
zookeeper安裝以及遇到的一些坑
最近項目中用到了storm,然後storm中用到了zookeeper,然後今天抽空整理一下zookeeper的安裝使用,原來後期再慢慢學習。
本篇文檔,操作部分是摘自其他博客,裏邊的問題分析是自己在實踐過程中遇到然後特別記錄的!
----------------------------- 開始:
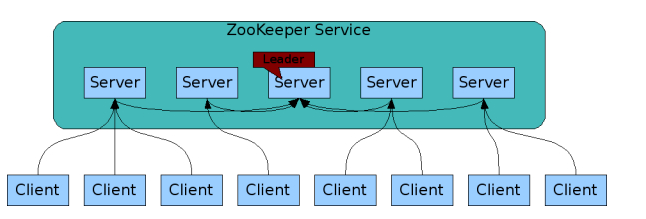
ZooKeeper是一個開放源碼的分布式應用程序協調服務,它包含一個簡單的原語集,分布式應用程序可以基於它實現同步服務,配置維護和命名服務等。
Zookeeper設計目的- 最終一致性:client不論連接到那個Server,展示給它的都是同一個視圖。
- 可靠性:具有簡單、健壯、良好的性能、如果消息m被到一臺服務器接收,那麽消息m將被所有服務器接收。
- 實時性:Zookeeper保證客戶端將在一個時間間隔範圍內獲得服務器的更新信息,或者服務器失效的信息。但由於網絡延時等原因,Zookeeper不能保證兩個客戶端能同時得到剛更新的數據,如果需要最新數據,應該在讀數據之前調用sync()接口。
- 等待無關(wait-free):慢的或者失效的client不得幹預快速的client的請求,使得每個client都能有效的等待。
- 原子性:更新只能成功或者失敗,沒有中間狀態。
- 順序性:包括全局有序和偏序兩種:全局有序是指如果在一臺服務器上消息a在消息b前發布,則在所有Server上消息a都將在消息b前被發布;偏序是指如果一個消息b在消息a後被同一個發送者發布,a必將排在b前面。
1、在zookeeper的集群中,各個節點共有下面3種角色和4種狀態:
角色:leader,follower,observer
狀態:leading,following,observing,looking
Zookeeper的核心是原子廣播,這個機制保證了各個Server之間的同步。實現這個機制的協議叫做Zab協議(ZooKeeper Atomic Broadcast protocol)。Zab協議有兩種模式,它們分別是恢復模式(Recovery選主)和廣播模式(Broadcast同步)。當服務啟動或者在領導者崩潰後,Zab就進入了恢復模式,當領導者被選舉出來,且大多數Server完成了和leader的狀態同步以後,恢復模式就結束了。狀態同步保證了leader和Server具有相同的系統狀態。
為了保證事務的順序一致性,zookeeper采用了遞增的事務id號(zxid)來標識事務。所有的提議(proposal)都在被提出的時候加上了zxid。實現中zxid是一個64位的數字,它高32位是epoch用來標識leader關系是否改變,每次一個leader被選出來,它都會有一個新的epoch,標識當前屬於那個leader的統治時期。低32位用於遞增計數。
每個Server在工作過程中有4種狀態:
LOOKING:當前Server不知道leader是誰,正在搜尋。
LEADING:當前Server即為選舉出來的leader。
FOLLOWING:leader已經選舉出來,當前Server與之同步。
OBSERVING:observer的行為在大多數情況下與follower完全一致,但是他們不參加選舉和投票,而僅僅接受(observing)選舉和投票的結果。
Zookeeper集群節點- Zookeeper節點部署越多,服務的可靠性越高,建議部署奇數個節點,因為zookeeper集群是以宕機個數過半才會讓整個集群宕機的。
- 需要給每個zookeeper 1G左右的內存,如果可能的話,最好有獨立的磁盤,因為獨立磁盤可以確保zookeeper是高性能的。如果你的集群負載很重,不要把zookeeper和RegionServer運行在同一臺機器上面,就像DataNodes和TaskTrackers一樣。
| 主機名 | 系統 | IP地址 |
| linux-node1 | CentOS release 6.8 | 192.168.1.148 |
| linux-node2 | CentOS release 6.8 | 192.168.1.149 |
| linux-node2 | CentOS release 6.8 | 192.168.1.150 |
Zookeeper運行需要java環境,需要安裝jdk,註:每臺服務器上面都需要安裝zookeeper、jdk,建議本地下載好需要的安裝包然後上傳到服務器上面,服務器上面下載速度太慢。
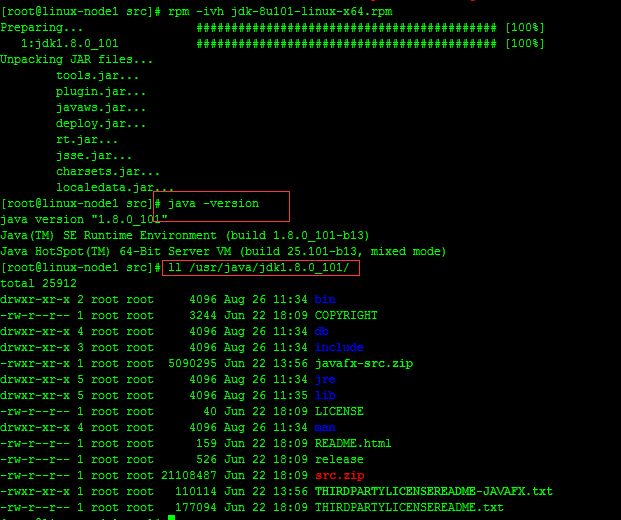
2.1、JDK安裝JDK下載地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
rpm -ivh jdk-8u101-linux-x64.rpm
Zookeeper鏈接:http://zookeeper.apache.org/
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz -P /usr/local/src/ tar zxvf zookeeper-3.4.8.tar.gz -C /opt cd /opt && mv zookeeper-3.4.8 zookeeper cd zookeeper cp conf/zoo_sample.cfg conf/zoo.cfg
#把zookeeper加入到環境變量
echo -e "# append zk_env\nexport PATH=$PATH:/opt/zookeeper/bin" >> /etc/profile三、Zookeeper集群配置
註意:搭建zookeeper集群時,一定要先停止已經啟動的zookeeper節點。
3.1、Zookeeper配置文件修改#修改過後的配置文件zoo.cfg,如下:
egrep -v "^#|^$" zoo.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataLogDir=/opt/zookeeper/logs dataDir=/opt/zookeeper/data clientPort=2181 autopurge.snapRetainCount=500 autopurge.purgeInterval=24 server.1= 192.168.1.148:2888:3888 server.2= 192.168.1.149:2888:3888 server.3= 192.168.1.150:2888:3888
#創建相關目錄,三臺節點都需要
mkdir -p /opt/zookeeper/{logs,data}
#其余zookeeper節點安裝完成之後,同步配置文件zoo.cfg。
3.2、配置參數說明tickTime這個時間是作為zookeeper服務器之間或客戶端與服務器之間維持心跳的時間間隔,也就是說每個tickTime時間就會發送一個心跳。
initLimit這個配置項是用來配置zookeeper接受客戶端(這裏所說的客戶端不是用戶連接zookeeper服務器的客戶端,而是zookeeper服務器集群中連接到leader的follower 服務器)初始化連接時最長能忍受多少個心跳時間間隔數。
當已經超過10個心跳的時間(也就是tickTime)長度後 zookeeper 服務器還沒有收到客戶端的返回信息,那麽表明這個客戶端連接失敗。總的時間長度就是 10*2000=20秒。
syncLimit這個配置項標識leader與follower之間發送消息,請求和應答時間長度,最長不能超過多少個tickTime的時間長度,總的時間長度就是5*2000=10秒。
dataDir顧名思義就是zookeeper保存數據的目錄,默認情況下zookeeper將寫數據的日誌文件也保存在這個目錄裏;
clientPort這個端口就是客戶端連接Zookeeper服務器的端口,Zookeeper會監聽這個端口接受客戶端的訪問請求;
server.A=B:C:D中的A是一個數字,表示這個是第幾號服務器,B是這個服務器的IP地址,C第一個端口用來集群成員的信息交換,表示這個服務器與集群中的leader服務器交換信息的端口,D是在leader掛掉時專門用來進行選舉leader所用的端口。
3.3、創建ServerID標識除了修改zoo.cfg配置文件外,zookeeper集群模式下還要配置一個myid文件,這個文件需要放在dataDir目錄下。
這個文件裏面有一個數據就是A的值(該A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路徑中創建myid文件。
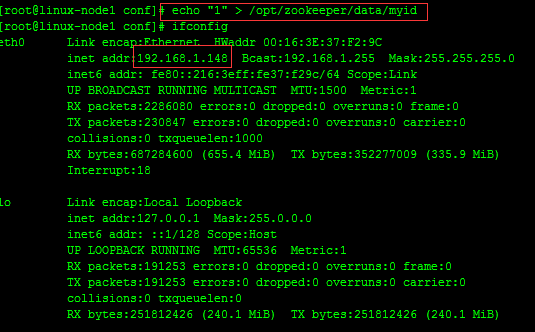
#在192.168.1.148服務器上面創建myid文件,並設置值為1,同時與zoo.cfg文件裏面的server.1保持一致,如下
echo "1" > /opt/zookeeper/data/myid
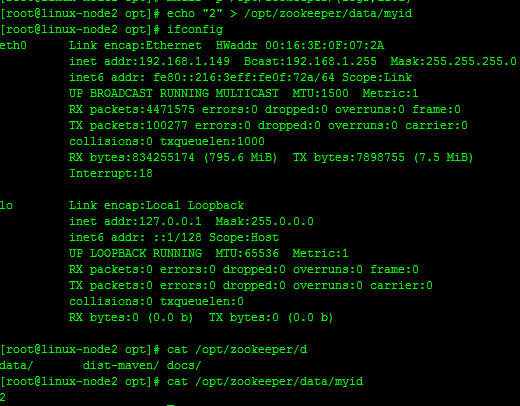
#在192.168.1.149服務器上面創建myid文件,並設置值為2,同時與zoo.cfg文件裏面的server.2保持一致,如下
echo "2" > /opt/zookeeper/data/myid
#在192.168.1.150服務器上面創建myid文件,並設置值為1,同時與zoo.cfg文件裏面的server.3保持一致,如下
echo "3" > /opt/zookeeper/data/myid
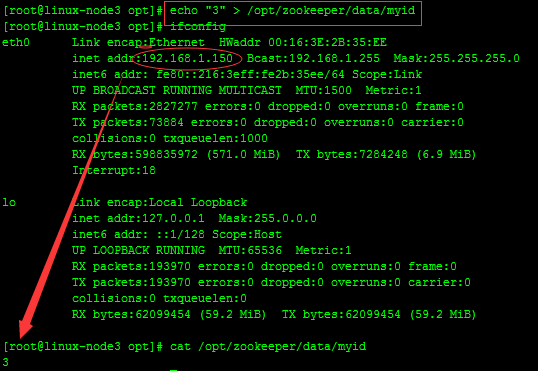
到此,相關配置已完成
-------------------------------------------------------------------------------------------------------------------
四、Zookeeper集群啟動與查看1、啟動每個服務器上面的zookeeper節點:
#linux-node1、linux-node2、linux-node3
/opt/zookeeper/bin/zkServer.sh start
註意:報錯排查
Zookeeper節點啟動不了可能原因:zoo.cfg配置文件有誤、iptables沒關。
2、啟動完成之後查看每個節點的狀態#linux-node1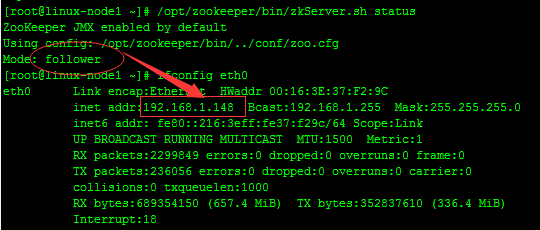
#linux-node2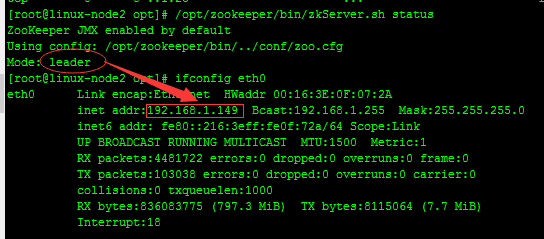
#linux-node3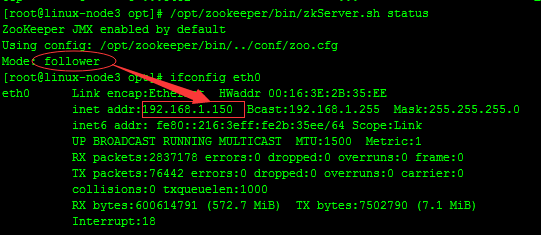
#從上面可以看出,linux-node1,linux-node3兩臺服務器zookeeper的狀態是follow模式,linux-node2這臺服務器zookeeper的狀態是leader模式。
自己的機器使用status查詢不成功,感覺像是版本問題,由於時間問題不過多的糾結,此處
查看文檔的時候,很感謝以為網友的回答,解決了該問題;如下:
root@host:~# telnet localhost 2181
Trying 127.0.0.1...
Connected to myhost.
Escape character is ‘^]‘.
stats
Zookeeper version: 3.4.3-cdh4.0.1--1, built on 06/28/2012 23:59 GMT
Clients:
Latency min/avg/max: 0/0/677
Received: 4684478
Sent: 4687034
Outstanding: 0
Zxid: 0xb00187dd0
Mode: leader
Node count: 127182
Connection closed by foreign host.
本地未安裝telnet,現在安裝telnet,如下:
一、安裝telnet
1、檢測telnet-server的rpm包是否安裝[root@localhost ~]# rpm -qa telnet-server
若無輸入內容,則表示沒有安裝。出於安全考慮telnet-server.rpm是默認沒有安裝的,而telnet的客戶端是標配。即下面的軟件是默認安裝的。
2、若未安裝,則安裝telnet-server,否則忽略此步驟
[root@localhost ~]#yum install telnet-server 3、檢測telnet-server的rpm包是否安裝[root@localhost ~]# rpm -qa telnet
telnet-0.17-47.el6_3.1.x86_64
4、若未安裝,則安裝telnet,否則忽略此步驟
[root@localhost ~]# yum install telnet
結果如下:
linux1:

linux2:

linux3:

-------------------------------------------------------------------------------------------------------------------
五、Zookeeper集群連接Zookeeper集群搭建完畢之後,可以通過客戶端腳本連接到zookeeper集群上面,對客戶端來說,zookeeper集群是一個整體,連接到zookeeper集群實際上感覺在獨享整個集群的服務。
#在linux-node1測試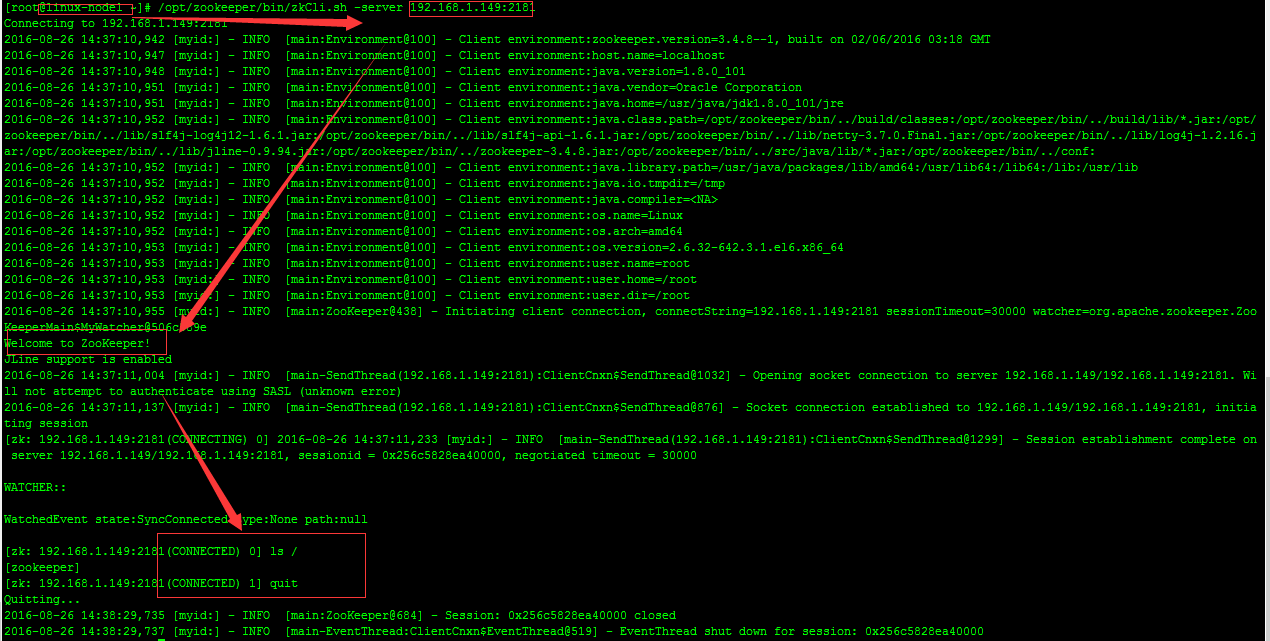
通過上圖可以看出整個zookeeper集群已經搭建並測試完成。
#Zookeeper原理:
http://blog.csdn.net/wuliu_forever/article/details/52053557
http://www.cnblogs.com/luxiaoxun/p/4887452.html
zookeeper安裝以及遇到的一些坑