
剖析Hadoop和Spark的Shuffle過程差異(二)

上一篇部落格《剖析Hadoop和Spark的Shuffle過程差異(一)》剖析了Hadoop MapReduce的Shuffle過程,那麼本篇部落格,來聊一聊Spark shuffle。
Spark shuffle相對來說更簡單,因為不要求全域性有序,所以沒有那麼多排序合併的操作。Spark shuffle分為write和read兩個過程。我們先來看shuffle write。
一、shuffle write
shuffle write的處理邏輯會放到該ShuffleMapStage的最後(因為spark以shuffle發生與否來劃分stage,也就是寬依賴),final RDD的每一條記錄都會寫到對應的分割槽快取區bucket,如下圖所示:
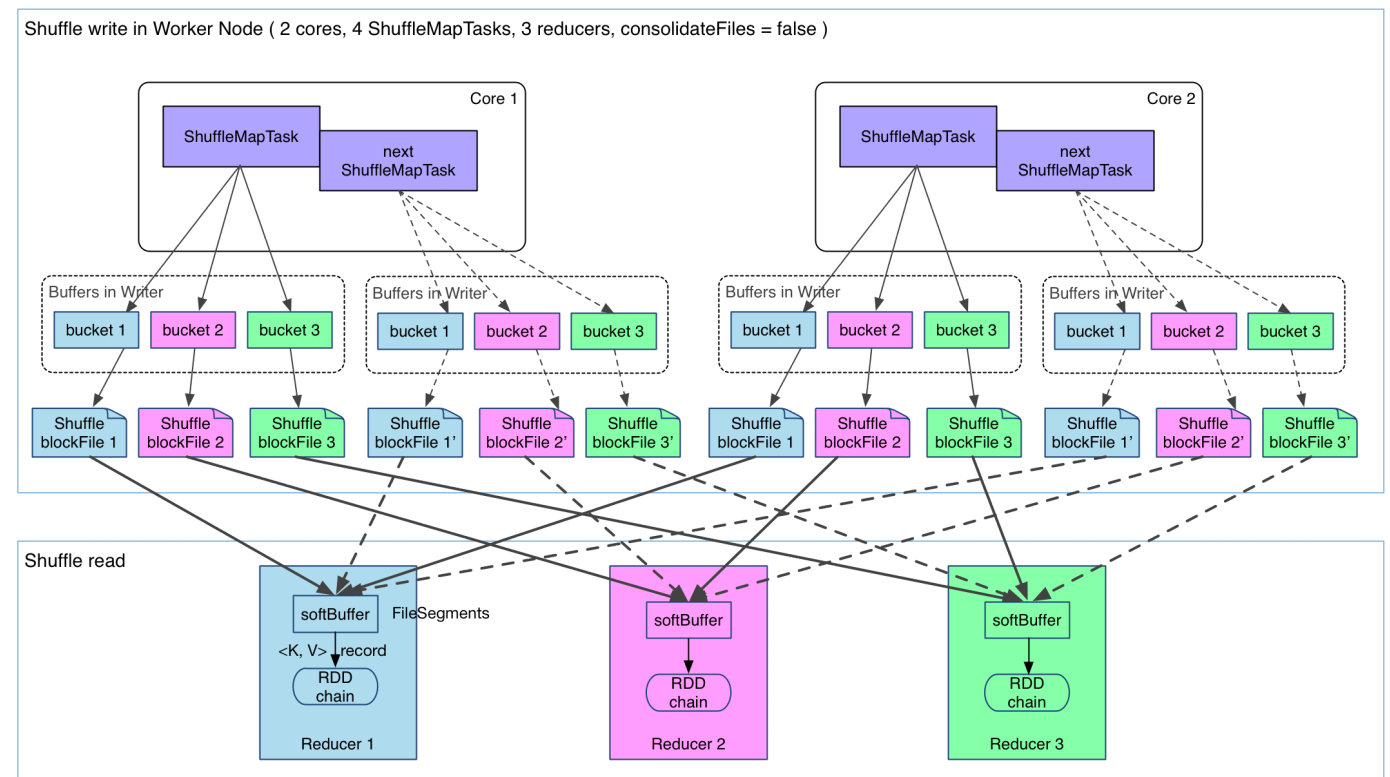
說明:
1、上圖有2個CPU,可以同時執行兩個ShuffleMapTask
2、每個task將寫一個buket緩衝區,緩衝區的數量和reduce任務的數量相等
3、 每個buket緩衝區會生成一個對應ShuffleBlockFile
4、ShuffleMapTask 如何決定資料被寫到哪個緩衝區呢?這個就是跟partition演算法有關係,這個分割槽演算法可以是hash的,也可以是range的
5、最終產生的ShuffleBlockFile會有多少呢?就是ShuffleMapTask 數量乘以reduce的數量,這個是非常巨大的
那麼有沒有辦法解決生成檔案過多的問題呢?有,開啟FileConsolidation即可,開啟FileConsolidation之後的shuffle過程如下:
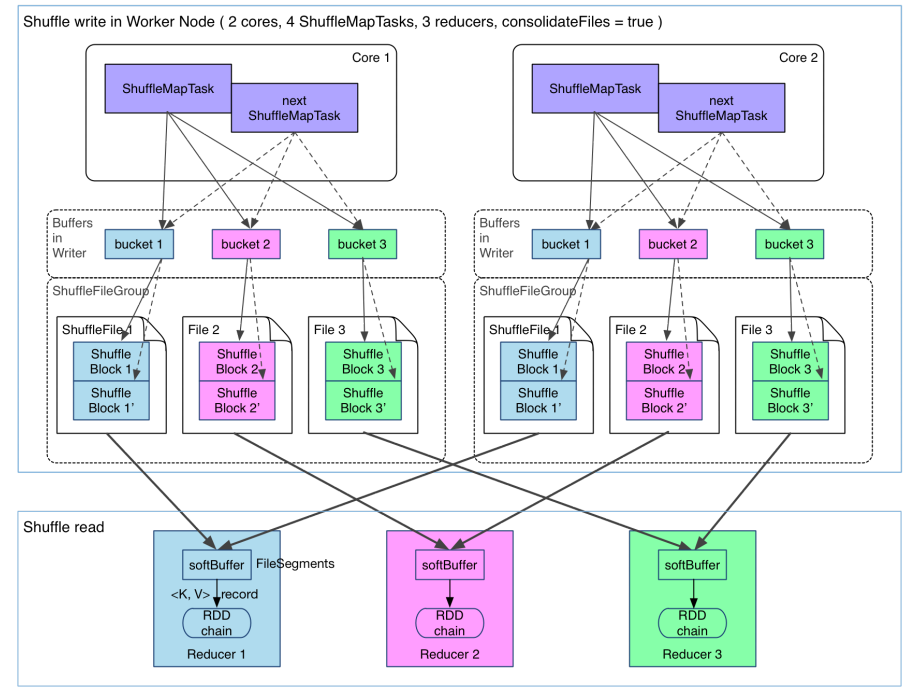
在同一核CPU執行先後執行的ShuffleMapTask可以共用一個bucket緩衝區,然後寫到同一份ShuffleFile裡去,上圖所示的ShuffleFile實際上是用多個ShuffleBlock構成,那麼,那麼每個worker最終生成的檔案數量,變成了cpu核數乘以reduce任務的數量,大大縮減了檔案量。
二、Shuffle read
Shuffle write過程將資料分片寫到對應的分片檔案,這時候萬事具備,只差去拉取對應的資料過來計算了。
那麼Shuffle Read傳送的時機是什麼?是要等所有ShuffleMapTask執行完,再去fetch資料嗎?理論上,只要有一個 ShuffleMapTask執行完,就可以開始fetch資料了,實際上,spark必須等到父stage執行完,才能執行子stage,所以,必須等到所有 ShuffleMapTask執行完畢,才去fetch資料。fetch過來的資料,先存入一個Buffer緩衝區,所以這裡一次性fetch的FileSegment不能太大,當然如果fetch過來的資料大於每一個閥值,也是會spill到磁碟的。
fetch的過程過來一個buffer的資料,就可以開始聚合了,這裡就遇到一個問題,每次fetch部分資料,怎麼能實現全域性聚合呢?以word count的reduceByKey(《Spark RDD操作之ReduceByKey 》)為例,假設單詞hello有十個,但是一次fetch只拉取了2個,那麼怎麼全域性聚合呢?Spark的做法是用HashMap,聚合操作實際上是map.put(key,map.get(key)+1),將map中的聚合過的資料get出來相加,然後put回去,等到所有資料fetch完,也就完成了全域性聚合。
三、總結
Hadoop的MapReduce Shuffle和Spark Shuffle差別總結如下:
1、Hadoop的有一個Map完成,Reduce便可以去fetch資料了,不必等到所有Map任務完成,而Spark的必須等到父stage完成,也就是父stage的map操作全部完成才能去fetch資料。
2、Hadoop的Shuffle是sort-base的,那麼不管是Map的輸出,還是Reduce的輸出,都是partion內有序的,而spark不要求這一點。
3、Hadoop的Reduce要等到fetch完全部資料,才將資料傳入reduce函式進行聚合,而spark是一邊fetch一邊聚合。