
HBase 架構與工作原理4 - 壓縮、分裂與故障恢復
本文系轉載,如有侵權,請聯系我:[email protected]
Compacation
HBase 在讀寫的過程中,難免會產生無效的數據以及過小的文件,比如:MemStore 在未達到指定大小便刷新數據以寫入到磁盤;或者當已經寫入 HFile 的數據被刪除後,原數據被標記了墓碑,卻仍然存在於 HFile 之中。在這些情況之下,我們需要清除無效的數據或者合並過小的文件來提高讀的性能。這種合並的過程也被稱為 compacation。
HBase 中使用的 compacation 方式主要分為以下兩種:
- Minor_compaction
- Major_compaction
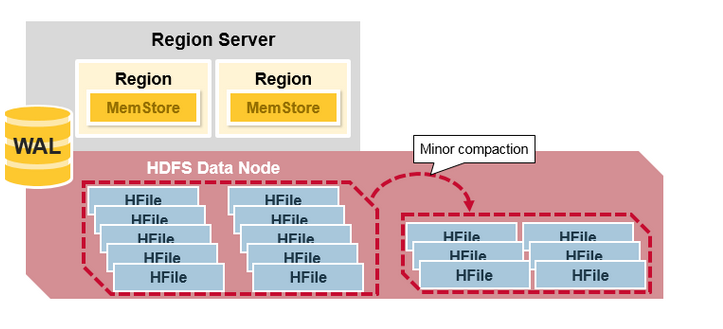
Minor_Compaction
HBase 會自動選擇一些較小的 HFile,並將它們重寫成更少的但更大的 HFiles 文件,這個過程被稱為 minor_compaction。minor_compaction 通過將少量的相鄰的 HFile 合並為單個 HFile 來達到壓縮操作,但是它不會刪除被標記為刪除或過期的數據。
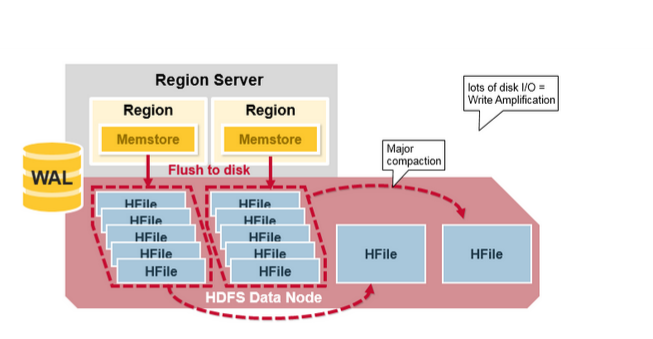
Major_Compaction
Major_Compaction 將 Region 中的所有 HFile 合並並重寫成一系列由列族(Column Family)組成的 HFile 文件,並在此過程刪除已被刪除或已過期的數據。這會提高讀取性能,但是由於 Major_compaction 會重寫所有文件,所以在此過程中可能會發生大量的磁盤 I/O 和網絡流量,這種現象被稱為寫入放大(write amplification)。
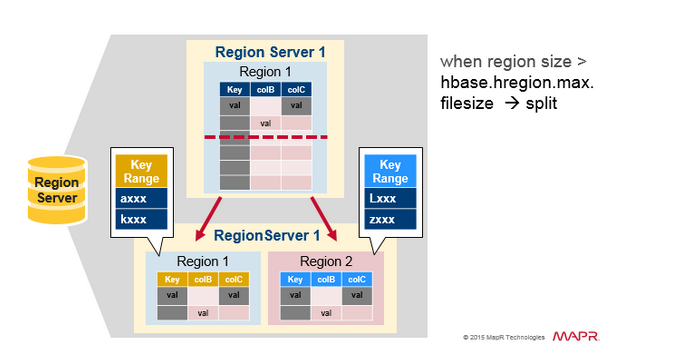
Region Split
最初,每一個 table 都會有一個 Region。隨著數據的不斷寫入,當這個 Region 變得太大時,它就會被分裂成兩個子 Regions。兩個子 Regions 各種擁有原 Region 的一半,它們會在相同的 RegionServer 上並行打開,然後將分區信息報告給 HMaster。處於負載均衡的原因,HMaster 可能會將新的 Region 移動到其它服務器。
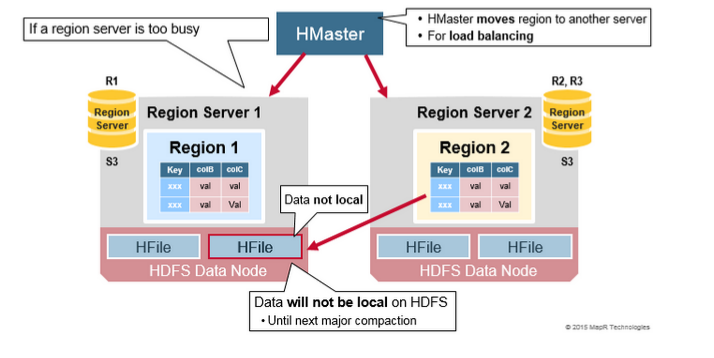
負載均衡
Split 最初發生在同一個 RegionServer 上,但是出於負載均衡的原因,HMaster 可能會將新的 Region 移動到其它服務器(移動元數據,而不是 HFile 文件)。這會導致新的 RegionServer 提供來自遠程 HDFS 節點的數據,直到 Major_compaction 時將數據文件移動到區域服務器的本地節點。
故障恢復
WAL 文件和 HFile 被保存在磁盤上並被復制,但是 MemStore 還沒有被保存在磁盤上,所以當 RegionServer 發生問題後,HBase 是如何恢復 MemStore 之中的數據呢?
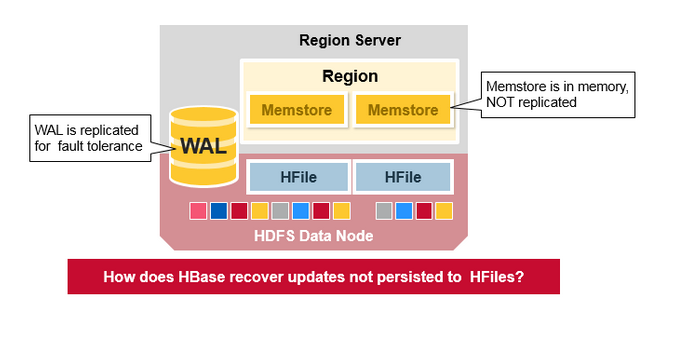
當 RegionServer 失敗時,崩潰的 Region 將不可用,直到檢查並恢復之後方可繼續使用。Zookeeper 會在失去 RegionServer 心跳時確定節點故障,HMaster 將會被通知 RegionServer 已經失敗。
註:當 RegionServer 失敗時,正在查詢該節點上的數據的操作會被重試,並且不會立即丟失。
當 HMaster 檢測到 RegionServer 已經崩潰時,HMaster 會將已崩潰的 RegionServer 上的 Regions 重新分配給活動的 RegionServer。為了恢復已崩潰的 RegionServer 上未刷新到磁盤的 MemStore 中的內容,HMaster 將屬於崩潰的 RegionServer 的 WAL 文件拆分成單獨的文件,並將這些文件存儲在新的 RegionServer 的 DataNode 上。然後新的 RegionServer 根據拆分後的 WAL 文件重播 WAL,以重建丟失的 MemStore 區域。
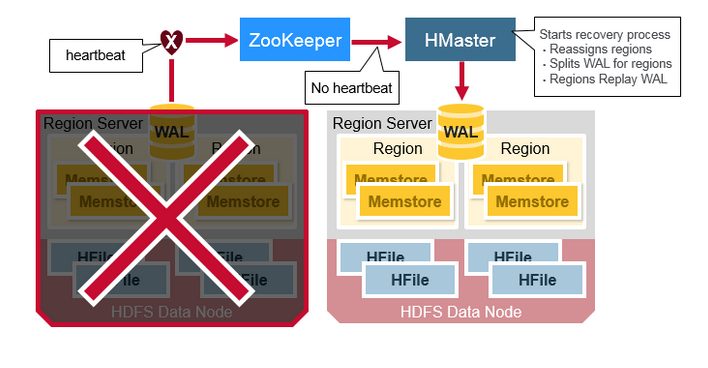
WAL 重播
WAL 文件包含編輯列表,一個編輯表示單個操作的 put 或者 delete。編輯按照時間順序寫入,並將附加到存儲在磁盤上的 WAL 文件的末尾。
如果數據仍在 MemStore 中並且未保存到 HFile 中時,將發生 WAL 重播。WAL 重播是通過讀取 WAL 文件,將其包含的編輯操作添加到當前的 MemStore 並進行排序來完成的。
參考鏈接
- An In-Depth Look at the HBase Architecture
- Apache HBase ™ Reference Guide
HBase 架構與工作原理4 - 壓縮、分裂與故障恢復