類似Yarn。
資料上傳下載
Tunnel
不暴露檔案系統,通過Tunnel進行批量資料上傳下載。
流式接入
Datahub
MaxCompute配套的流式資料接入服務,粗略地類似kafka,能夠通過簡單配置歸檔topic資料到MaxCompute表
使用者介面
CLT/SDK
統一的命令列工具和JAVA/PYTHON SDK
開發&診斷
Dataworks/Studio/Logview
配套的資料同步、作業開發、工作流編排排程、作業運維及診斷工具。開源社群常見的Sqoop、Kettle、Ozzie等實現資料同步和排程。
整體
不是孤立的功能,完整的企業服務
不需要多元件整合、調優、定製,開箱即用。
問題篇
dataworks和MaxCompute之間的關係與區別?
這是2個產品,MaxCompute做資料儲存和資料分析處理,Dataworks是集成了資料整合、資料開發除錯、作業編排及運維、元資料管理、資料質量管理、資料API服務等等功能的大資料開發IDE套件。類似Spark和HUE的關係,不知道這個對比是否準確。
想測試、體驗MaxCompute,成本費用高嗎?
不高,應該說很低。MaxCompute提供了按作業付費的模式,其中單個作業的費用有和作業處理的資料大小密切相關。開通按量付費服務,並建立1專案。利用MaxCompute客戶端工具(ODPSCMD)或者在dataworks裡,建立表並上傳測試資料,就可以開始測試體驗了。資料不大的話,10元錢可以用很長一段時間。
當然,MaxCompute還有獨佔資源的模式,出於費用可控的考慮,也選擇了預付費的模式。
另外,MaxCompute馬上推出”開發者版”,每個月為開發者贈送一定的免費額度用於開發、學習。
MaxCompute儲存目前只暴露表,能處理非結構化資料嗎?
可以,非結構化資料可以存放在OSS上,一種方式是通過外表方式,通過自定義Extractor來實現非結構化處理為結構化資料的邏輯。另外,也可以用Spark on MaxCompute對OSS進行訪問,通過Spark程式對OSS目錄下的檔案進行抽取轉換,結果寫入MaxCompute表。
支援哪些資料來源接入到MaxCompute
通過Dataworks資料整合服務或者自己使用DataX,可以實現阿里雲上的各種離線資料來源如資料庫、HDFS、FTP等資料來源的接入;
也可以用MaxCompute Tunnel工具/SDK,通過命令或SDK批量進行資料上傳、下載;
流式資料,可以利用MaxCompute提供的Flume/logstash外掛,將流式資料寫入Datahub,然後歸檔到MaxCompute表;
支援阿里雲SLS、DTS服務資料寫入MaxCompute表;
總結
本文簡要介紹了MaxCompute這個產品基本概念和功能,並和大家熟悉的開源社群服務進行了對比對映,希望對大家快速瞭解阿里雲大資料計算服務。
本文為雲棲社群原創內容,未經