
Redis復制實現原理
摘要
我的前一篇文章《Redis 復制原理及特性》已經介紹了Redis復制相關特性,這篇文章主要在理解Redis復制相關源碼的基礎之上介紹Redis復制的實現原理。
Redis復制實現原理
應用場景化
為了更好地表達與理解,我們先舉個實際應用場景例子來看看Redis復制是怎麽工作的,我們先啟動一臺master:
$ ./redis-server --port 8000
然後啟動一個redis客戶端和上面那臺監聽8000端口的Redis實例連接:
$ ./redis-cli -p 8000
我們向redis寫一個數據:
127.0.0.1:8000> set msg doni OK 127.0.0.1:8000> get msg "doni"
於是我們可以假設以下場景:
我們有一臺master實例master,master已經處於正常工作的狀態,接受讀寫請求,這個時候由於單臺機器的壓力過大,我們想再啟動一個Redis實例來分擔master的讀壓力,假設我們新啟動的這個實例叫slave。
已知M1的IP為127.0.0.1,端口為:8000首先我們先啟動redis實例,同時啟動一個客戶端連接這個實例:
$ ./redis-server --port 8001
$ ./redis-cli -p 8001
這個時候slave是沒有數據的:
127.0.0.1:8001> get msg
(nil)
我們可以用下面命令來讓slave和master進行復制:
127.0.0.1:8001> slaveof 127.0.0.1 8000
於是,slave就獲得了master上寫的數據了:
127.0.0.1:8001> get msg
"doni"
上面的例子和很直觀也很簡單,下面我們就在腦海中緩存這個應用場景,來看看redis是如何實現復制的。
處理slaveof
我們首先需要看看slave接收到客戶端的slaveof命令是如何處理的,下面是slave接收到客戶端的slaveof命令的處理流程圖:
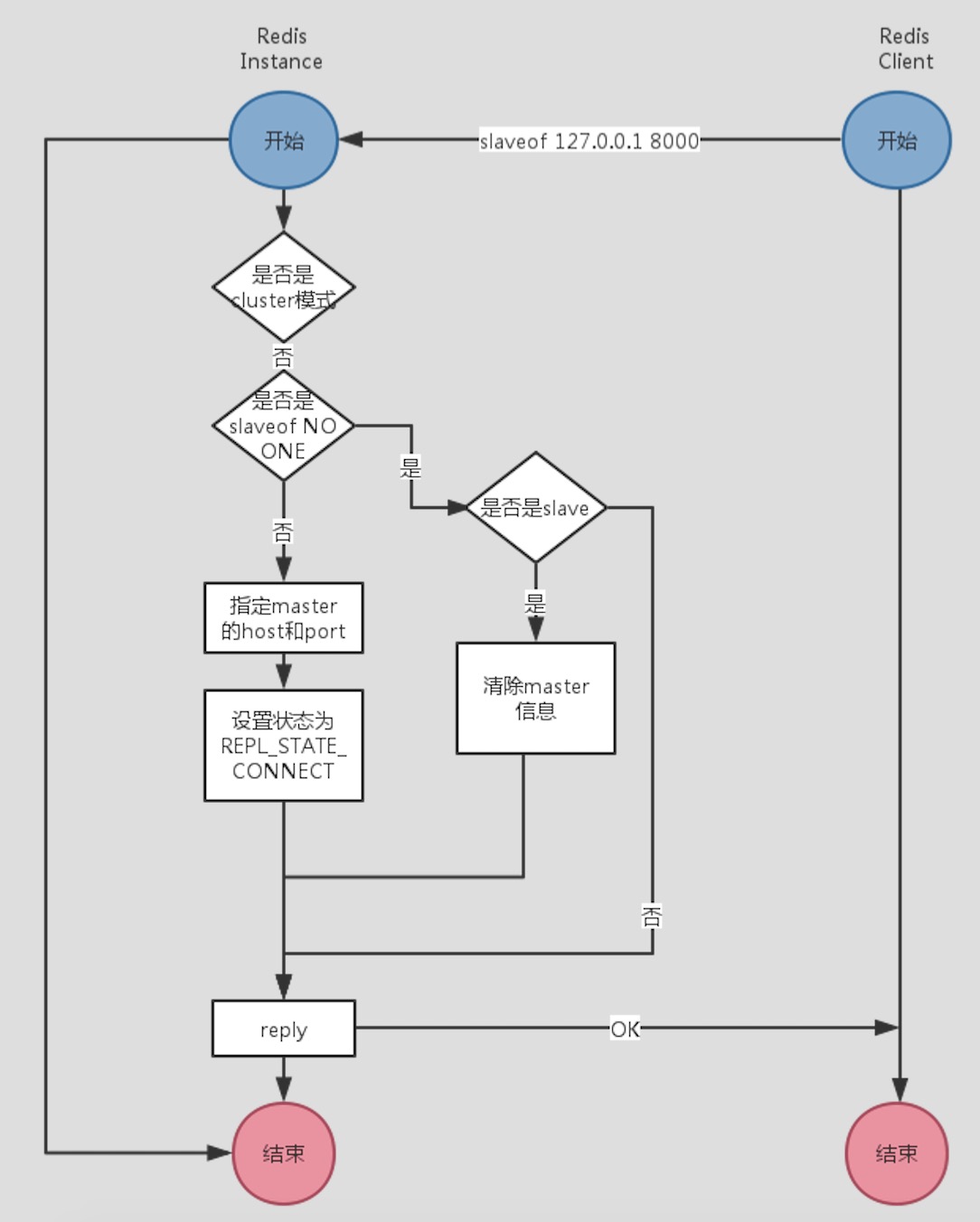
slaveof命令處理流程圖
解釋下上圖,redis實例接收到客戶端的slaveof命令後的處理流程大致如下:
- 判斷當前模式是否為cluster,如果是則不支持復制。
- 判斷命令是否為slave‘of no one,如果是,這表明客戶端把當前實例設置為master。
- 如果客戶端指定了host和port,則將host和port設置為當前的master信息。
- 將當前實例的復制狀態設置為REPL_STATE_CONNECT。
除了上面的幾個大步驟之外,在第二步和第三步之間還做了下面一些事情:
- 釋放之前被阻塞的客戶端,這些通常是使用Redis阻塞列表而被阻塞的客戶端。
- 斷開當前實例的所有slave。
- 清除緩存的master信息。
- 釋放backlog,backlog是堆積環形緩沖區。
- 取消正在進行的握手過程。
上面就是Redis處理slaveof命令的大致流程,誒,好像並沒有做關於復制的事情誒。別急,如果看過我的另一篇《Redis網絡架構及單線程模型》文章的同學都應該知道redis的單線線程模型,這裏slaveof命令處理關鍵的一步已經將當前redis實例的復制狀態設置為了REPL_STATE_CONNECT狀態,在redis的eventloop裏面自然會對處於這個狀態的redis實例進行處理。
連接master
復制異步處理的觸發邏輯一方面是I/O事件驅動的一部分,另一方面就是eventloop對時間事件處理的一部分,其實也是定時任務,redis定時任務最外面一層是serverCron方法,serverCron方法囊括了其他幾乎所有定時處理邏輯的入口,可以列個不完全列表如下:
- 過期key處理。
- 軟件watchdog。
- 更新統計信息。
- rehash。
- 觸發備份RDB文件或者AOF重寫邏輯。
- 客戶端超時處理。
- 復制邏輯。
- ……
我們這裏只關心復制邏輯,調用代碼如下:
run_with_period(1000) replicationCron();
run_with_period方法是redis封裝的一個幫助方法,最然serverCron的調用頻率很高,是1毫秒一次:
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) { serverPanic("Can‘t create event loop timers."); exit(1); }
但是redis通過run_with_period實現了可以並不是每隔1毫秒必須要執行所有邏輯,run_with_period方法指定了具體的執行時間間隔。上面可以看出,redis主進程大概是1000毫秒也就是1秒鐘執行一次replicationCron邏輯,replicationCron做什麽事情呢,它做的事情很多,我們只關心本文的主線邏輯:
if (server.repl_state == REPL_STATE_CONNECT) { if (connectWithMaster() == C_OK) { serverLog(LL_NOTICE,"MASTER <-> SLAVE sync started"); } }
如果當前實例的復制狀態為REPL_STATE_CONNECT,我們就會嘗試著連接剛才slaveof指定的master,連接master的主要實現在connectWithMaster裏面,connectWithMaster的邏輯相對簡單一些,大致做了下面三件事情:
- 和指定的master建立連接,獲取master的socket句柄,即fd。
- 註冊fd的讀寫事件,事件處理器為syncWithMaster。
- 設置當前實例的復制狀態為REPL_STATE_CONNECTING。
握手機制
上面已經註冊了當前實例和master的讀寫I/O事件即事件處理器,由於I/O事件分離相關邏輯都由系統框架完成,也就是eventloop,因此我們可以直接看當前實例針對master連接的I/O處理實現部分,也就是syncWithMaster處理器。
syncWithMaster主要實現了當前實例和master之間的握手協議,核心是賦值狀態遷移,我們可以用下面一張圖表示:

slave和msater的握手機制
上圖為slave在syncWithMaster階段做的事情,主要是和master進行握手,握手成功之後最後確定復制方案,中間涉及到遷移的狀態集合如下:
#define REPL_STATE_CONNECTING 2 /* 等待和master連接 */
/* --- 握手狀態開始 --- */
#define REPL_STATE_RECEIVE_PONG 3 /* 等待PING返回 */
#define REPL_STATE_SEND_AUTH 4 /* 發送認證消息 */
#define REPL_STATE_RECEIVE_AUTH 5 /* 等待認證回復 */
#define REPL_STATE_SEND_PORT 6 /* 發送REPLCONF信息,主要是當前實例監聽端口 */
#define REPL_STATE_RECEIVE_PORT 7 /* 等待REPLCONF返回 */
#define REPL_STATE_SEND_CAPA 8 /* 發送REPLCONF capa */
#define REPL_STATE_RECEIVE_CAPA 9 /* 等待REPLCONF返回 */
#define REPL_STATE_SEND_PSYNC 10 /* 發送PSYNC */
#define REPL_STATE_RECEIVE_PSYNC 11 /* 等待PSYNC返回 */
/* --- 握手狀態結束 --- */
#define REPL_STATE_TRANSFER 12 /* 正在從master接收RDB文件 */
當slave向master發送PSYNC命令之後,一般會得到三種回復,他們分別是:
- +FULLRESYNC:不好意思,需要全量復制哦。
- +CONTINUE:嘿嘿,可以進行增量同步。
- -ERR:不好意思,目前master還不支持PSYNC。
當slave和master確定好復制方案之後,slave註冊一個讀取RDB文件的I/O事件處理器,事件處理器為readSyncBulkPayload,然後將狀態設置為REPL_STATE_TRANSFER,這基本就是syncWithMaster的實現。
處理PSYNC
全量還是增量
我們已經知道slave是怎麽同master建立連接,怎麽和master進行握手的了,那麽master那邊是什麽情況呢,master在與slave握手之後,對於psync命令處理的秘密都在syncCommand方法裏面,syncCommand方法實際包括兩個命令處理的實現,一個是sync,一個是psync。我們繼續看看,master對slave的psync的請求處理,如果當前請求不滿足psync的條件,則需要進行全量復制,滿足psync的條件有兩個,一個是slave帶來的runid是否為當前master的runid:
if (strcasecmp(master_runid, server.runid)) { //如果slave帶來的runid“?”,說明slave想要強制走全量復制 if (master_runid[0] != ‘?‘) { serverLog(LL_NOTICE,"Partial resynchronization not accepted: " "Runid mismatch (Client asked for runid ‘%s‘, my runid is ‘%s‘)", master_runid, server.runid); } else { serverLog(LL_NOTICE,"Full resync requested by slave %s", replicationGetSlaveName(c)); } goto need_full_resync; }
如果不是,則需要全量同步。第二個條件即當前slave帶來的復制offset,master在backlog中是否還能找到:
if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) != C_OK) goto need_full_resync; if (!server.repl_backlog || psync_offset < server.repl_backlog_off || psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen)) { if (psync_offset > server.master_repl_offset) { //警告:slave帶過來的offset不滿足增量復制的條件 } goto need_full_resync; }
如果找不到,不好意思,還是需要全量復制的,如果兩個條件都滿足,master會告訴slave可以增量復制,回復+CONTINUE消息。
復制是否正在進行
如果在當前slave執行復制請求之前,恰好已經有其他的slave已經請求過了,且master這個時候正在進行子進程傳輸(包括RDB文件備份和socket傳輸),那麽分下面兩種情況處理:
- 如果復制方式是RDB disk方式,則找到當前master狀態為SLAVE_STATE_WAIT_BGSAVE_END的slave,復制這個slave的offset到當前slave的offset,這是為了當子進程完成RDB文件備份之後, 當前請求復制的slave可以和之前的slave一起進行master的復制操作。
- 如果復制方式是Diskless方式,則當前進來的slave並不會向上面那個slave這麽幸運了,因為基於socket的復制已經正在進行了,當前slave只能參與下一輪的子進程復制,且狀態為SLAVE_STATE_WAIT_BGSAVE_START。
如果沒有子進程正在復制,這裏針對RDB disk方式和diskless方式,又要分兩種情況討論:
- 如果是RDB disk方式,則啟動子進程進行RDB文件備份。
- 如果是diskless方式,則等待一段時間,也是為了盡可能讓後面的具有復制請求的slave一起進來,參與這一輪復制,復制開始由定時任務異步啟動復制。
子進程結束後處理
RDB disk方式,當子進程備份RDB文件完畢,什麽時候開始發送給slave的呢?diskless方式當子進程傳輸完畢,接下來又做什麽呢?對於RDB disk的方式,這裏涉及到一個I/O事件註冊的過程,也是由serverCron驅動的,當子進程結束之後,主進程會得知,然後通過backgroundSaveDoneHandler處理器來進行處理,針對RDB disk類型和diskless類型的復制,處理邏輯是不一樣的,我們分別來看看。
RDB disk方式後處理
對於RDB disk復制方式,後處理主要是註冊向slave發送RDB文件的處理器sendBulkToSlave:
if (aeCreateFileEvent(server.el, slave->fd, AE_WRITABLE, sendBulkToSlave, slave) == AE_ERR) { freeClient(slave); continue; }
然後RDB的文件發送由sendBulkToSlave處理器來完成,master對於RDB文件發送完畢之後會把slave的狀態設置為:online。這裏需要註意的是,在把slave設置為online狀態之後會註冊寫處理器,將堆積在reply的數據發送給slave:
if (aeCreateFileEvent(server.el, slave->fd, AE_WRITABLE, sendReplyToClient, slave) == AE_ERR) { freeClient(slave); return; }
這部分的內容即為RDB文件開始備份到發送給slave結束這段時間的增量數據,因此需要註冊I/O事件處理器,將這段時間累積的內容發送給slave,最終保持數據一致。
diskless方式後處理
diskless方式的後處理不同的是當子進程結束的時候,其實RDB文件已經傳輸完成了,而且其中做了些事情:
- 當slave通過接受完RDB文件之後發送一個REPLCONF ACK給master。
- master接收到slave的REPLCONF ACK之後,開始將緩存的增量數據發送給slave。
因此這裏不會註冊sendBulkToSlave處理器,只需要將slave設置為online即可。我們還可以發現不同的一點,對於累積部分的數據處理,RDB disk方式是由master主動發送給slave的,而對於diskless方式,master收到slave的REPLCONF ACK之後才會將累積的數據發送出去,這點有些不同。
當子進程結束,後處理的過程中還要考慮到一種情況:
無論是RDB disk方式還是diskless方式,如果復制已經開始了,後來的slave需要同master復制,這部分的slave怎麽辦呢怎麽辦呢,對於這類slave,slave的復制狀態為SLAVE_STATE_WAIT_BGSAVE_START,語義上表示當前slave等待復制的開始,對於這種情況,Redis會直接啟動子進程開始預備下一輪復制。
RDB文件傳輸協議
上面握手機制部分提到,當slave和master握手完畢之後註冊了個readSyncBulkPayload處理器,用於讀取master發送過來的RDB文件,RDB文件通過TCP連接傳輸,本質上是一個數據流,slave端是如何區分當前傳輸方式是RDB disk方式還是diskless方式的呢?實際上對於不同的復制方式,數據傳輸協議也是不同的,假設我們把這個長長的RDB文件流稱為RDB文件報文,我們來看看兩種方式的不同協議格式:

RDB文件傳輸協議
上面有兩種報文協議,第一種為RDB disk方式的RDB文件報文傳輸協議,TCP流以"$"開始,然後緊跟著報文的長度,以換行符結束,這樣slave客戶端讀取長度之後就知道要從TCP後續的流中讀取多少內容就算結束了。第二種為diskless復制方式的RDB文件報文傳輸協議,以"$EOF:"開頭,緊跟著40字節長度的隨機16進制字符串,RDB文件結尾也緊跟著同樣的40字節長度的隨機16進制字符串。slave客戶端分別由TCP數據流的頭部來判斷復制類型,然後根據不同的協議去解析RDB文件,當RDB文件傳輸完成之後,slave會將RDB文件保存在本地,然後載入,這樣slave就基本和master保持同步了。
總結
本文主要在了解Redis復制源碼的基礎之上介紹Redis復制的實現原理及一些細節,希望對大家有幫助。
註:本文由作者原創,如有疑問請聯系作者。
redis復制源碼註釋地址:
https://github.com/hongmoshui/redis
Redis復制實現原理