
Pytorch之訓練器設置
Pytorch之訓練器設置
引言
深度學習訓練的時候有很多技巧, 但是實際用起來效果如何, 還是得親自嘗試.
這裏記錄了一些個人嘗試不同技巧的代碼.
tensorboardX
說起tensorflow, 我就一陣頭大, google強力的創造了一門新的語言! 自從上手Pytorch後, 就再也不想回去了. 但是tensorflow的生態不是一般的好, 配套設施齊全, 尤其是可視化神器tensorboard, 到了Pytorch這邊, 幸好還有visdom和tensorboardX, 但是前者實在是有些捉摸不透... 到時tensorboardX讓我感覺更為親切些...
tensorboard的使用, 需要連帶tensorflow一起裝好, 也就是說, 想要用pytorch的tensorboardX, 你還是得裝好tensorflow...
使用from tensorboardX import SummaryWriter導入核心類(似乎這個包裏只有這個類), 具體的用法也很簡單, 詳見https://github.com/lanpa/tensorboardX/tree/master/examples, 以及 https://tensorboardx.readthedocs.io/en/latest/index.html.
我這裏直接對其實例化, self.tb = SummaryWriter(self.path[‘tb‘]), 後面直接調用self.tb的方法就可以了. 在這裏, 我顯示了很多東西. 這裏需要說的有兩點:
- 多個圖的顯示: 使用名字區分, 如
‘data/train_loss_avg‘與‘data/train_loss_avg‘ - 多個圖片的顯示: 這裏使用了pytorch自帶的一個處理張量的方法
make_grid來得到可以用tensorboard顯示的圖像.
if self.args['tb_update'] > 0 and curr_iter % self.args['tb_update'] == 0: self.tb.add_scalar('data/train_loss_avg', train_loss_record.avg, curr_iter) self.tb.add_scalar('data/train_loss_avg', train_iter_loss, curr_iter) self.tb.add_scalar('data/train_lr', self.opti.param_groups[1]['lr'], curr_iter) self.tb.add_text('train_data_names', str(train_names), curr_iter) tr_tb_out_1 = make_grid(otr_1, nrow=train_batch_size, padding=5) self.tb.add_image('train_output1', tr_tb_out_1, curr_iter) tr_tb_out_2 = make_grid(otr_2, nrow=train_batch_size, padding=5) self.tb.add_image('train_output2', tr_tb_out_2, curr_iter) tr_tb_out_4 = make_grid(otr_4, nrow=train_batch_size, padding=5) self.tb.add_image('train_output4', tr_tb_out_4, curr_iter) tr_tb_out_8 = make_grid(otr_8, nrow=train_batch_size, padding=5) self.tb.add_image('train_output8', tr_tb_out_8, curr_iter) tr_tb_out_16 = make_grid(otr_16, nrow=train_batch_size, padding=5) self.tb.add_image('train_output16', tr_tb_out_16, curr_iter) tr_tb_label = make_grid(train_labels, nrow=train_batch_size, padding=5) self.tb.add_image('train_labels', tr_tb_label, curr_iter) tr_tb_indata = make_grid(train_inputs, nrow=train_batch_size, padding=5) self.tb.add_image('train_data', tr_tb_indata, curr_iter) # 我這裏的圖像顯示的預處理之後要輸入網絡的圖片
下面是顯示的結果:
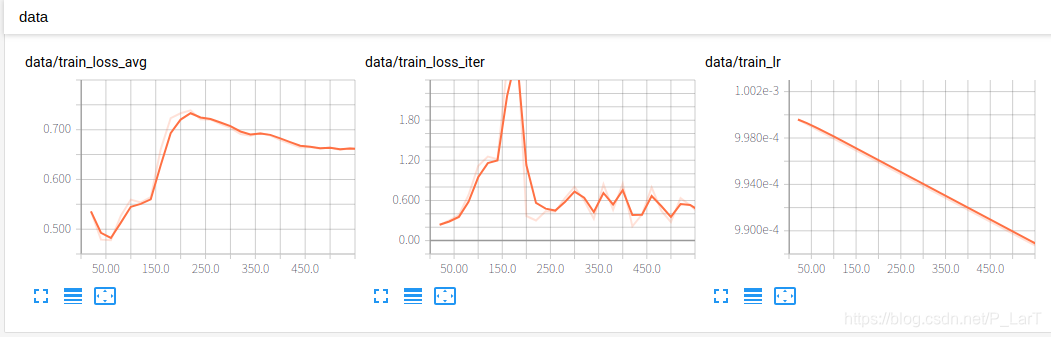
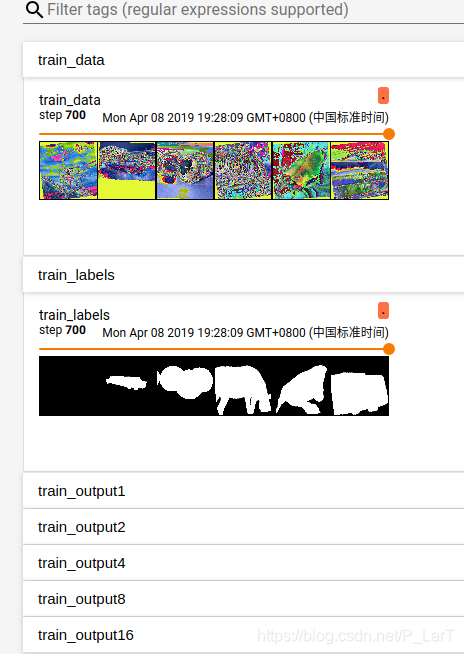
優化器
這裏關於學習率的設定, 根據參數名字中是否保安bias(是否為偏置項)來分別設置.
self.opti = optim.SGD(
[
# 不對bias參數執行weight decay操作,weight decay主要的作用就是通過對網絡
# 層的參數(包括weight和bias)做約束(L2正則化會使得網絡層的參數更加平滑)達
# 到減少模型過擬合的效果。
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] == 'bias'],
'lr': 2 * self.args['lr']},
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] != 'bias'],
'lr': self.args['lr'],
'weight_decay': self.args['weight_decay']}
],
momentum=self.args['momentum'])
self.sche = self.__make_schedular()
self.warmup_iters = self.args['warmup_epoch'] * len(self.tr_loader)這裏實現了學習率預熱和幾個學習率衰減設定, 關鍵的地方在於使用學習率預熱的時候要註意對應的周期(叠代次數)如何設定, 要保證與正常的學習率衰減之間的平滑過渡.
def __lr_warmup(self, curr_iter):
"""
實現學習率預熱, 在self.args['warmup_epoch']設定對應的恢復時對應的周期
"""
warmup_lr = self.args['lr'] / self.warmup_iters
self.opti.param_groups[0]['lr'] = 2 * warmup_lr * curr_iter
self.opti.param_groups[1]['lr'] = warmup_lr * curr_iter
def __make_schedular(self):
if self.args['warmup_epoch'] > 0:
epoch_num = self.args['epoch_num'] - self.args['warmup_epoch'] + 1
else:
epoch_num = self.args['epoch_num']
# 計算總的叠代次數, 一個周期batch數量為len(self.tr_loader)
iter_num = epoch_num * len(self.tr_loader)
if self.args['lr_type'] == 'exp':
lamb = lambda curr_iter: pow((1 - (curr_iter / iter_num)), self.args['lr_decay'])
scheduler = optim.lr_scheduler.LambdaLR(self.opti, lr_lambda=lamb)
elif self.args['lr_type'] == 'cos':
scheduler = optim.lr_scheduler.CosineAnnealingLR(
self.opti,
T_max=iter_num - 1,
eta_min=4e-08)
else:
raise RuntimeError('沒有該學習率衰減設定')
return scheduler模型保存與恢復
主要是根據訓練損失最小的時候進行所謂best模型的保存. 以及在訓練結束的時候保存模型.
if self.args['save_best']:
old_diff = val_loss_avg if self.args['has_val'] else train_loss_record.avg
if old_diff < self.old_diff:
self.old_diff = old_diff
torch.save(self.net.state_dict(), self.path['best_net'])
torch.save(self.opti.state_dict(), self.path['best_opti'])
tqdm.write(f"epoch {epoch} 模型較好, 已保存")
# 所有的周期叠代結束
torch.save(self.net.state_dict(), self.path['final_net'])
torch.save(self.opti.state_dict(), self.path['final_opti'])對於模型恢復, 可以如下設定, 但是要註意, 想要繼續訓練, 需要註意很多地方, 例如tensorboard繼續顯示還是刪除後重新顯示, 註意學習率的設定, 重新開始是否要使用學習率預熱, 學習率如何衰減等等細節.
if len(self.args['snapshot']) > 0:
print('training resumes from ' + self.args['snapshot'])
assert int(self.args['snapshot']) == self.args['start_epoch']
net_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '.pth')
opti_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '_optim.pth')
self.net.load_state_dict(torch.load(net_path))
self.opti.load_state_dict(torch.load(opti_path))
# bias的學習率大於weights的
# 繼續訓練的時候, 直接使用了最大的學習率
self.opti.param_groups[0]['lr'] = 2 * self.args['lr']
self.opti.param_groups[1]['lr'] = self.args['lr']進度展示
這裏使用了tqdm這個包, 來對訓練, 測試進度進行展示. 主要使用了trange和tqdm以及tqdm.write來顯示.
導入: from tqdm import tqdm, trange.
使用如下:
def train(self):
tqdm_trange = trange(self.start_epoch, self.end_epoch, ncols=100)
for epoch in tqdm_trange:
tqdm_trange.set_description(f"tr=>epoch={epoch}")
train_loss_record = AvgMeter()
batch_tqdm = tqdm(enumerate(self.tr_loader), total=len(self.tr_loader),
ncols=100, leave=False)
for train_batch_id, train_data in batch_tqdm:
batch_tqdm.set_description(f"net=>{self.args[self.args['NET']]['exp_name']}"
f"lr=>{self.opti.param_groups[1]['lr']}")
...
tqdm.write(f"epoch {epoch} 模型較好, 已保存")顯示如下:

整體代碼
import os
import os.path as osp
from datetime import datetime
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from tensorboardX import SummaryWriter
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import make_grid
from tqdm import tqdm, trange
from models.NearLoss import NearLoss
from models.NearLossV2 import NearLossV2
from models.SLoss import SLoss
from utils import joint_transforms
from utils.config import arg_config, path_config
from utils.datasets import ImageFolder
from utils.misc import (AvgMeter, cal_fmeasure, cal_pr_mae_fm, check_mkdir, make_log)
torch.manual_seed(2019)
torch.multiprocessing.set_sharing_strategy('file_system')
class Trainer():
def __init__(self, args, path):
super(Trainer, self).__init__()
# 無依賴屬性
self.args = args
self.path = path
self.dev = torch.device(
"cuda:0" if torch.cuda.is_available() else "cpu")
self.to_pil = transforms.ToPILImage()
self.old_diff = 100 # 設定一個足夠大的數, 來保存後期的損失
# 刪除之前的文件夾, 如果要刷新tensorboard, 最好是重新啟動一下tensorboard
check_mkdir(self.path['pth_log'])
if len(self.args['snapshot']) == 0:
# if os.path.exists(self.path['tb']):
# print(f"rm -rf {self.path['tb']}")
# os.system(f"rm -rf {self.path['tb']}")
check_mkdir(self.path['tb'])
if self.args['save_pre']:
if os.path.exists(self.path['save']):
print(f"rm -rf {self.path['save']}")
os.system(f"rm -rf {self.path['save']}")
check_mkdir(self.path['save'])
# 依賴與前面屬性的屬性
self.pth_path = self.path['best_net'] if osp.exists(self.path['best_net']) else self.path['final_net']
if self.args['tb_update'] > 0:
self.tb = SummaryWriter(self.path['tb'])
self.tr_loader, self.val_loader, self.te_loader = self.__make_loader()
self.net = self.args[self.args['NET']]['net']().to(self.dev)
# 學習率相關
self.opti = optim.SGD(
[
# 不對bias參數執行weight decay操作,weight decay主要的作用就是通過對網絡
# 層的參數(包括weight和bias)做約束(L2正則化會使得網絡層的參數更加平滑)達
# 到減少模型過擬合的效果。
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] == 'bias'],
'lr': 2 * self.args['lr']},
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] != 'bias'],
'lr': self.args['lr'],
'weight_decay': self.args['weight_decay']}
],
momentum=self.args['momentum'])
self.sche = self.__make_schedular()
self.warmup_iters = self.args['warmup_epoch'] * len(self.tr_loader)
# 損失相關
self.crit = nn.BCELoss().to(self.dev)
self.use_newloss = self.args['new_loss']['using']
if self.use_newloss:
if self.args['new_loss']['type'] == 'sloss':
self.crit_new = SLoss().to(self.dev)
elif self.args['new_loss']['type'] == 'nearloss':
self.crit_new = NearLoss().to(self.dev)
elif self.args['new_loss']['type'] == 'nearlossv2':
self.crit_new = NearLossV2(self.dev).to(self.dev)
print(f"使用了附加的新損失{self.crit_new}")
# 繼續訓練相關
self.start_epoch = self.args['start_epoch'] # 接著上次訓練
if self.args['end_epoch'] < self.args['epoch_num']:
self.end_epoch = self.args['end_epoch']
else:
self.end_epoch = self.args['epoch_num']
if len(self.args['snapshot']) > 0:
print('training resumes from ' + self.args['snapshot'])
assert int(self.args['snapshot']) == self.args['start_epoch']
net_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '.pth')
opti_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '_optim.pth')
self.net.load_state_dict(torch.load(net_path))
self.opti.load_state_dict(torch.load(opti_path))
# bias的學習率大於weights的
# 繼續訓練的時候, 直接使用了最大的學習率
self.opti.param_groups[0]['lr'] = 2 * self.args['lr']
self.opti.param_groups[1]['lr'] = self.args['lr']
def train(self):
tqdm_trange = trange(self.start_epoch, self.end_epoch, ncols=100)
for epoch in tqdm_trange:
tqdm_trange.set_description(f"tr=>epoch={epoch}")
train_loss_record = AvgMeter()
batch_tqdm = tqdm(enumerate(self.tr_loader), total=len(self.tr_loader),
ncols=100, leave=False)
for train_batch_id, train_data in batch_tqdm:
batch_tqdm.set_description(f"net=>{self.args[self.args['NET']]['exp_name']}"
f"lr=>{self.opti.param_groups[1]['lr']}")
if len(self.args['snapshot']) > 0:
lr_epoch = epoch - int(self.args['snapshot'])
else:
lr_epoch = epoch
"""
僅在從頭訓練的時候使用學習率預熱, 對於繼續訓練的時候, 不再使用學習率預熱.
"""
curr_iter = train_batch_id + 1 + epoch * len(self.tr_loader)
if len(self.args['snapshot']) > 0:
curr_iter -= (self.start_epoch * len(self.tr_loader))
if self.args['lr_type'] == 'exp':
self.sche.step(curr_iter)
elif self.args['lr_type'] == 'cos':
self.sche.step()
else:
if epoch < self.args['warmup_epoch']:
self.__lr_warmup(curr_iter)
else:
if self.args['lr_type'] == 'exp':
self.sche.step(curr_iter - self.warmup_iters)
elif self.args['lr_type'] == 'cos':
self.sche.step()
train_inputs, train_labels, train_names = train_data
train_inputs = train_inputs.to(self.dev)
train_labels = train_labels.to(self.dev)
self.opti.zero_grad()
otr_1, otr_2, otr_4, otr_8, otr_16 = self.net(train_inputs)
tr_loss_1 = self.crit(otr_1, train_labels)
tr_loss_2 = self.crit(otr_2, train_labels)
tr_loss_4 = self.crit(otr_4, train_labels)
tr_loss_8 = self.crit(otr_8, train_labels)
tr_loss_16 = self.crit(otr_16, train_labels)
train_loss = tr_loss_1 + tr_loss_2 + tr_loss_4 + tr_loss_8 + tr_loss_16
if self.use_newloss:
train_loss += self.args['new_loss']['beta'] * self.crit_new(otr_1, train_labels)
"""
以後累加loss, 用loss.item(). 這個是必須的, 如果直接加, 那麽隨著訓練的進行,
會導致後來的loss具有非常大的graph, 可能會超內存. 然而total_loss只是用來看的,
所以沒必要進行維持這個graph!
"""
# 反向傳播使用的損失不需要item獲取數據
train_loss.backward()
self.opti.step()
# 僅在累計的時候使用item()獲取數據
train_iter_loss = train_loss.item()
train_batch_size = train_inputs.size(0)
train_loss_record.update(train_iter_loss, train_batch_size)
if self.args['tb_update'] > 0 and curr_iter % self.args['tb_update'] == 0:
self.tb.add_scalar('data/train_loss_avg', train_loss_record.avg, curr_iter)
self.tb.add_scalar('data/train_loss_iter', train_iter_loss, curr_iter)
self.tb.add_scalar('data/train_lr', self.opti.param_groups[1]['lr'], curr_iter)
self.tb.add_text('train_data_names', str(train_names), curr_iter)
tr_tb_out_1 = make_grid(otr_1, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output1', tr_tb_out_1, curr_iter)
tr_tb_out_2 = make_grid(otr_2, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output2', tr_tb_out_2, curr_iter)
tr_tb_out_4 = make_grid(otr_4, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output4', tr_tb_out_4, curr_iter)
tr_tb_out_8 = make_grid(otr_8, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output8', tr_tb_out_8, curr_iter)
tr_tb_out_16 = make_grid(otr_16, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output16', tr_tb_out_16, curr_iter)
tr_tb_label = make_grid(train_labels, nrow=train_batch_size, padding=5)
self.tb.add_image('train_labels', tr_tb_label, curr_iter)
tr_tb_indata = make_grid(train_inputs, nrow=train_batch_size, padding=5)
self.tb.add_image('train_data', tr_tb_indata, curr_iter)
if self.args['has_val']:
tqdm.write(f'train epoch {epoch} over, val start')
self.net.eval()
val_loss_avg = self.__val(lr_epoch)
self.net.train()
if self.args['save_best']:
old_diff = val_loss_avg if self.args['has_val'] else train_loss_record.avg
if old_diff < self.old_diff:
self.old_diff = old_diff
torch.save(self.net.state_dict(), self.path['best_net'])
torch.save(self.opti.state_dict(), self.path['best_opti'])
tqdm.write(f"epoch {epoch} 模型較好, 已保存")
# 所有的周期叠代結束
torch.save(self.net.state_dict(), self.path['final_net'])
torch.save(self.opti.state_dict(), self.path['final_opti'])
def test(self):
self.net.eval()
self.net.load_state_dict(torch.load(self.pth_path))
gt_path = osp.join(self.path['test'], 'Mask')
pres = [AvgMeter()] * 256
recs = [AvgMeter()] * 256
fams = AvgMeter()
maes = AvgMeter()
tqdm_iter = tqdm(enumerate(self.te_loader),
total=len(self.te_loader),
ncols=100, leave=True)
for test_batch_id, test_data in tqdm_iter:
tqdm_iter.set_description(
f"{self.args[self.args['NET']]['exp_name']}:"
f"te=>{test_batch_id + 1}")
in_imgs, in_names = test_data
inputs = in_imgs.to(self.dev)
with torch.no_grad():
outputs = self.net(inputs)
outputs_np = outputs.cpu().detach()
for item_id, out_item in enumerate(outputs_np):
gimg_path = osp.join(gt_path, in_names[item_id] + '.png')
gt_img = Image.open(gimg_path).convert('L')
out_img = self.to_pil(out_item).resize(gt_img.size)
gt_img = np.array(gt_img)
if self.args['save_pre']:
oimg_path = osp.join(self.path['save'], in_names[item_id] + '.png')
out_img.save(oimg_path)
out_img = np.array(out_img)
ps, rs, mae, fam = cal_pr_mae_fm(out_img, gt_img)
for pidx, pdata in enumerate(zip(ps, rs)):
p, r = pdata
pres[pidx].update(p)
recs[pidx].update(r)
maes.update(mae)
fams.update(fam)
fm = cal_fmeasure([pre.avg for pre in pres],
[rec.avg for rec in recs])
results = {'fm_thresholds': fm,
'fm': fams.avg,
'mae': maes.avg}
return results
def __val(self, lr_epoch):
val_loss_record = AvgMeter()
# fams = AvgMeter()
# maes = AvgMeter()
for val_batch_id, val_data in tqdm(enumerate(self.val_loader),
total=len(self.val_loader),
desc=f"val=>epoch={lr_epoch}",
ncols=100, leave=True):
val_inputs, val_labels = val_data
val_inputs = val_inputs.to(self.dev)
with torch.no_grad():
val_outputs = self.net(val_inputs)
# # 從gpu搬運到cpu後, 修改numpy結果, 不會影響gpu值
# val_outputs_np = val_outputs.cpu().detach().numpy()
# # numpy()方法會返回一個數組, 但是與原本的tensor共享存儲單元, 所以一個變都會變
# # 所以使用numpy的copy方法, 這個的實現是深拷貝. 數據獨立
# val_labels_np = val_labels.numpy().copy()
#
# val_outputs_np *= 255
# val_labels_np *= 255
# val_outputs_np = val_outputs_np.astype(np.uint8)
# val_labels_np = val_labels_np.astype(np.uint8)
#
# for item_id, pre_gt_item in enumerate(zip(val_outputs_np,
# val_labels_np)):
# out_item, label_item = pre_gt_item
# _, _, mae, fam = cal_pr_mae_fm(out_item, label_item)
# maes.update(mae)
# fams.update(fam)
val_labels = val_labels.to(self.dev)
# 通過item()使單元素張量轉化為python標量, 因為這裏不需要反向傳播
val_iter_loss = self.crit(val_outputs, val_labels).item()
if self.use_newloss:
val_iter_loss += self.args['new_loss']['beta'] * self.crit_new(val_outputs, val_labels).item()
val_batch_size = val_inputs.size(0)
val_loss_record.update(val_iter_loss, val_batch_size)
# 每一個周期下都對應一個訓練階段與驗證階段, 所以這裏使用len(val)即可
curr_iter = val_batch_id + 1 + lr_epoch * len(self.val_loader)
if self.args['tb_update'] > 0 and curr_iter % self.args['tb_update'] == 0:
self.tb.add_scalar('data/val_loss_avg', val_loss_record.avg, curr_iter)
self.tb.add_scalar('data/val_loss_iter', val_iter_loss, curr_iter)
val_tb_out = make_grid(val_outputs, nrow=val_batch_size, padding=5)
val_tb_label = make_grid(val_labels, nrow=val_batch_size, padding=5)
self.tb.add_image('val_output', val_tb_out, curr_iter)
self.tb.add_image('val_label', val_tb_label, curr_iter)
return val_loss_record.avg
def __lr_warmup(self, curr_iter):
"""
實現學習率預熱, 在self.args['warmup_epoch']設定對應的恢復時對應的周期
"""
warmup_lr = self.args['lr'] / self.warmup_iters
self.opti.param_groups[0]['lr'] = 2 * warmup_lr * curr_iter
self.opti.param_groups[1]['lr'] = warmup_lr * curr_iter
def __make_schedular(self):
if self.args['warmup_epoch'] > 0:
epoch_num = self.args['epoch_num'] - self.args['warmup_epoch'] + 1
else:
epoch_num = self.args['epoch_num']
# 計算總的叠代次數, 一個周期batch數量為len(self.tr_loader)
iter_num = epoch_num * len(self.tr_loader)
if self.args['lr_type'] == 'exp':
lamb = lambda curr_iter: pow((1 - (curr_iter / iter_num)), self.args['lr_decay'])
scheduler = optim.lr_scheduler.LambdaLR(self.opti, lr_lambda=lamb)
elif self.args['lr_type'] == 'cos':
scheduler = optim.lr_scheduler.CosineAnnealingLR(
self.opti,
T_max=iter_num - 1,
eta_min=4e-08)
else:
raise RuntimeError('沒有該學習率衰減設定')
return scheduler
def __make_loader(self):
train_joint_transform = joint_transforms.Compose([
joint_transforms.RandomScaleCrop(base_size=self.args['base_size'],
crop_size=self.args['crop_size']),
joint_transforms.RandomHorizontallyFlip(),
joint_transforms.RandomRotate(10)
])
train_img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_target_transform = transforms.ToTensor()
test_val_img_transform = transforms.Compose([
transforms.Resize((self.args['crop_size'], self.args['crop_size'])),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_target_transform = transforms.Compose([
transforms.Resize(
(self.args['crop_size'], self.args['crop_size'])),
transforms.ToTensor(),
])
train_set = ImageFolder(self.path['train'],
'train',
train_joint_transform,
train_img_transform,
train_target_transform)
train_loader = DataLoader(train_set,
batch_size=self.args['batch_size'],
num_workers=self.args['num_workers'],
shuffle=True,
drop_last=False,
pin_memory=True)
# drop_last=True的時候, 會把最後的不能構成一個完整batch的數據刪掉, 但是這裏=False
# 就不會刪掉, 該batch對應會減小.
if self.args['has_val']:
val_set = ImageFolder(self.path['val'],
'val',
None,
test_val_img_transform,
val_target_transform)
val_loader = DataLoader(val_set,
batch_size=self.args['batch_size'],
num_workers=self.args['num_workers'],
shuffle=False,
drop_last=False,
pin_memory=True)
else:
val_loader = None
test_set = ImageFolder(self.path['test'],
'test',
None,
test_val_img_transform,
None)
test_loader = DataLoader(test_set,
batch_size=self.args['batch_size'],
num_workers=self.args['num_workers'],
shuffle=False,
drop_last=False,
pin_memory=True)
return train_loader, val_loader, test_loader
if __name__ == '__main__':
trainer = Trainer(arg_config, path_config)
make_log(path_config['log_txt'], f"\n{arg_config}")
print('開始訓練...')
trainer.train()
print('開始測試...')
begin = datetime.now()
result = trainer.test()
end = datetime.now()
print(result)
make_log(path_config['log_txt'], f"{result}\n, 測試花費時間:{end - begin}\n")
with open('log_project.log', 'a') as log_pro:
# 每運行一次就記錄一次參數設定
log_pro.write(f"\n\n{datetime.now()}\n{arg_config}\n{result}\n\n")Pytorch之訓練器設置