
go核心chan.go檔案分析解讀(一)go是如何構建一個通道的
原因
今天公眾號“一起學golang”發了一篇文章,《深入理解channel,設計+原始碼》,瞬間提起了我學習的興趣,好像回到長沙之後,我就暫停了我的學習(事情比較複雜,心情也很複雜)。
都知道go高併發能力特別強,並且是利用他的協程去控制(通常的做法都是goroutine+channel),那我今天就想看看,go是如何實現通道的!
預備知識
併發
最早的計算機,每次只能執行一個程式,只有噹噹前執行的程式結束後才能執行其它程式,在此期間,別的程式都得等著。到後來,計算機執行速度提高了,程式設計師們發現,單任務執行一旦陷入IO阻塞狀態,CPU就沒事做了,很是浪費資源,於是就想要同一時間執行那麼三五個程式,幾個程式一塊跑,於是就有了併發。原理就是將CPU時間分片,分別用來執行多個程式,可以看成是多個獨立的邏輯流,由於能快速切換邏輯流,看起來就像是大家一塊跑的。
執行緒 程序
先不看程式碼,我們想想,為什麼go採用協程+通道模式,現有的併發模型有哪幾種。
當然,我們這裡只討論多核模式下的情況(不談論什麼epoll、libevent之類的精巧設計)
-
多執行緒併發(執行緒是程序的一個實體,是CPU排程和分派的基本單位,它是比程序更小的能獨立執行的基本單位.執行緒自己基本上不擁有系統資源,只擁有一點在執行中必不可少的資源(如程式計數器,一組暫存器和棧),但是它可與同屬一個程序的其他的執行緒共享程序所擁有的全部資源。執行緒間通訊主要通過共享記憶體,上下文切換很快,資源開銷較少,但相比程序不夠穩定容易丟失資料。)
-
多程序併發 (程序是具有一定獨立功能的程式關於某個資料集合上的一次執行活動,程序是系統進行資源分配和排程的一個獨立單位
。每個程序都有自己的獨立記憶體空間,不同程序通過程序間通訊來通訊。由於程序比較重量,佔據獨立的記憶體,所以上下文程序間的切換開銷(棧、暫存器、虛擬記憶體、檔案控制代碼等)比較大,但相對比較穩定安全。)
可以看到:
在多核時代,為了更好地利用多核(壓榨cpu啊,畢竟硬體的摩爾定律快到頭了,不能像以前,加機器!哈哈哈)資源,還是有很多招式的!各位大俠,各顯神通。當然,我想表達的東西,也用粗體展現出來了。
代表:java(多執行緒)、php(多程序)
再說協程吧,其實協程的概念早就有了,go並不是它的發明者,而是它的利用者(協程最初在1963年被提出。),總之,就是更輕量級的任務排程,其中我認為最關鍵的一項就是,協程全部在使用者態就解決了排程問題。
原始碼分析
go的一切原始碼是皆可見的,因此我們很方便就能看到原始碼,原始碼檔案位於:
$GOROOT/src/runtime/chan.go
結構體
go的channel在原始碼裡定義為hchan
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
從命名,我們就能看出大多數的東西了。
其中我們主要要關注的應該是 recvq、sendq、lock
waitq結構如下:
type waitq struct {
first *sudog
last *sudog
}
原始碼追蹤下:
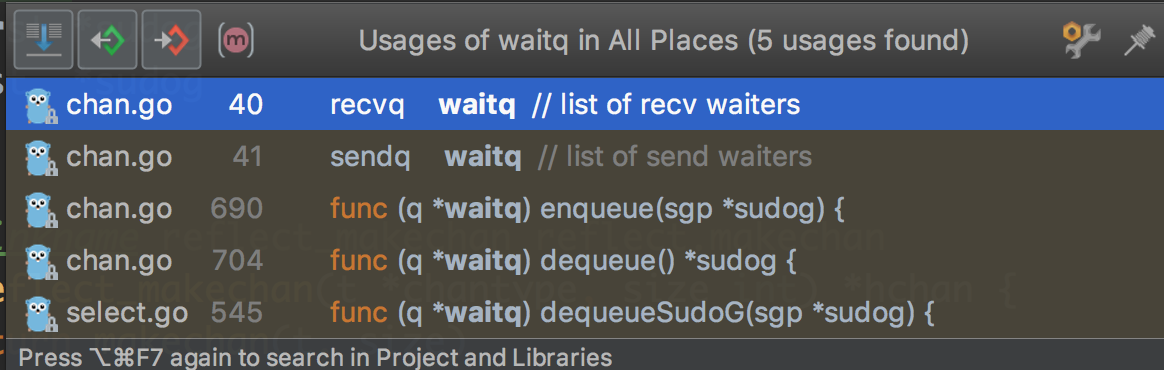
可以看出,waitq主要做的是一個物件的編解碼,這裡涉及runtime.go裡定義的一個物件,暫時不講解(*sudog: sudog represents a g in a wait list, such as for sending/receiving on a channel.)可以把它理解成一個等待的緩衝區(佇列)
那麼waitq的作用就是獲取一個佇列的的第一個和最後一個數據(至少從命名上看是這樣)
lock,顧名思義,那肯定就是鎖了
go是如何建立一個通道呢?
當你呼叫如下程式碼,你可曾想過它是如何被實現:
channel := make(chan interface{})
首先,chan會被對映到之前我們看到的那個結構體hchan,make自然更容易理解,就是建立嘛,和我們用其他常見的高階語言一樣,這裡就是建立物件,分配記憶體,設定GC標誌等等一系列操作。
所以,我們這麼理解,通道,也是一個物件(JAVA的思想,一切皆物件?)
然後,這個物件有什麼呢?
嗯,型別,大小,容積等等。
下面是官方對make(chan interface{})的說明
Channel: The channel's buffer is initialized with the specified buffer capacity. If zero, or the size is omitted, the channel is unbuffered.
其實際實現原始碼,在如下(1.11.5):
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
if size < 0 || uintptr(size) > maxSliceCap(elem.size) || uintptr(size)*elem.size > maxAlloc-hchanSize {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case size == 0 || elem.size == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.kind&kindNoPointers != 0:
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+uintptr(size)*elem.size, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(uintptr(size)*elem.size, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; elemalg=", elem.alg, "; dataqsiz=", size, "\n")
}
return c
}
原始碼中我們看到switch,我們只需看預設方式就好了,default
new(hchan)
果然,然後分配了一份記憶體用於儲存即將進來或者出去的goroutine。
這裡涉及一個很重要的方法,記憶體分配。
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer
從這裡我們可以得知,go小的物件是分配在per-P cache(至於per-P cache是啥,暫且不瞭解,我們可以把他看成一個比堆還快的區域)中,而大的物件是分配在堆中
channel排程
channel已經建好好,那麼他是如何進行排程的呢?
我們繼續追蹤原始碼,發現了這兩個東西,噢?這麼簡單,一個傳送一個接收?
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool)
那不正好對應
channel <-
<- channel
至於怎麼排程,且待下回分解,go是排程通道內容的
系列文章
go核心chan.go檔案分析解讀(一)go是如何構建一個通道的
go核心chan.go檔案分析解讀(二)go是