
深入理解JVM的記憶體結構及GC機制

一、前言
JAVA GC(Garbage Collection,垃圾回收)機制是區別C++的一個重要特徵,C++需要開發者自己實現垃圾回收的邏輯,而JAVA開發者則只需要專注於業務開發,因為垃圾回收這件繁瑣的事情JVM已經為我們代勞了,從這一點上來說,JAVA還是要做的比較完善一些。但這並不意味著我們不用去理解GC機制的原理,因為如果不瞭解其原理,可能會引發記憶體洩漏、頻繁GC導致應用卡頓,甚至出現OOM等問題,因此我們需要深入理解其原理,才能編寫出高效能的應用程式,解決效能瓶頸。
想要理解GC的原理,我們必須先理解JVM記憶體管理機制,因為這樣我們才能知道回收哪些物件、什麼時候回收以及怎麼回收。
二、JVM記憶體管理
根據JVM規範,JVM把記憶體劃分成瞭如下幾個區域:
1.方法區(Method Area)
2.堆區(Heap)
3.虛擬機器棧(VM Stack)
4.本地方法棧(Native Method Stack)
5.程式計數器(Program Counter Register)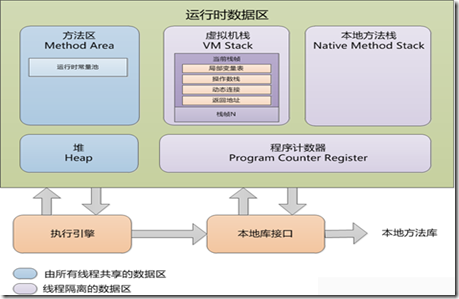
其中,方法區和堆所有執行緒共享。
2.1 方法區(Method Area)
方法區存放了要載入的類的資訊(如類名、修飾符等)、靜態變數、建構函式、final定義的常量、類中的欄位和方法等資訊。方法區是全域性共享的,在一定條件下也會被GC。當方法區超過它允許的大小時,就會丟擲OutOfMemory:PermGen Space異常。
在Hotspot虛擬機器中,這塊區域對應持久代(Permanent Generation),一般來說,方法區上執行GC的情況很少,因此方法區被稱為持久代的原因之一,但這並不代表方法區上完全沒有GC,其上的GC主要針對常量池的回收和已載入類的解除安裝。在方法區上進行GC,條件相當苛刻而且困難。
執行時常量池(Runtime Constant Pool)是方法區的一部分,用於儲存編譯器生成的常量和引用。一般來說,常量的分配在編譯時就能確定,但也不全是,也可以儲存在執行時期產生的常量。比如String類的intern()方法,作用是String類維護了一個常量池,如果呼叫的字元”hello”已經在常量池中,則直接返回常量池中的地址,否則新建一個常量加入池中,並返回地址。
2.2 堆區(Heap)
堆區是GC最頻繁的,也是理解GC機制最重要的區域。堆區由所有執行緒共享,在虛擬機器啟動時建立。堆區主要用於存放物件例項及陣列,所有new出來的物件都儲存在該區域。
2.3 虛擬機器棧(VM Stack)
虛擬機器棧佔用的是作業系統記憶體,每個執行緒對應一個虛擬機器棧,它是執行緒私有的,生命週期和執行緒一樣,每個方法被執行時產生一個棧幀(Statck Frame),棧幀用於儲存區域性變量表、動態連結、運算元和方法出口等資訊,當方法被呼叫時,棧幀入棧,當方法呼叫結束時,棧幀出棧。
區域性變量表中儲存著方法相關的區域性變數,包括各種基本資料型別及物件的引用地址等,因此他有個特點:記憶體空間可以在編譯期間就確定,執行時不再改變。
虛擬機器棧定義了兩種異常型別:StackOverFlowError(棧溢位)和OutOfMemoryError(記憶體溢位)。如果執行緒呼叫的棧深度大於虛擬機器允許的最大深度,則丟擲StackOverFlowError;不過大多數虛擬機器都允許動態擴充套件虛擬機器棧的大小,所以執行緒可以一直申請棧,直到記憶體不足時,丟擲OutOfMemoryError。
2.4 本地方法棧(Native Method Stack)
本地方法棧用於支援native方法的執行,儲存了每個native方法的執行狀態。本地方法棧和虛擬機器棧他們的執行機制一致,唯一的區別是,虛擬機器棧執行Java方法,本地方法棧執行native方法。在很多虛擬機器中(如Sun的JDK預設的HotSpot虛擬機器),會將虛擬機器棧和本地方法棧一起使用。
2.5 程式計數器(Program Counter Register)
程式計數器是一個很小的記憶體區域,不在RAM上,而是直接劃分在CPU上,程式猿無法操作它,它的作用是:JVM在解釋位元組碼(.class)檔案時,儲存當前執行緒執行的位元組碼行號,只是一種概念模型,各種JVM所採用的方式不一樣。位元組碼直譯器工作時,就是通過改變程式計數器的值來取下一條要執行的指令,分支、迴圈、跳轉等基礎功能都是依賴此技術區完成的。
每個程式計數器只能記錄一個執行緒的行號,因此它是執行緒私有的。
如果程式當前正在執行的是一個java方法,則程式計數器記錄的是正在執行的虛擬機器位元組碼指令地址,如果執行的是native方法,則計數器的值為空,此記憶體區是唯一不會丟擲OutOfMemoryError的區域。
三、GC機制
隨著程式的執行,記憶體中的例項物件、變數等佔據的記憶體越來越多,如果不及時進行回收,會降低程式執行效率,甚至引發系統異常。
在上面介紹的五個記憶體區域中,有3個是不需要進行垃圾回收的:本地方法棧、程式計數器、虛擬機器棧。因為他們的生命週期是和執行緒同步的,隨著執行緒的銷燬,他們佔用的記憶體會自動釋放。所以,只有方法區和堆區需要進行垃圾回收,回收的物件就是那些不存在任何引用的物件。
3.1 查詢演算法
經典的引用計數演算法,每個物件新增到引用計數器,每被引用一次,計數器+1,失去引用,計數器-1,當計數器在一段時間內為0時,即認為該物件可以被回收了。但是這個演算法有個明顯的缺陷:當兩個物件相互引用,但是二者都已經沒有作用時,理應把它們都回收,但是由於它們相互引用,不符合垃圾回收的條件,所以就導致無法處理掉這一塊記憶體區域。因此,Sun的JVM並沒有採用這種演算法,而是採用一個叫——根搜尋演算法,如圖:
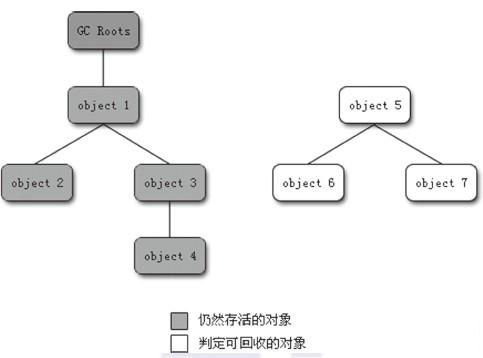
基本思想是:從一個叫GC Roots的根節點出發,向下搜尋,如果一個物件不能達到GC Roots的時候,說明該物件不再被引用,可以被回收。如上圖中的Object5、Object6、Object7,雖然它們三個依然相互引用,但是它們其實已經沒有作用了,這樣就解決了引用計數演算法的缺陷。
補充概念,在JDK1.2之後引入了四個概念:強引用、軟引用、弱引用、虛引用。
強引用:new出來的物件都是強引用,GC無論如何都不會回收,即使丟擲OOM異常。
軟引用:只有當JVM記憶體不足時才會被回收。
弱引用:只要GC,就會立馬回收,不管記憶體是否充足。
虛引用:可以忽略不計,JVM完全不會在乎虛引用,你可以理解為它是來湊數的,湊夠”四大天王”。它唯一的作用就是做一些跟蹤記錄,輔助finalize函式的使用。
最後總結,什麼樣的類需要被回收:
a.該類的所有例項都已經被回收;
b.載入該類的ClassLoad已經被回收;
c.該類對應的反射類java.lang.Class物件沒有被任何地方引用。
3.2 記憶體分割槽
記憶體主要被分為三塊:新生代(Youn Generation)、舊生代(Old Generation)、持久代(Permanent Generation)。三代的特點不同,造就了他們使用的GC演算法不同,新生代適合生命週期較短,快速建立和銷燬的物件,舊生代適合生命週期較長的物件,持久代在Sun Hotpot虛擬機器中就是指方法區(有些JVM根本就沒有持久代這一說法)。

新生代(Youn Generation):大致分為Eden區和Survivor區,Survivor區又分為大小相同的兩部分:FromSpace和ToSpace。新建的物件都是從新生代分配記憶體,Eden區不足的時候,會把存活的物件轉移到Survivor區。當新生代進行垃圾回收時會出發Minor GC(也稱作Youn GC)。
舊生代(Old Generation):舊生代用於存放新生代多次回收依然存活的物件,如快取物件。當舊生代滿了的時候就需要對舊生代進行回收,舊生代的垃圾回收稱作Major GC(也稱作Full GC)。
持久代(Permanent Generation):在Sun 的JVM中就是方法區的意思,儘管大多數JVM沒有這一代。
3.3 GC演算法
常見的GC演算法:複製、標記-清除和標記-壓縮
複製:複製演算法採用的方式為從根集合進行掃描,將存活的物件移動到一塊空閒的區域,如圖所示:
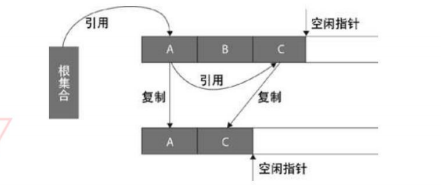
當存活的物件較少時,複製演算法會比較高效(新生代的Eden區就是採用這種演算法),其帶來的成本是需要一塊額外的空閒空間和物件的移動。
標記-清除:該演算法採用的方式是從跟集合開始掃描,對存活的物件進行標記,標記完畢後,再掃描整個空間中未被標記的物件,並進行清除。標記和清除的過程如下:
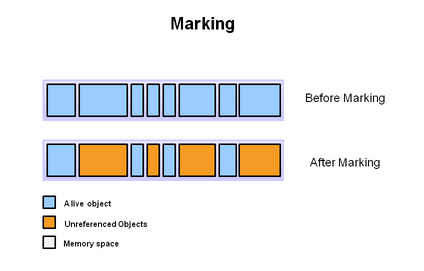
上圖中藍色部分是有被引用的物件,褐色部分是沒有被引用的物件。在Marking階段,需要進行全盤掃描,這個過程是比較耗時的。
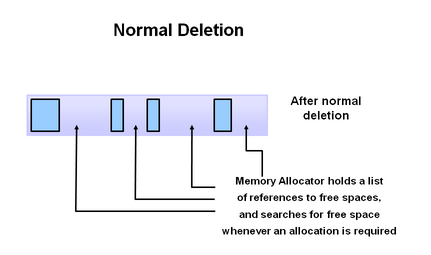
清除階段清理的是沒有被引用的物件,存活的物件被保留。
標記-清除動作不需要移動物件,且僅對不存活的物件進行清理,在空間中存活物件較多的時候,效率較高,但由於只是清除,沒有重新整理,因此會造成記憶體碎片。
標記-壓縮:該演算法與標記-清除演算法類似,都是先對存活的物件進行標記,但是在清除後會把活的物件向左端空閒空間移動,然後再更新其引用物件的指標,如下圖所示

由於進行了移動規整動作,該演算法避免了標記-清除的碎片問題,但由於需要進行移動,因此成本也增加了。(該演算法適用於舊生代)
四、垃圾收集器
在JVM中,GC是由垃圾回收器來執行,所以,在實際應用場景中,我們需要選擇合適的垃圾收集器,下面我們介紹一下垃圾收集器。
4.1 序列收集器(Serial GC)
Serial GC是最古老也是最基本的收集器,但是現在依然廣泛使用,JAVA SE5和JAVA SE6中客戶端虛擬機器採用的預設配置。比較適合於只有一個處理器的系統。在序列處理器中minor和major GC過程都是用一個執行緒進行回收的。它的最大特點是在進行垃圾回收時,需要對所有正在執行的執行緒暫停(stop the world),對於有些應用是難以接受的,但是如果應用的實時性要求不是那麼高,只要停頓的時間控制在N毫秒之內,大多數應用還是可以接受的,而且事實上,它並沒有讓我們失望,幾十毫秒的停頓,對於我們客戶機是完全可以接受的,該收集器適用於單CPU、新生代空間較小且對暫停時間要求不是特別高的應用上,是client級別的預設GC方式。
4.2 ParNew GC
基本和Serial GC一樣,但本質區別是加入了多執行緒機制,提高了效率,這樣它就可以被用於服務端上(server),同時它可以與CMS GC配合,所以,更加有理由將他用於server端。
4.3 Parallel Scavenge GC
在整個掃描和複製過程採用多執行緒的方式進行,適用於多CPU、對暫停時間要求較短的應用,是server級別的預設GC方式。
4.4 CMS (Concurrent Mark Sweep)收集器
該收集器的目標是解決Serial GC停頓的問題,以達到最短回收時間。常見的B/S架構的應用就適合這種收集器,因為其高併發、高響應的特點,CMS是基於標記-清楚演算法實現的。
CMS收集器的優點:併發收集、低停頓,但遠沒有達到完美;
CMS收集器的缺點:
a.CMS收集器對CPU資源非常敏感,在併發階段雖然不會導致使用者停頓,但是會佔用CPU資源而導致應用程式變慢,總吞吐量下降。
b.CMS收集器無法處理浮動垃圾,可能出現“Concurrnet Mode Failure”,失敗而導致另一次的Full GC。
c.CMS收集器是基於標記-清除演算法的實現,因此也會產生碎片。
4.5 G1收集器
相比CMS收集器有不少改進,首先,基於標記-壓縮演算法,不會產生記憶體碎片,其次可以比較精確的控制停頓。
4.6 Serial Old收集器
Serial Old是Serial收集器的老年代版本,它同樣使用一個單執行緒執行收集,使用“標記-整理”演算法。主要使用在Client模式下的虛擬機器。
4.7 Parallel Old收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多執行緒和“標記-整理”演算法。
4.8 RTSJ垃圾收集器
RTSJ垃圾收集器,用於Java實時程式設計。
五、總結
深入理解JVM的記憶體模型和GC機制有助於幫助我們編寫高效能程式碼和提供程式碼優化的思路