
YARN 記憶體引數終極詳解

YARN環境中應用程式JAR包衝突問題的分析及解決
Hadoop框架自身集成了很多第三方的JAR包庫。Hadoop框架自身啟動或者在執行使用者的MapReduce等應用程式時,會優先查詢Hadoop預置的JAR包。這樣的話,當用戶的應用程式使用的第三方庫已經存在於Hadoop框架的預置目錄,但是兩者的版本不同時,Hadoop會優先為應用程式載入Hadoop自身預置的JAR包,這種情況的結果是往往會導致應用程式無法正常執行。
下面從我們在實踐中遇到的一個實際問題出發,剖析Hadoop on YARN 環境下,MapReduce程式執行時JAR包查詢的相關原理,並給出解決JAR包衝突的思路和方法。
一、一個JAR包衝突的例項
我的一個MR程式需要使用jackson庫1.9.13版本的新介面:
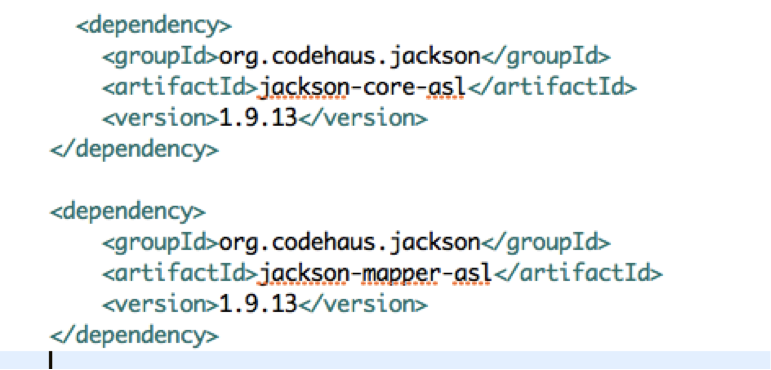
圖1:MR的pom.xml,依賴jackson的1.9.13
但是我的Hadoop叢集(CDH版本的hadoop-2.3.0-cdh5.1.0)預置的jackson版本是1.8.8的,位於Hadoop安裝目錄下的share/hadoop/mapreduce2/lib/下。
使用如下命令執行我的MR程式時:
hadoop jar mypackage-0.0.1-jar-with-dependencies.jar com.umeng.dp.MainClass --input=../input.pb.lzo --output=/tmp/cuiyang/output/
由於MR程式中使用的JsonNode.asText()方法,是1.9.13版本新加入的,在1.8.8版本中沒有,所以報錯如下:
…
15/11/13 18:14:33 INFO mapreduce.Job: map 0% reduce 0%
15/11/13 18:14:40 INFO mapreduce.Job: Task Id : attempt_1444449356029_0022_m_000000_0, Status : FAILED
Error: org.codehaus.jackson.JsonNode.asText()Ljava/lang/String;
…
二、搞清YARN框架執行應用程式的過程
在繼續分析如何解決JAR包衝突問題前,我們需要先搞明白一個很重要的問題,就是使用者的MR程式是如何在NodeManager上執行起來的?這是我們找出JAR包衝突問題的解決方法的關鍵。
本篇文章不是一篇介紹YARN框架的文章,一些基本的YARN的知識假定大家都已經知道,如ResourceManager(下面簡稱RM),NodeManager(下面簡稱NM),AppMaster(下面簡稱AM),Client,Container這5個最核心元件的功能及職責,以及它們之間的相互關係等等。
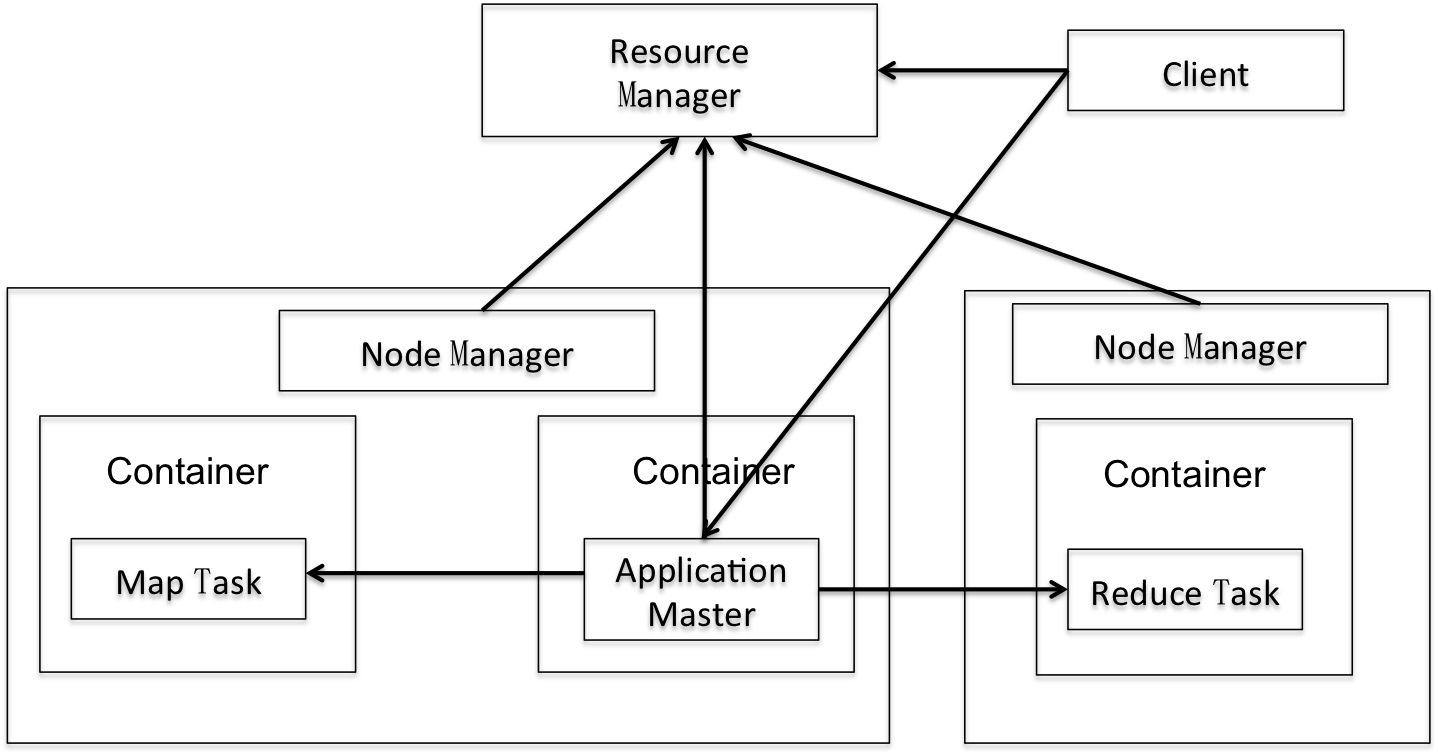
圖2:YARN架構圖
如果你對YARN的原理不是很瞭解也沒有關係,不會影響下面文章的理解。我對後面的文章會用到的幾個關鍵點知識做一個扼要的總結,明白這些關鍵點就可以了:
-
從邏輯角度來說,Container可以簡單地理解為是一個執行Map Task或者Reduce Task的程序(當然了,AM其實也是一個Container,是由RM命令NM執行的),YARN為了抽象化不同的框架應用,設計了Container這個通用的概念;
-
Container是由AM向NM傳送命令進行啟動的;
-
Container其實是一個由Shell指令碼啟動的程序,腳本里面會執行Java程式,來執行Map Task或者Reduce Task。
好了,讓我們開始講解MR程式在NM上執行的過程。
上面說到,Map Task或者Reduce Task是由AM傳送到指定NM上,並命令NM執行的。NM收到AM的命令後,會為每個Container建立一個本地目錄,將程式檔案及資原始檔下載到NM的這個目錄中,然後準備執行Task,其實就是準備啟動一個Container。NM會為這個Container動態生成一個名字為launch_container.sh的指令碼檔案,然後執行這個指令碼檔案。這個檔案就是讓我們看清Container到底是如何執行的關鍵所在!
指令碼內容中和本次問題相關的兩行如下:
export CLASSPATH="$HADOOP_CONF_DIR:$HADOOP_COMMON_HOME/share/hadoop/common/*:(...省略…):$PWD/*"
exec /bin/bash -c "$JAVA_HOME/bin/java -D(各種Java引數) org.apache.hadoop.mapred.YarnChild 127.0.0.1 58888 (其他應用引數)"
先看第2行。原來,在YARN執行MapReduce時,每個Container就是一個普通的Java程式,Main程式入口類是:org.apache.hadoop.mapred.YarnChild。
我們知道,JVM載入類的時候,會依據CLASSPATH中路徑的宣告順序,依次尋找指定的類路徑,直到找到第一個目標類即會返回,而不會再繼續查詢下去。也就是說,如果兩個JAR包都有相同的類,那麼誰宣告在CLASSPATH前面,就會載入誰。這就是我們解決JAR包衝突的關鍵!
再看第1行,正好是定義JVM執行時需要的CLASSPATH變數。可以看到,YARN將Hadoop預置JAR包的目錄都寫在了CLASSPATH的最前面。這樣,只要是Hadoop預置的JAR包中包含的類,就都會優先於應用的JAR包中具有相同類路徑的類進行載入!
那對於應用中獨有的類(即Hadoop沒有預置的類),JVM是如何載入到的呢?看CLASSPATH變數定義的結尾部分:"/*:$PWD/*"。也就是說,如果Java類在其他地方都找不到的話,最後會在當前目錄查詢。
那當前目錄究竟是什麼目錄呢?上面提到過,NM在執行Container前,會為Container建立一個單獨的目錄,然後會將所需要的資源放入這個目錄,然後執行程式。這個目錄就是存放Container所有相關資源、程式檔案的目錄,也就是launch_container.sh指令碼執行時的當前目錄。如果你執行程式的時候,傳入了-libjars引數,那麼指定的JAR檔案,也會被拷貝到這個目錄下。這樣,JVM就可以通過CLASSPATH變數,查詢當前目錄下的所有JAR包,於是就可以載入使用者自引用的JAR包了。
在我的電腦中執行一次應用時,該目錄位於/Users/umeng/worktools/hadoop-2.3.0-cdh5.1.0/ops/tmp/hadoop-umeng/nm-local-dir/usercache/umeng/appcache/application_1444449356029_0023,內容如下(可以通過配置檔案進行配置,從略):
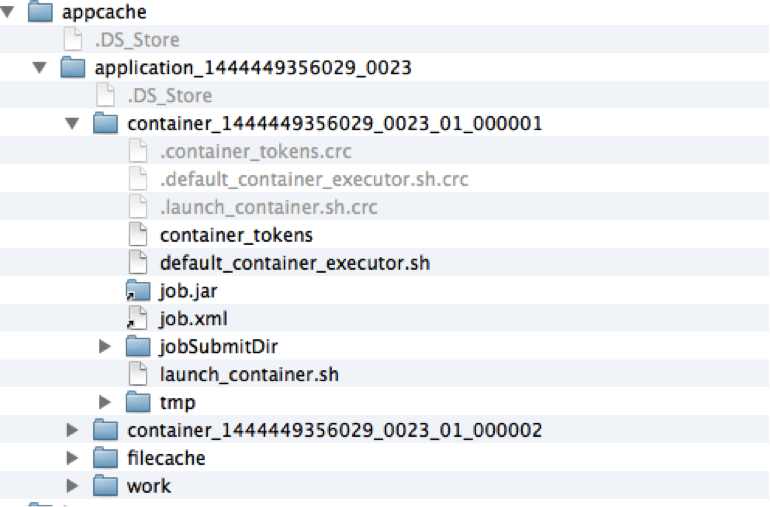
圖3:NM中Job執行時的目錄
好了,我們現在已經知道了為何YARN總是載入Hadoop預置的class及JAR包,那我們如何解決這個問題呢?方法就是:看原始碼!找到動態生成launch_container.sh的地方,看是否可以調整CLASSPATH變數的生成順序,將Job執行時的當前目錄,調整到CLASSPATH的最前面。
三、閱讀原始碼, 解決問題
追溯原始碼,讓我們深入其中,透徹一切。
首先想到,雖然launch_container.sh指令碼檔案是由NM生成的,但是NM只是執行Task的載體,而真正精確控制Container如何執行的,應該是程式的大腦:AppMaster。檢視原始碼,果然驗證了我們的想法:Container的CLASSPATH,是由MRApps(MapReduce的AM)傳給NodeManager的,NodeManager再寫到sh指令碼中。
MRApps中的TaskAttemptImpl::createCommonContainerLaunchContext()方法會建立一個Container,之後這個Container會被序列化後直接傳遞給NM;這個方法的實現中,呼叫關係為:createContainerLaunchContext() -> getInitialClasspath()-> MRApps.setClasspath(env, conf)。首先,我們來看setClasspath():
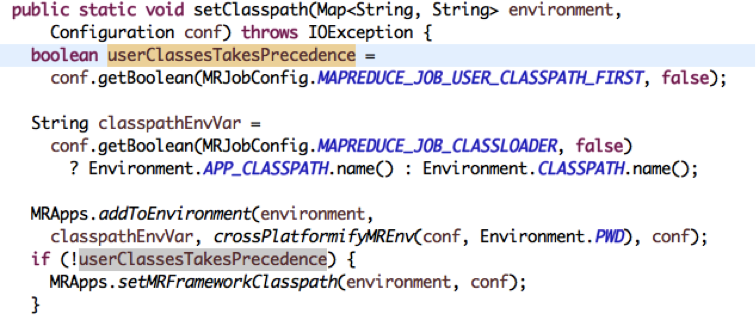
首先,會判斷userClassesTakesPrecedence,如果設定了這個Flag,那麼就不會去呼叫MRApps.setMRFrameworkClasspath(environment, conf)這個方法。也就是說,如果設定了這個Flag的話,需要使用者設定所有的JAR包的CLASSPATH。
下面看setMRFrameworkClasspath()方法:
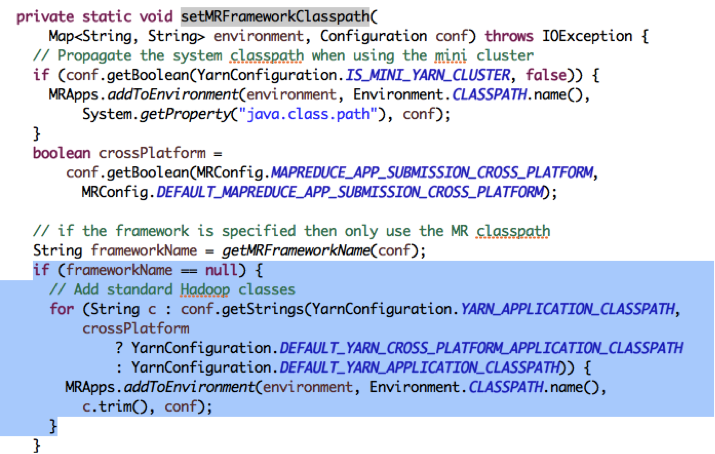
其中,DEFAULT_YARN_APPLICATION_CLASSPATH裡放入了所有Hadoop預置JAR包的目錄。能夠看到,框架會先用YarnConfiguration.YARN_APPLICATION_CLASSPATH設定的CLASSPATH,如果沒有設定,則會使用DEFAULT_YARN_APPLICATION_CLASSPATH。
然後由conf.getStrings()把配置字串按逗號分隔轉化為一個字串陣列;Hadoop遍歷該陣列,依次呼叫MRApps.addToEnvironment(environment, Environment.CLASSPATH.name(), c.trim(), conf)設定CLASSPATH。
看到這裡,我們看到了一線曙光:預設情況下,MRApps會使用DEFAULT_YARN_APPLICATION_CLASSPATH作為Task的預設CLASSPATH。如果我們想改變CLASSPATH,那麼看來我們就需要修改YARN_APPLICATION_CLASSPATH,讓這個變數不為空。
於是,我們在應用程式中加入瞭如下語句:
String[] classpathArray = config.getStrings(YarnConfiguration.YARN_APPLICATION_CLASSPATH, YarnConfiguration.DEFAULT_YARN_APPLICATION_CLASSPATH);
String cp = "$PWD/*:" + StringUtils.join(":", classpathArray);
config.set(YarnConfiguration.YARN_APPLICATION_CLASSPATH, cp);
上面的語句意思是:先獲得YARN預設的設定DEFAULT_YARN_APPLICATION_CLASSPATH,然後在開頭加上Task程式執行的當前目錄,然後一起設定給YARN_APPLICATION_CLASSPATH變數。這樣,MRApps在建立Container時,就會將我們修改過的、程式當前目錄優先的CLASSPATH,作為Container執行時的CLASSPATH。
最後一步,我們需要將我們的應用依賴的JAR包,放入到Task執行的目錄中,這樣載入類的時候,才能載入到我們真正需要的類。那如何做到呢?對,就是使用-libjars這個引數,這個前面也已經解釋過了。這樣,執行程式的命令就改為如下:
hadoop jar ./target/mypackage-0.0.1-SNAPSHOT-jar-with-dependencies.jar com.umeng.dp.MainClass-libjars jackson-mapper-asl-1.9.13.jar,jackson-core-asl-1.9.13.jar --input=../input.pb.lzo --output=/tmp/cuiyang/output/
四、結語
本文中,我們通過分析Hadoop的原始碼,解決了我們遇到的一個JAR包衝突問題。
即使再成熟再完善的文件手冊,也不可能涵蓋其產品所有的細節以解答使用者所有的問題,更何況是Hadoop這種非以盈利為目的的開源框架。而開源的好處就是,在你困惑的時候,你可以求助原始碼,自己找到問題的答案。這正如侯捷老師所說的: “原始碼面前,了無祕密”。
YARN 記憶體引數終極詳解
很多朋友在剛開始搭建和使用 YARN 叢集的時候,很容易就被紛繁複雜的配置引數搞暈了:引數名稱相近、新老命名摻雜、文件說明模糊 。特別是那幾個關於記憶體的配置引數,即使看好幾遍文件也不能完全弄懂含義不說,配置時一不小心就會張冠李戴,犯錯誤。
如果你同樣遇到了上面的問題,沒有關係,在這篇文章中,我就為大家梳理一下 YARN 的幾個不易理解的記憶體配置引數,並結合原始碼闡述它們的作用和原理,讓大家徹底清楚這些引數的含義。
一、YARN 的基本架構
介紹 YARN 框架的介紹文章網上隨處都可以找到,我這裡就不做詳細闡述了。之前我的文章“YARN環境中應用程式JAR包衝突問題的分析及解決”中也對 YARN 的一些知識點做了總結,大家可以在TheFortyTwo 後臺回覆編號 0x0002 獲得這篇文章的推送。下面附上一張 YARN 框架圖,方便引入我們的後續內容:
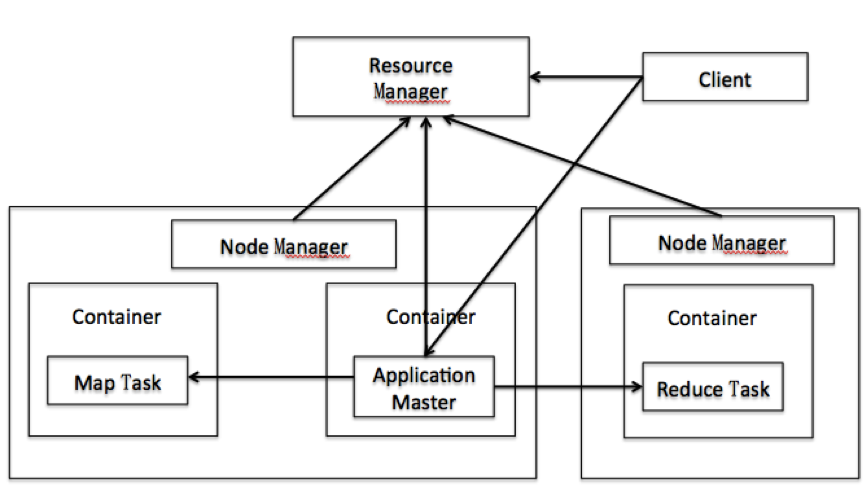 圖 1: YARN 架構圖
圖 1: YARN 架構圖
二、記憶體相關引數梳理
YARN 中關於記憶體配置的引數呢,乍一看有很多,其實主要也就是那麼幾個(如果你感覺實際接觸到的比這更多更混亂,是因為大部分的配置引數都有新命名和舊命名,我後面會分別解釋),我已經整理出來列在了下表中。大家先看一下,對於表中各列的意義,我會在本節後面詳細說明;而對於每個引數的意義,我會放在下節進行詳細解釋。
圖 2: 記憶體引數整理圖
下面我們解釋一下表中的各列:
配置物件:指引數是針對何種元件起作用;
引數名稱:這個不用解釋,大家都明白;
舊引數名稱:大家都知道,MapReduce 在大版本上,經歷了 MR1 和 MR on YARN;而小版本則迭代了不計其數次。版本的演進過程中,開發人員發現很多引數的命名不夠標準,就對引數名稱做了修改;但是為了保證程式的前後相容,仍然保留了舊引數名稱的功能。這樣等於是實現同一個功能的引數,就有了新舊兩種不同的名稱。比如 mapreduce.map.java.opts 和 mapred.map.child.java.opts 兩個引數,其實是等價的。那如果新舊兩個引數都設定了情況下,哪個引數會實際生效呢?Hadoop 的規則是,新引數設定了的話,會使用新引數,否則才會使用舊引數設定的值,而與你設定引數的順序無關;
預設值:如果沒有設定引數的話,Hadoop 使用的預設值。需要注意的是,並非所有引數的預設值都是寫在配置檔案(如 mapred-default.xml)中的,比如 mapreduce.map.java.opts 這個引數,它的取值是在建立 Map Task 前,通過下面程式碼獲得的:
if (isMapTask) {
userClasspath = jobConf.get(“mapreduce.map.java.opts”,
jobConf.get( “mapred.child.java.opts”, “-Xmx200m"));
…
}
可以看到,這個引數的取值優先順序是:
mapreduce.map.java.opts > mapred.child.java.opts > -Xmx200m
所在配置檔案:指明瞭如果你想靜態配置這個引數(而非在程式中呼叫 API 動態設定引數),應該在哪個配置檔案中進行設定比較合適;
三、各引數終極解釋
下面我們分別來講解每個引數的功能和意義。
mapreduce.map.java.opts 和 mapreduce.map.memory.mb
我反覆斟酌了一下,覺得這兩個引數還是要放在一起講才容易讓大家理解,否則割裂開會讓大家困惑更大。這兩個引數的功能如下:
-
mapreduce.map.java.opts: 執行 Map 任務的 JVM 引數,例如 -Xmx 指定最大記憶體大小;
-
mapreduce.map.memory.mb: Container 這個程序的最大可用記憶體大小。
這兩個引數是怎樣一種聯絡呢?首先大家要了解 Container 是一個什麼樣的程序(想詳細瞭解的話,就真的需要大家去看我的另一篇文章“YARN環境中應用程式JAR包衝突問題的分析及解決”,回覆編號0x0002)。簡單地說,Container 其實就是在執行一個指令碼檔案(launch_container.sh),而指令碼檔案中,會執行一個 Java 的子程序,這個子程序就是真正的 Map Task。
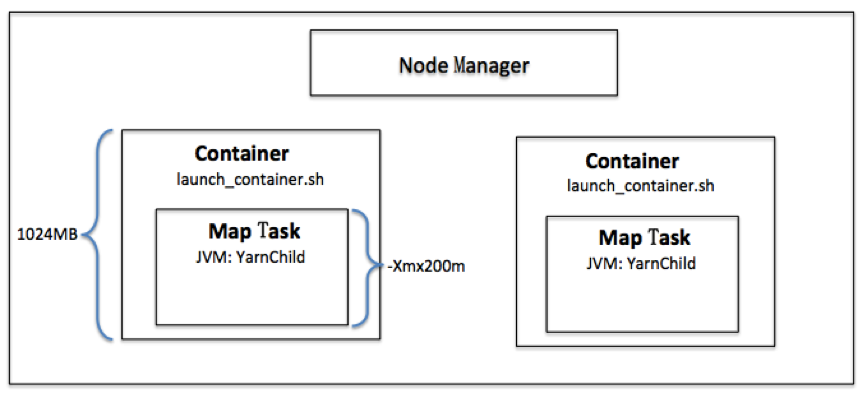
圖 3: Container 和 Map Task 的關係圖
理解了這一點大家就明白了,mapreduce.map.java.opts 其實就是啟動 JVM 虛擬機器時,傳遞給虛擬機器的啟動引數,而預設值 -Xmx200m 表示這個 Java 程式可以使用的最大堆記憶體數,一旦超過這個大小,JVM 就會丟擲 Out of Memory 異常,並終止程序。而 mapreduce.map.memory.mb 設定的是 Container 的記憶體上限,這個引數由 NodeManager 讀取並進行控制,當 Container 的記憶體大小超過了這個引數值,NodeManager 會負責 kill 掉 Container。在後面分析 yarn.nodemanager.vmem-pmem-ratio 這個引數的時候,會講解 NodeManager 監控 Container 記憶體(包括虛擬記憶體和實體記憶體)及 kill 掉 Container 的過程。
緊接著,一些深入思考的讀者可能就會提出這些問題了:
Q: 上面說過,Container 只是一個簡單的指令碼程式,且裡面僅運行了一個 JVM 程式,那麼為何還需要分別設定這兩個引數,而不能簡單的設定 JVM 的記憶體大小就是 Container的大小?
A: YARN 作為一個通用的計算平臺,設計之初就考慮了各種語言的程式運行於這個平臺之上,而非僅適用 Java 及 JVM。所以 Container 被設計成一個抽象的計算單元,於是它就有了自己的記憶體配置引數。
Q: JVM 是作為 Container 的獨立子程序執行的,與 Container 是兩個不同的程序。那麼 JVM 使用的記憶體大小是否受限於 Container 的記憶體大小限制?也就是說,mapreduce.map.java.opts 引數值是否可以大於 mapreduce.map.memory.mb 的引數值?
A: 這就需要了解 NodeManager 是如何管理 Container 記憶體的了。NodeManager 專門有一個 monitor 執行緒,時刻監控所有 Container 的實體記憶體和虛擬記憶體的使用情況,看每個 Container 是否超過了其預設的記憶體大小。而計算 Container 記憶體大小的方式,是計算 Container 的所有子程序所用記憶體的和。上面說過了,JVM 是 Container 的子程序,那麼 JVM 程序使用的記憶體大小,當然就算到了 Container 的使用記憶體量之中。一旦某個 Container 使用的記憶體量超過了其預設的記憶體量,則 NodeManager 就會無情地 kill 掉它。
mapreduce.reduce.java.opts 和 mapred.job.reduce.memory.mb
和上面介紹的引數類似,區別就是這兩個引數是針對 Reducer 的。
mapred.child.java.opts
這個引數也已經是一箇舊的引數了。在老版本的 MR 中,Map Task 和 Reduce Task 的 JVM 記憶體配置引數不是分開的,由這個引數統一指定。也就是說,這個引數其實已經分成了 mapreduce.map.java.opts 和 mapreduce.reduce.java.opts 兩個,分別控制 Map Task 和 Reduce Task。但是為了前後相容,這個引數在 Hadoop 原始碼中仍然被使用,使用的地方上面章節已經講述過了,這裡再把優先順序列一下:
mapreduce.map.java.opts > mapred.child.java.opts > -Xmx200m
yarn.nodemanager.resource.memory-mb
從這個引數開始,我們來看 NodeManager 的配置項。
這個引數其實是設定 NodeManager 預備從本機申請多少記憶體量的,用於所有 Container 的分配及計算。這個引數相當於一個閾值,限制了 NodeManager 能夠使用的伺服器的最大記憶體量,以防止 NodeManager 過度消耗系統記憶體,導致最終伺服器宕機。這個值可以根據實際伺服器的配置及使用,適度調整大小。例如我們的伺服器是 96GB 的記憶體配置,上面部署了 NodeManager 和 HBase,我們為 NodeManager 分配了 52GB 的記憶體。
yarn.nodemanager.vmem-pmem-ratio 和 yarn.nodemanager.vmem-check-enabled
yarn.nodemanager.vmem-pmem-ratio 這個引數估計是最讓人困惑的了。網上搜出的資料大都出自官方文件的解釋,不夠清晰明徹。下面我結合原始碼和大家解釋一下這個引數到底在控制什麼。
首先,NodeManager 接收到 AppMaster 傳遞過來的 Container 後,會用 Container 的實體記憶體大小 (pmem) * yarn.nodemanager.vmem-pmem-ratio 得到 Container 的虛擬記憶體大小的限制,即為 vmemLimit:
long pmemBytes = container.getResource().getMemory() * 1024 * 1024L;
float pmemRatio = container.daemonConf.getFloat(YarnConfiguration.NM_VMEM_PMEM_RATIO, YarnConfiguration.DEFAULT_NM_VMEM_PMEM_RATIO);
long vmemBytes = (long) (pmemRatio * pmemBytes);
然後,NodeManager 在 monitor 執行緒中監控 Container 的 pmem(實體記憶體)和 vmem(虛擬記憶體)的使用情況。如果當前 vmem 大於 vmemLimit 的限制,或者 olderThanAge(與 JVM 記憶體分代相關)的記憶體大於限制,則 kill 掉程序:
if (currentMemUsage > (2 * vmemLimit)) {
isOverLimit = true;
} else if (curMemUsageOfAgedProcesses > vmemLimit) {
isOverLimit = true;
}
kill 程序的程式碼如下:
if (isMemoryOverLimit) {
// kill the container
eventDispatcher.getEventHandler().handle(new ContainerKillEvent(containerId, msg));
}
上述控制是針對虛擬記憶體的,針對實體記憶體的使用 YARN 也有類似的監控,讀者可以自行從原始碼中進行探索。yarn.nodemanager.vmem-check-enabled 引數則十分簡單,就是上述監控的開關。
上面的介紹提到了 vmemLimit,也許大家會有個疑問:這裡的 vmem 究竟是否是 OS 層面的虛擬記憶體概念呢?我們來看一下原始碼是怎麼做的。
ContainerMontor 就是上述所說的 NodeManager 中監控每個 Container 記憶體使用情況的 monitor,它是一個獨立執行緒。ContainerMonitor 獲得單個 Container 記憶體(包括實體記憶體和虛擬記憶體)使用情況的邏輯如下:
Monitor 每隔 3 秒鐘就更新一次每個 Container 的使用情況;更新的方式是:
-
檢視 /proc/pid/stat 目錄下的所有檔案,從中獲得每個程序的所有資訊;
-
根據當前 Container 的 pid 找出其所有的子程序,並返回這個 Container 為根節點,子程序為葉節點的程序樹;在 Linux 系統下,這個程序樹儲存在 ProcfsBasedProcessTree 類物件中;
-
然後從 ProcfsBasedProcessTree 類物件中獲得當前程序 (Container) 總虛擬記憶體量和實體記憶體量。
由此大家應該立馬知道了,記憶體量是通過 /proc/pid/stat 檔案獲得的,且獲得的是該程序及其所有子程序的記憶體量。所以,這裡的 vmem 就是 OS 層面的虛擬記憶體概念。
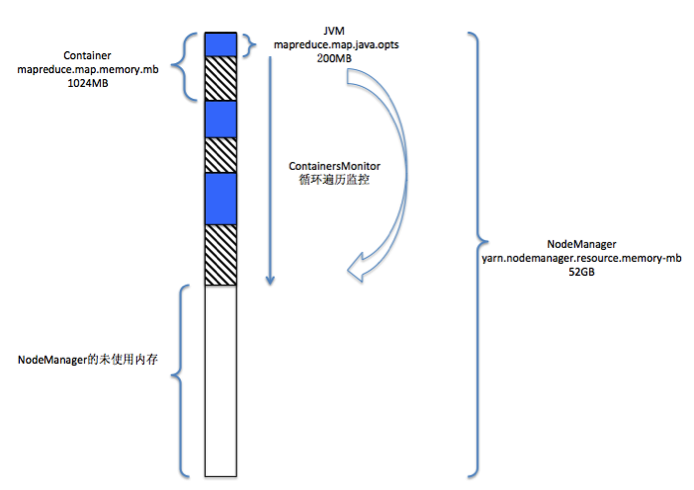
圖 4: 記憶體引數的組合示意圖
四、結語
本文帶大家深入剖析了 YARN 中幾個容易混淆的記憶體引數,大家可以見微知著,從文章分析問題的角度找出同類問題的分析方法,文件與原始碼相結合,更深入瞭解隱藏在框架之下的祕密。