
Apache Ignite上的TensorFlow

任何深度學習都是從資料開始的,這是關鍵點。沒有資料,就無法訓練模型,也無法評估模型質量,更無法做出預測,因此,資料來源非常重要。在做研究、構建新的神經網路架構、以及做實驗時,會習慣於使用最簡單的本地資料來源,通常是不同格式的檔案,這種方法確實非常有效。但有時需要更加接近於生產環境,那麼簡化和加速生產資料的反饋,以及能夠處理大資料就變得非常重要,這時就需要Apache Ignite大展身手了。
Apache Ignite是以記憶體為中心的分散式資料庫、快取,也是事務性、分析性和流式負載的處理平臺,可以實現PB級的記憶體級速度。藉助Ignite和TensorFlow之間的現有整合,可以將Ignite用作神經網路訓練和推理的資料來源,也可以將其用作分散式訓練的檢查點儲存和叢集管理器。
分散式記憶體資料來源
作為以記憶體為中心的分散式資料庫,Ignite可以提供快速資料訪問,擺脫硬碟的限制,在分散式叢集中儲存和處理需要的所有資料,可以通過使用Ignite Dataset來利用Ignite的這些優勢。
注意Ignite不只是資料庫或資料倉庫與TensorFlow之間ETL管道中的一個步驟,它還是一個
下面的測試結果表明,Ignite非常適合用於單節點資料儲存場景。如果儲存和客戶端位於同一節點,則通過使用Ignite,可以實現每秒超過850MB的吞吐量,如果儲存位於與客戶端相關的遠端節點,則吞吐量約為每秒800MB。
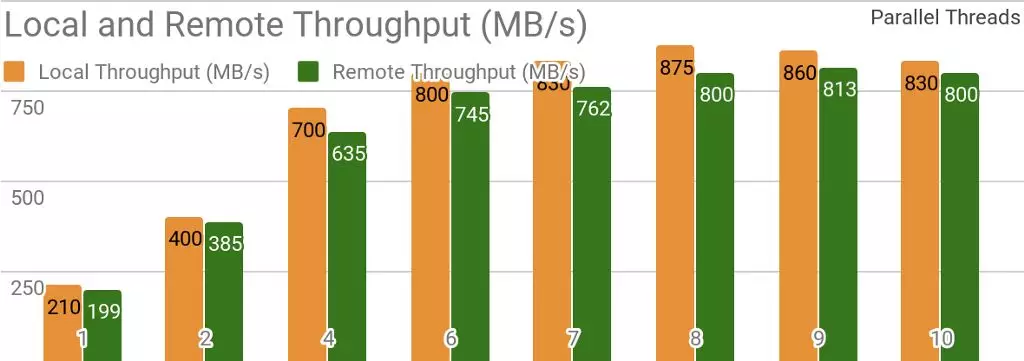
當存在一個本地Ignite節點時Ignite Dataset的吞吐量。執行該基準測試時使用的是2個Xeon E5–2609 v4 1.7GHz處理器,配備 16GB記憶體和每秒10Gb的網路(1MB的行和20MB 的頁面大小)
另一個測試顯示Ignite Dataset如何與分散式Ignite叢集協作。這是Ignite作為HTAP系統的預設用例,它能夠在每秒10Gb的網路叢集上為單個客戶端實現每秒超過1GB的讀取吞吐量。

分散式Ignite叢集具備不同數量的節點(從1到9)時Ignite Dataset的吞吐量。執行該測試時使用的是2個Xeon E5–2609 v4 1.7GHz處理器,配備16GB記憶體和每秒10Gb的網路(1MB的行和20MB的頁面大小)
測試後的用例如下:Ignite快取(以及第一組測試中數量不同的分割槽和第二組測試中的2048個分割槽)由10000個大小為1MB的行填充,然後TensorFlow客戶端使用Ignite Dataset讀取所有資料。所有節點均為2個Xeon E5–2609 v4 1.7GHz處理器,配備16GB記憶體和每秒10Gb的網路連線,每個節點都使用預設配置執行Ignite。
可以很輕鬆地將Ignite同時用作支援SQL介面的傳統資料庫和TensorFlow資料來源。
apache-ignite/bin/ignite.sh
apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR);
INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY');
INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY');
INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE")
for element in dataset:
print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}}
{'key': 2, 'val': {'NAME': b'SOFT KITTY'}}
{'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
結構化物件
使用Ignite可以儲存任何型別的物件,這些物件可以具備任何層次結構。Ignite Dataset有處理此類物件的能力。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES")
for element in dataset.take(1):
print(element)
{
'key': 'kitten.png',
'val': {
'metadata': {
'file_name': b'kitten.png',
'label': b'little ball of fur',
width: 800,
height: 600
},
'pixels': [0, 0, 0, 0, ..., 0]
}
}
如果使用Ignite Dataset,則神經網路訓練和其它計算所需的轉換都可以作為tf.data管道的一部分來完成。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels'])
for element in dataset:
print(element)
[0, 0, 0, 0, ..., 0]
分散式訓練
作為機器學習框架,TensorFlow可以為分散式神經網路訓練、推理及其它計算提供原生支援。分散式神經網路訓練的主要理念是能夠在每個資料分割槽(基於水平分割槽)上計算損失函式的梯度(例如誤差的平方),然後對梯度求和,以得出整個資料集的損失函式梯度。藉助這種能力,可以在資料所在的節點上計算梯度,減少梯度,最後更新模型引數。這樣就無需在節點間傳輸資料,從而避免了網路瓶頸。
Ignite在分散式叢集中使用水平分割槽儲存資料。在建立Ignite快取(或基於SQL的表)時,可以指定將要在此對資料進行分割槽的分割槽數量。例如,如果一個Ignite叢集由100臺機器組成,然後建立了一個有1000個分割槽的快取,則每臺機器將要維護10個數據分割槽。
Ignite Dataset可以利用分散式神經網路訓練(使用TensorFlow)和Ignite分割槽兩者的能力。Ignite Dataset是一個可以在遠端工作節點上執行的計算圖操作。遠端工作節點可以通過為工作節點程序設定相應的環境變數(例如IGNITE_DATASET_HOST、IGNITE_DATASET_PORT或IGNITE_DATASET_PART)來替換Ignite Dataset的引數(例如主機、埠或分割槽)。使用這種替換方法,可以為每個工作節點分配一個特定分割槽,以使一個工作節點只處理一個分割槽,同時可以與單個數據集透明協作。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
dataset = IgniteDataset("IMAGES")
# Compute gradients locally on every worker node.
gradients = []
for i in range(5):
with tf.device("/job:WORKER/task:%d" % i):
device_iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
device_next_obj = device_iterator.get_next()
gradient = compute_gradient(device_next_obj)
gradients.append(gradient)
# Aggregate them on master node.
result_gradient = tf.reduce_sum(gradients)
with tf.Session("grpc://localhost:10000") as sess:
print(sess.run(result_gradient))
藉助Ignite,還可以使用TensorFlow的高階Estimator API來進行分散式訓練。此功能以所謂的TensorFlow分散式訓練的獨立客戶端模式為基礎,Ignite在其中發揮資料來源和叢集管理器的作用。
檢查點儲存
除資料庫功能外,Ignite還有一個名為IGFS的分散式檔案系統。IGFS 可以提供與Hadoop HDFS類似的功能,但僅限於記憶體。事實上除了自有API外,IGFS還實現了Hadoop的FileSystem API,可以透明地部署到Hadoop或Spark環境中。Ignite上的TensorFlow支援IGFS與TensorFlow整合,該整合基於TensorFlow端的自定義檔案系統外掛和Ignite端的IGFS原生API,它有許多使用場景,比如:
- 可以將狀態檢查點儲存到IGFS中,以獲得可靠性和容錯性;
- 訓練過程可以通過將事件檔案寫入
TensorBoard監視的目錄來與TensorBoard通訊。即使TensorBoard在不同的程序或機器中執行,IGFS也可以正常執行。
TensorFlow在1.13版本中釋出了此功能,並將在TensorFlow 2.0中作為tensorflow/io的一部分發布。
SSL連線
通過Ignite,可以使用SSL和認證機制來保護資料傳輸通道。Ignite Dataset同時支援有認證和無認證的SSL連線,具體資訊請參見Ignite的SSL/TLS文件。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES",
certfile="client.pem",
cert_password="password",
username="ignite",
password="ignite")
Windows支援
Ignite Dataset完全相容Windows系統,可以在Windows和Linux/MacOS系統上將其用作TensorFlow的一部分。
試用
下面的示例非常有助於入門。
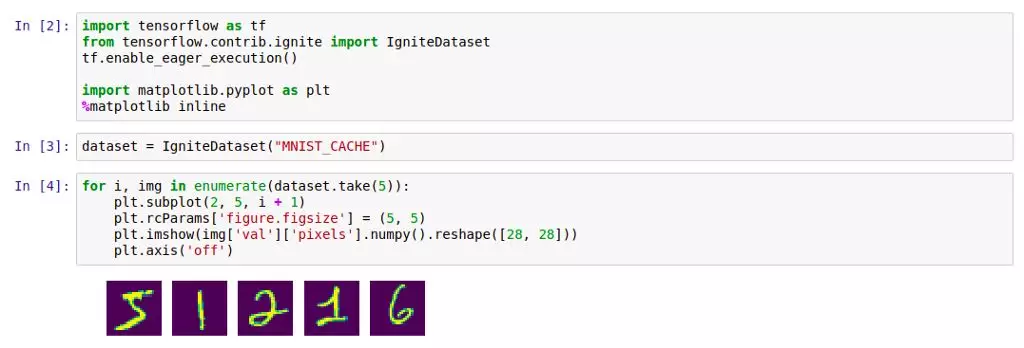
Ignite Dataset
要試用Ignite Dataset,最簡單的方法是執行裝有Ignite和載入好的MNIST資料的Docker容器,然後使用Ignite Dataset與其互動。可以在Docker Hub:dmitrievanthony/ignite-with-mnist上找到此容器,然後執行如下命令啟動容器:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
然後可以按照如下方法進行使用:
IGFS
TensorFlow的IGFS支援於TensorFlow 1.13中釋出,並將在TensorFlow 2.0中作為tensorflow/io的一部分發布。如要通過TensorFlow試用IGFS,最簡單的方法是執行一個裝有Ignite和IGFS的Docker容器,然後使用TensorFlow的tf.gfile與之互動。可以在Docker Hub:dmitrievanthony/ignite-with-igfs上找到此容器,然後執行如下命令啟動容器:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
然後可以按照如下方法進行使用:
import tensorflow as tf
import tensorflow.contrib.ignite.python.ops.igfs_ops
with tf.gfile.Open("igfs:///hello.txt", mode='w') as w:
w.write("Hello, world!")
with tf.gfile.Open("igfs:///hello.txt", mode='r') as r:
print(r.read())
Hello, world!
限制
目前,Ignite Dataset要求快取中的所有物件都具有相同的結構(同類型物件),並且快取中至少包含一個檢索模式所需的物件。另一個限制與結構化物件有關,Ignite Dataset不支援UUID、Map和可能是物件結構組成部分的物件陣列。
即將釋出的TensorFlow 2.0
TensorFlow 2.0中會將此功能拆分到tensorflow/io模組,這樣會更靈活。這些示例將略有改動,後續的文件和