
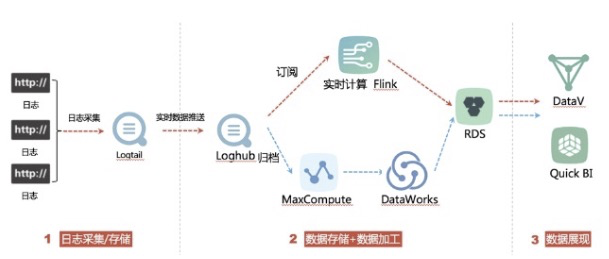
通過DataWorks資料整合歸檔日誌服務資料至MaxCompute進行離線分析

官方指導文件:https://help.aliyun.com/document_detail/68322.html
但是會遇到大家在分割槽上或者DataWorks排程引數配置問題,具體拿到真實的case模擬如下:
建立資料來源:
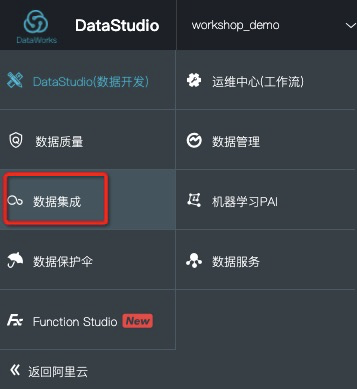
步驟1 進入資料整合,點選作業資料來源,進入Tab頁面。
步驟2 點選右上角
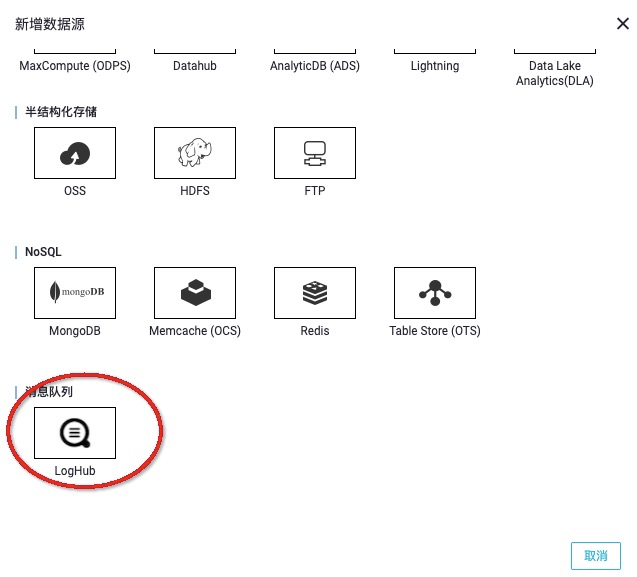
新增資料來源,選擇訊息佇列 loghub。
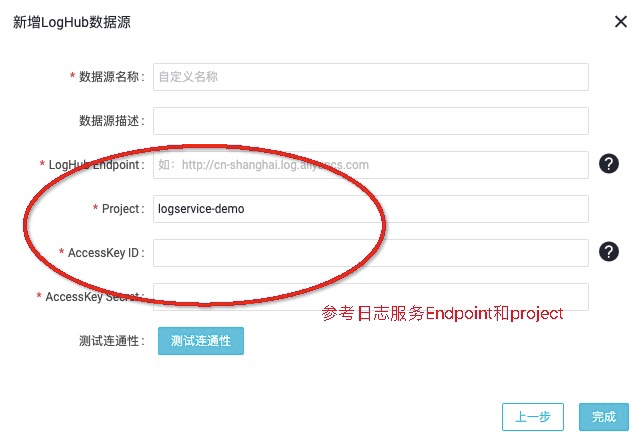
步驟3 編輯LogHub資料來源中的必填項,包括資料來源名稱、LogHub
Endpoint、Project、AK資訊等,並點選 測試連通性。
建立目標表:
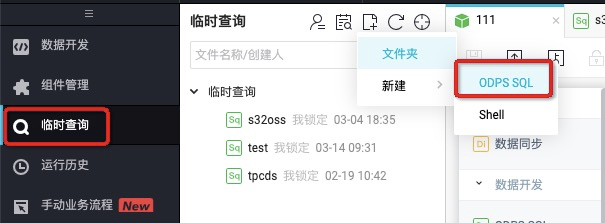
步驟1 在左側tab也中找到臨時查詢,並右鍵>新建ODPS SQL節點。
步驟2 編寫建表DDL。
步驟3 點選
執行 按鈕進行建立目標表,分別為ods_client_operation_log、ods_vedio_server_log、ods_web_tracking_log。
步驟4 直到日誌列印成本,表示三條DDL語句執行完畢。
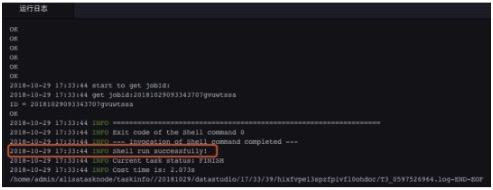
步驟5 可以通過desc 檢視建立的表。

其他兩張表也可以通過desc 進行查詢。確認資料表的存在情況。
建立資料同步任務
資料來源端以及在DataWorks中的資料來源連通性都已經配置好,接下來就可以通過資料同步任務進行採集資料到MaxCompute上。
操作步驟
步驟1 點選
新建業務流程 並 確認提交,名稱為 直播日誌採集。
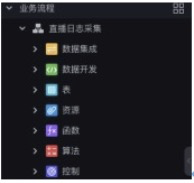
步驟2 在業務流程開發面板中依次建立如下依賴並命名。

依次配置資料同步任務節點配置:web_tracking_log_syn、client_operation_log_syn、vedio_server_log_syn。
步驟3 雙擊
web_tracking_log_syn 進入節點配置,配置項包括資料來源(資料來源和資料去向)、欄位對映(源頭表和目標表)、通道控制。
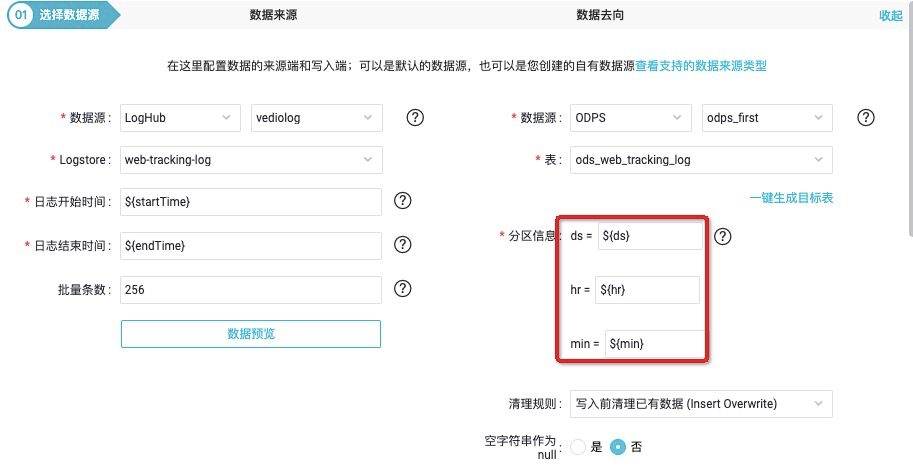

根據採集的時間視窗自定義引數為:
當然其消費點位也可以按照自定義設定5分鐘排程一次,從00:00到23:59,startTime=
![]()
[yyyymmddhh24miss−10/24/60]系統前10分鐘到endTime=[yyyymmddhh24miss-5/24/60]系統前5分鐘時間(注意與上圖消費資料定位不同),那麼應該配置為ds=[yyyymmdd-5/24/60],hr=[hh24-5/24/60],min=[mi-5/24/60]。
步驟4 可以點選高階執行進行測試。
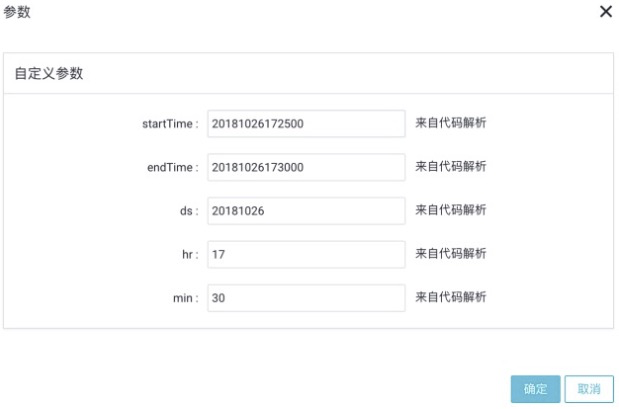
可以分別手工收入自定義引數值進行測試。
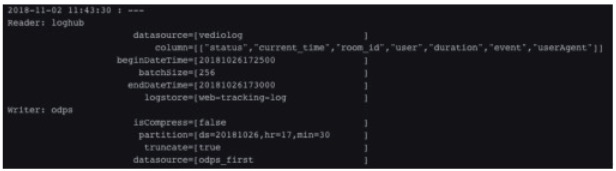
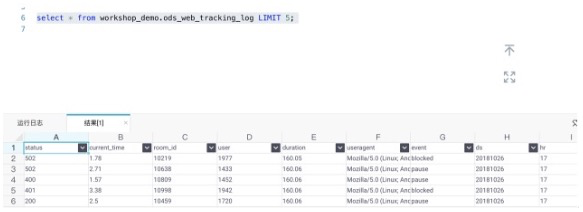
步驟3 使用SQL指令碼確認是否資料已經寫進來。如下圖所示:
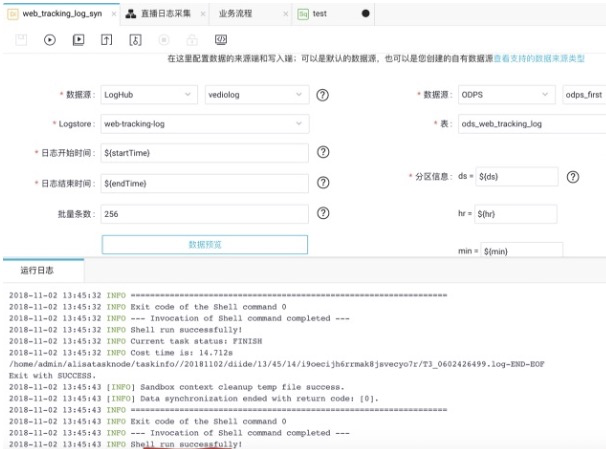
日誌服務的日誌正式的被採集入庫,接下來就可以進行資料加工。
比如可以通過上述來統計熱門房間、地域分佈和卡頓率,如下所示:
具體SQL邏輯不在這裡展開,可以根據具體業務需求來統計分析。依賴關係配置如上圖所示。
作者:禕休
本文為雲棲社群原創內容,未經