
好程式設計師大資料教程Hadoop全分佈安裝(非HA)

機器名稱 啟動服務
linux11 namenode secondrynamenode datanode
linux12 datanode
linux13 datanode
第一步:更改主機名,臨時修改+永久修改
臨時修改:hostname linux11
永久修改: vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=linux11
臨時修改:hostname linux12
永久修改: vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=linux11
臨時修改:hostname linux13
永久修改: vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=linux13
第二步:配置ip地址
1.三臺機器關閉NetworkManager服務 service NetworkManager stop
2.三臺機器禁止開機啟動NetworkManager服務 chkconfig NetworkManager off
3. vi /etc/sysconfig/network-scripts/ifcfg-eth0
三臺機器依次配置成這樣
linux11:
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.91.11
DNS1=8.8.8.8
GATEWAY=192.168.91.1
NETMASK=255.255.255.0
linux12:
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.91.12
DNS1=8.8.8.8
GATEWAY=192.168.91.1
NETMASK=255.255.255.0
linux13:
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.91.13
DNS1=8.8.8.8
GATEWAY=192.168.91.1
NETMASK=255.255.255.0
最終結果:
192.168.91.11 linux11
192.168.91.12 linux12
192.168.91.13 linux13
3.三臺機器關閉防火牆 service iptables stop
4.三臺機器設定禁止開機啟動防火牆 chkconfig iptables off
5.三臺機器關閉防火牆 service iptables status
顯示iptables: Firewall is not running.說明防火牆關閉成功
6.三臺機器重啟網絡卡service network restart
第三步配置主機對映
使用命令:vi /etc/hosts
三臺機器都改成這樣
192.168.91.11 linux11
192.168.91.12 linux12
192.168.91.13 linux13
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
測試:
在linux11上 ping linux12 ping linux13
第四步配置免密碼登入
linux11:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
linux12:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
linux13:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
在linux11上
ssh-copy-id linux12
ssh-copy-id linux13
測試:測試結果為linux11可以免密碼登入到所有機器。linux12 linux13可以免密碼登入本機
例如:在linux11上輸入 ssh linux11
第五步安裝jdk及hadoop(由於使用root使用者操作,為了防止對liunx操作不熟悉的人,誤刪其他檔案。所以沒有選擇把軟體安裝在/usr下,而是選擇安裝在了自己建立的檔案目錄下)
linux11:
1.在根目錄下建立bigdata目錄 mkdir /bigdata
2.將hadoop安裝包 tar -zxvf /bigdata/hadoop-2.7.1.tar.gz -C /bigdata/
刪除hadoop安裝包 rm -rf /bigdata/hadoop-2.7.1.tar.gz
3.jdk安裝包解壓 tar -zxvf /bigdata/jdk-8u151-linux-x64.gz -C /bigdata/
刪除jdk安裝包 rm -rf /bigdata/jdk-8u151-linux-x64.gz
修改jdk目錄的名字為jdk1.8 mv /bigdata/jdk1.8.0_151/ /bigdata/jdk1.8
4.配置環境變數 vi /etc/profile
在檔案末尾加入如下配置
export JAVA_HOME=/bigdata/jdk1.8
export HADOOP_HOME=/bigdata/hadoop-2.7.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
第六步:hadoop的配置
1.hadoop-env.sh的配置
使用命令 vi /bigdata/hadoop-2.7.1/etc/hadoop/hadoop-env.sh
第25行export JAVA_HOME=改成下面的樣子
export JAVA_HOME=/bigdata/jdk1.8
2.core-site.xml 的配置
使用命令 vi /bigdata/hadoop-2.7.1/etc/hadoop/core-site.xml
配置成這樣:
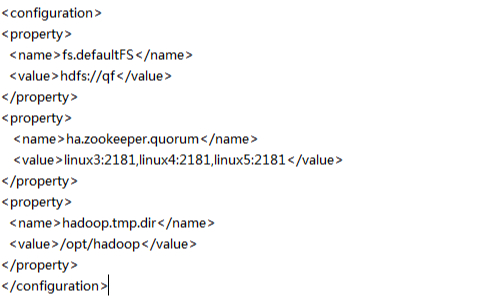
3.hdfs-site.xml的配置
使用命令 vi /bigdata/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
配置成這樣:
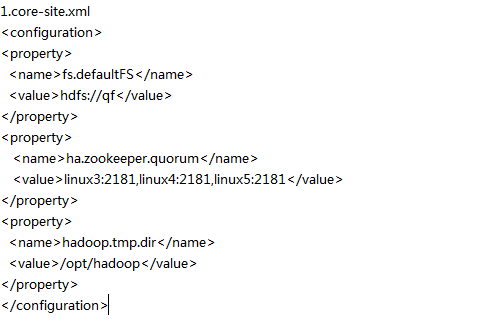
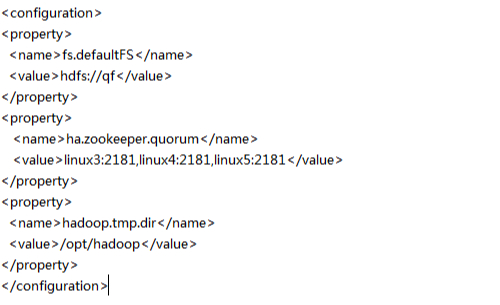
4.slaves檔案配置
使用命令 vi /bigdata/hadoop-2.7.1/etc/hadoop/slaves
配置成這樣
linux11
linux12
linux13
第七步:遠端拷貝
1.將bigdata檔案分發給linux12 linux13
scp -r /bigdata linux12:/
scp -r /bigdata linux13:/
2.將/etc/profile檔案分發給linux12 linux13
scp /etc/profile linux12:/etc
scp /etc/profile linux13:/etc
3.三臺機器重新整理環境變數 source /etc/profile
第八步:格式化namenode
在namenode節點linux11上輸入命令 hdfs namenode -format
格式化完成後在linux11上啟動叢集 start-dfs.sh
第九步:驗證叢集是否啟動成功
1.在瀏覽器上輸入192.168.91.11:50070如果頁面能開啟顯示有3個活躍節點說明成功
2.linux11上輸入jps 能看到namenode secondrynamenode datanode三個服務
3.linux12上輸入jps 能看到datanode
4.linux12上輸入jps 能看到datanode
5.上傳個檔案至叢集hdfs dfs -put /bigdata/jdk1.8 /
6.檢視web頁面是否存在這個檔案
好程式設計師,從平凡到卓越