
積累命令、用戶、正則表達式
HISTTIMEFORMAT="%F %T"
2 basename命令: 取路徑基名
3 dirname命令: 取路徑名
4 stat命令: 查看文件狀態
Access最後訪問時間(讀取)
Change狀態修改時間(屬性、權限)
4 help 內部命令列表
5 enable cmd 啟用內部命令
6 enable –n cmd 禁用內部命令
7 enable –n 查看所有禁用的內部命令
8 hash 顯示hash緩存
–r 清除緩存
9 date 顯示和設置系統時間 (+%F%T)
10 hwclock,clock: 顯示硬件時鐘
-s, 以硬件時鐘為準
11 顯示日歷:cal (–y)
輸入輸出重定向
鍵盤 stdin 0 標準輸入
顯示器 stdout 1 標註輸出
顯示器 stderr 2 標準錯誤
/dev/null 黑洞、回收站
hexdump -C 轉換16進制查看
set -C 禁止將內容覆蓋,但可追加
set +C 允許覆蓋
.>| 強制覆蓋
.> 覆蓋式輸出
.>> 原有內容基礎上追加內容
2> 錯誤輸出
2>> 錯誤輸出追加
&> 把所有輸出重定向到文件
&>> 追加式輸出所有
ls >>1 2>>2 正確命令輸出到1文件 錯誤輸出到2文
(命令1,命令2) >文件1 多個命令都寫入文件1中
tr 轉換和刪除字符
-s壓縮
-d刪除
-c取字符補集
-t將第一字符替換為第二字符
例如 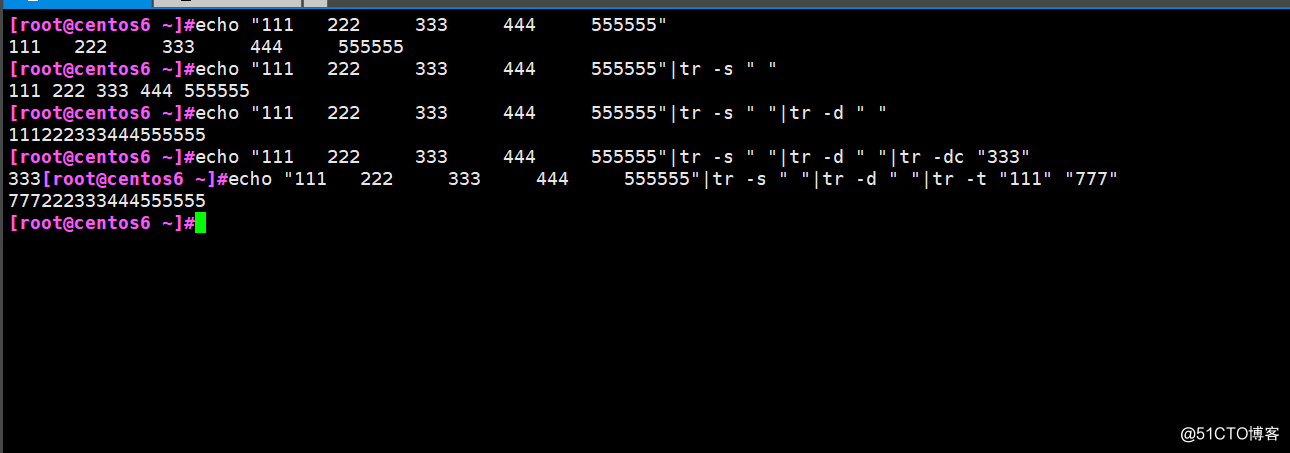
tr ‘a-z‘ ‘A-Z‘ < file1 將文件中小寫字母都替換成大寫字母 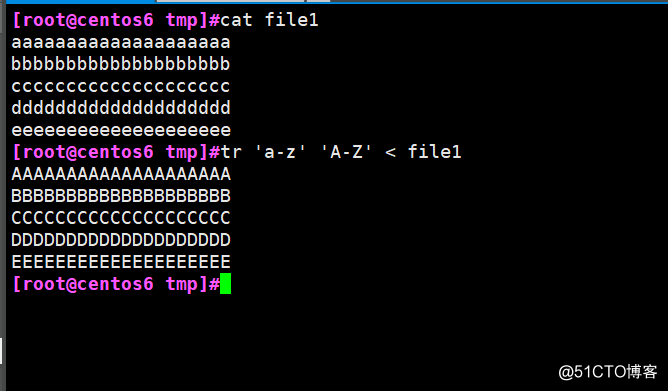
tr -d abc < file1 刪除file1文件中的所有abc字母 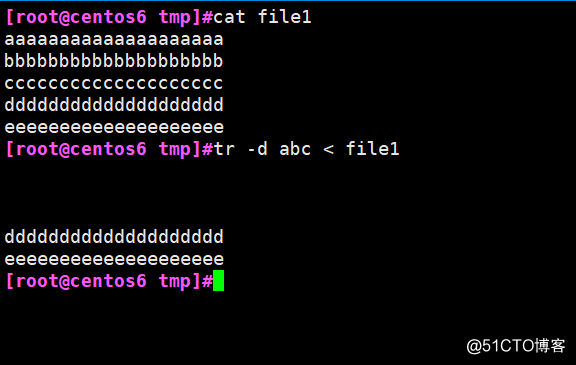
使用文件代替鍵盤的輸入 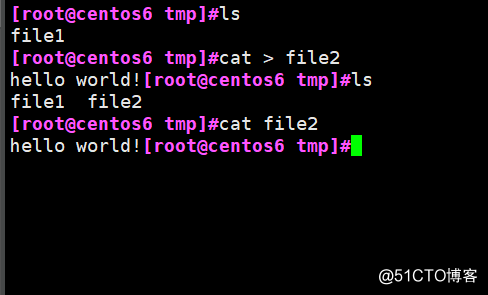
cat < file1 >> file2 讀取file1內容追加到file2中 
| 管道符
echo {1..100} | tr ‘ ‘ + | bc
seq 100 seq -s + 100 |bc
用戶和組的配置文件
新建用戶會默認生成
/etc/passwd 用戶信息文件
/etc/shadow 影子文件
/etc/group 組信息文件
/etc/gshadow 組密碼文件
/home/ 用戶家目錄
/var/spool/mail 用戶郵箱
- useradd 用戶創建命令
-u 指定UID
-o 配合-u使用,不檢查UID的唯一性
-g 指定所屬組
-c 用戶的註釋信息
-d 指定家目錄
-s 指定默認shell程序
-G 指定附加組
-r 創建系統用戶
-m 創建家目錄,用於系統用戶
-M 不創建家目錄,用於非系統用戶
vim /etc/default/useradd 創建用戶的默認值設定
usermod 用戶屬性修改
-u 新的UID
-g 新的主組
-G 新的附加組(配合-a使用,保留原有附加組)
-s 新的默認SHELL
-c 新的註釋信息
-L 臨時鎖定普通用戶
-U 解鎖用戶
userdel -r 刪除用戶
id 查看用戶相關的ID信息
-u 顯示UID
-g 顯示GID
-G 顯示附加組
su - 登錄式切換用戶 su 非登錄式切換
passwd 設置密碼
-d 刪除指定用戶密碼
-l 鎖定指定用戶
-u 解鎖用戶
-e 強制用戶下次登錄修改密碼
groupadd 創建組
-g 指定GID
-r 創建系統組
groupmod 修改組屬性
-n 新名字
-g 新的GID
groupdel 刪除組
cat -E 顯示行結束符$
-A 顯示所有控制符
-s壓縮連續的空行成一行
tac
rev 以字符為單位反序輸出 cat /etc/passwd |rev
cut -d -f 抽取指定分隔符和第幾個字段
paste file1 file2 合並兩個文件
-d指定分隔符,默認用TAB
-所有行合成一行顯示
wc 收集文本統計數據
-l 只計數行數
-w 只計數單詞總數
-c 只計數字節總數
sort 排序命令
-t指定分隔符
-k [n,m] 按照指定的字段範圍排序
-n以數值型進行排序
-r反向排序
-R隨機排序
uniq -c 統計出現的次數
-d 取相同的
-u 取各不相同的
diff -u file1 file2 > file3 比較兩個文件然後運算出file3
patch file1 file3 使用patch通過file1和file3可以找回file2(但是找回的時候file2會覆蓋file1,所以需要提前先把file1備份)
ss -nt 查看遠程連接
grep 文本搜索工具
--color=auto對匹配到的文本著色顯示
-v 顯示不匹配到的行
-i 忽略大小寫
-n 顯示匹配的行號
-c 統計匹配的行數
-o 僅顯示匹配到的字符串
-E 使用擴展功能
-e 使用多個選項間的邏輯關系
-A 匹配的行加上後幾行
-B 匹配的行加上前幾行
-C 匹配的行加上前後各幾行
-w 匹配整個單詞
基本正則表達式
. 匹配任意單個字符
[] 匹配指定範圍內的任意單個字符
[^] 匹配指定範圍外的任意單個字符
[:alnum:] : 字母和數字
[:alpha:] : 字母
[:digit:] : 數字
[:lower:] : 小寫字母
[:upper:] : 大寫字母
[:xdigit:] : 六進制字符
[:blank:] : 空格和制表符
[:space:] : 空白字符(水平加垂直比blank廣泛)
[:print:] : 可打印的非空白字符
[:punct:] : 標點符號
[:graph:] : 可打印的非空白字符
匹配前面的字符任意次,包括0次(貪婪模式:盡可能長的匹配)
.任意長度的任意字符
\? 匹配其前面的字符0或1次
\ +匹配其前面的字符至少1次
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m次至多n次
{,n} 匹配前面的字符至多n次
{n,} 匹配前面的字符至少n次
^ 行首錨定
$ 行尾錨定
^$ 空行
\<或\b詞首錨定
\>或\b詞尾錨定
\< word \> 匹配整個單詞
() 分組
積累命令、用戶、正則表達式