
數據庫原理 - 序列4 - 事務是如何實現的? - Redo Log解析(續)
> 本文節選自《軟件架構設計:大型網站技術架構與業務架構融合之道》第6.4章節。 作者微信公眾號:
> 架構之道與術。進入後,可以加入書友群,與作者和其他讀者進行深入討論。也可以在京東、天貓上購買紙質書。
## 6.5.5 Redo Log Block結構
Log Block還需要有Check sum的字段,另外還有一些頭部字段。事務可大可小,可能一個Block存不下產生的日誌數據,也可能一個Block能存下多個事務的數據。所以在Block裏面,得有字段記錄這種偏移量。
圖6-9展示了一個Redo Log Block的詳細結構,頭部有12字節,尾部Check sum有4個字節,所以實際一個Block能存的日誌數據只有496字節。
圖6-9 Redo Log Block詳細結構
頭部4個字段的含義分別如下:
Block No:每個Block的唯一編號,可以由LSN換算得到。
Date Len:該Block中實際日誌數據的大小,可能496字節沒有存滿。
First Rec Group:該Block中第一條日誌的起始位置,可能因為上一條日誌很大,上一個Block沒有存下,日誌的部分數據到了當前的Block。如果First Rec Group = Data Len,則說明上一條日誌太大,大到橫跨了上一個Block、當前Block、下一個Block,當前Block中沒有新日誌。
## 6.5.6 事務、LSN與Log Block的關系
知道了Redo Log的結構,下面從一個事務的提交開始分析,看事務和對應的Redo Log之間的關聯關系。假設有一個事務,偽代碼如下:
start transaction
update 表1某行記錄
delete 表1某行記錄
insert 表2某行記錄
commit
其產生的日誌,如圖6-10所示。應用層所說的事務都是“邏輯事務”,具體到底層實現,是“物理事務”,也叫作Mini Transaction(Mtr)。在邏輯層面,事務是三條SQL語句,涉及兩張表;在物理層面,可能是修改了兩個Page(當然也可能是四個Page,五個Page……),每個Page的修改對應一個Mtr。每個Mtr產生一部分日誌,生成一個LSN。
圖6-11展示了兩個邏輯事務,其對應的Redo Log在磁盤上的排列示意圖。可以看到,LSN是單調遞增的,但是兩個事務對應的日誌是交叉排列的。
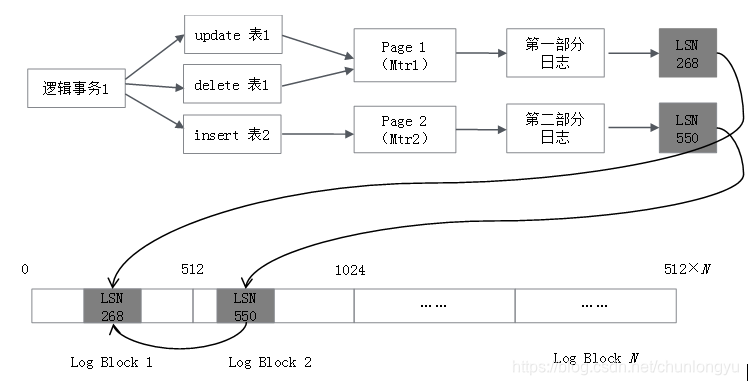
圖6-10 事務與產生的Redo Log對應關系
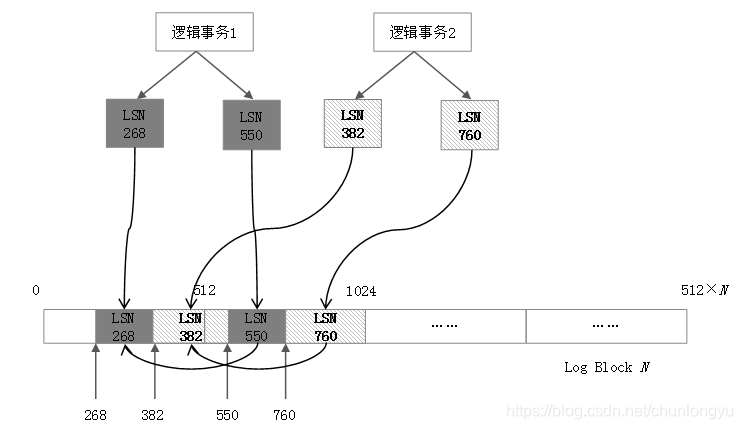
圖6-11 兩個邏輯事務的Redo Log在磁盤上排列示意圖
同一個事務的多條LSN日誌也會通過鏈表串聯,最終數據結構類似表6-9。其中,TxID是InnoDB為每個事務分配的一個唯一的ID,是一個單調遞增的整數。
表6-9 Redo Log與LSN和事務的關系

## 6.5.7 事務Rollback與崩潰恢復(ARIES算法)
**1.未提交事務的日誌也在Redo Log中**
通過上面的分析,可以看到不同事務的日誌在Redo Log中是交叉存在的,這意味著未提交的事務也在Redo Log中!因為日誌是交叉存在的,沒有辦法把已提交事務的日誌和未提交事務的日誌分開,或者說前者刷到磁盤的Redo Log上面,後者不刷。比如圖6-11的場景,邏輯事務1提交了,要把邏輯事務1的Redo Log刷到磁盤上,但中間夾雜的有邏輯事務2的部分Redo Log,邏輯事務2此時還沒有提交,但其日誌會被“連帶”地刷到磁盤上。
所以這是ARIES算法的一個關鍵點,不管事務有沒有提交,其日誌都會被記錄到Redo Log上。當崩潰後再恢復的時候,會把Redo Log全部重放一遍,提交的事務和未提交的事務,都被重放了,從而讓數據庫“原封不動”地回到宕機之前的狀態,這叫Repeating History。
重放完成後,再把宕機之前未完成的事務找出來。這就有個問題,怎麽把宕機之前未完成的事務全部找出來?這點講Checkpoint時會詳細介紹。
把未完成的事務找出來後,逐一利用Undo Log回滾。
**2.Rollback轉化為Commit**
回滾是把未提交事務的Redo Log刪了嗎?顯然不是。在這裏用了一個巧妙的轉化方法,把回滾轉化成為提交。
如圖6-12所示,客戶端提交了Rollback,數據庫並沒有更改之前的數據,而是以相反的方向生成了三個新的SQL語句,然後Commit,所以是邏輯層面上的回滾,而不是物理層面的回滾。

圖6-12 一個Rollback事務被轉換為Commit事務示意圖
同樣,如果宕機時一個事務執行了一半,在重啟、回滾的時候,也並不是刪除之前的部分,而是以相反的操作把這個事務“補齊”,然後Commit,如圖6-13所示。

圖6-13 宕機未完成的事務被轉換成Commit事務
這樣一來,事務的回滾就變得簡單了,不需要改之前的數據,也不需要改Redo Log。相當於沒有了回滾,全部都是Commit。對於Redo Log來說,就是不斷地append。這種逆向操作的SQL語句對應到Redo Log裏面,叫作Compensation Log Record(CLR),會和正常操作的SQL的Log區分開。
**3.ARIES恢復算法**
如圖6-14所示,有T0~T5共6個事務,每個事務所在的線段代表了在Redo Log中的起始和終止位置。發生宕機時,T0、T1、T2已經完成,T3、T4、T5還在進行中,所以回滾的時候,要回滾T3、T4、T5。
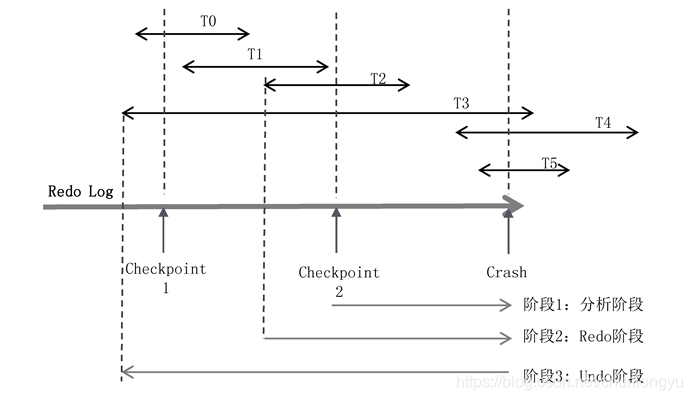
圖6-14 ARIES算法示意圖
ARIES算法分為三個階段:
**(1)階段1:分析階段**
分析階段,要解決兩個核心問題。
第一,確定哪些數據頁是臟頁,為階段2的Redo做準備。發生宕機時,雖然T0、T1、T2已經提交了,但只是Redo Log在磁盤上,其對應的數據Page是否已經刷到磁盤上不得而知。如何找出從Checkpoint到Crash之前,所有未刷盤的Page呢?
第二,確定哪些事務未提交,為階段3的Undo做準備。未提交事務的日誌也寫入了Redo Log。對應到此圖,就是T3、T4、T5的部分日誌也在Redo Log中。如何判斷出T3、T4、T5未提交,然後對其回滾呢?
這就要談到ARIES的Checkpoint機制。Checkpoint是每隔一段時間對內存中的數據拍一個“快照”,或者說把內存中的數據“一次性”地刷到磁盤上去。但實際上這做不到!因為在把內存中所有的臟頁往磁盤上刷的時候,數據庫還在不斷地接受客戶端的請求,這些臟頁一直在更新。除非把系統阻塞住,不再接受前端的請求,這時Redo Log也不再增長,然後一次性把所有的臟頁刷到磁盤中,叫作Sharp Checkpoint。
Sharp Checkpoint的應用場景很狹窄,因為系統不可能停下來,所以用的更多的是Fuzzy Checkpoint,具體怎麽做呢?
在內存中,維護了兩個關鍵的表:活躍事務表(表6-10)和臟頁表(表6-11)。
活躍事務表是當前所有未提交事務的集合,每個事務維護了一個關鍵變量lastLSN,是該事務產生的日誌中最後一條日誌的LSN。
表6-10 活躍事務表

臟頁表是當前所有未刷到磁盤上的Page的集合(包括了已提交的事務和未提交的事務),recoveryLSN是導致該Page為臟頁的最早的LSN。比如一個Page本來是clean的(內存和磁盤上數據一致),然後事務1修改了它,對應的LSN是LSN1;之後事務2、事務3又修改了它,對應的LSN分別是LSN2、LSN3,這裏recoveryLSN取的就是LSN1。
表6-11 臟頁表

所謂的Fuzzy Checkpoint,就是對這兩個關鍵表做了一個Checkpoint,而不是對數據本身做Checkpoint。這點非常巧妙!因為Page本身很多、數據量大,但這兩個表記錄的全是ID,數據量很小,很容易備份。
所以,每一次Fuzzy Checkpoint,就把兩個表的數據生成一個快照,形成一條Checkpoint日誌,記入Redo Log。
基於這兩個關鍵表,可以求取兩個問題:
問題(1):求取Crash的時候,未提交事務的集合。
以圖6-14為例,在最近的一次Checkpoint 2時候,未提交事務集合是{T2,T3},此時還沒有T4、T5。從此處開始,遍歷Redo Log到末尾。
在遍歷的過程中,首先遇到了T2的結束標識,把T2從集合中移除,剩下{T3};
之後遇到了事務T4的開始標識,把T4加入集合,集合變為{T3,T4};
之後遇到了事務T5的開始標識,把T5加入集合,集合變為{T3,T4,T5}。
最終直到末尾,沒有遇到{T3,T4,T5}的結束標識,所以未提交事務是{T3,T4,T5}。
圖6-15展示了事務的開始標識、結束標識以及Checkpoint在Redo Log中的排列位置。其中的S表示Start transaction,事務開始的日誌記錄;C表示Commit,事務結束的日誌記錄。每隔一段時間,做一次Checkpoint,會插入一條Checkpoint日誌。Checkpoint日誌記錄了Checkpoint時所對應的活躍事務的列表和臟頁列表(臟頁列表在圖中未展示)。
問題(2):求取Crash的時候,所有未刷盤的臟頁集合。
假設在Checkpoint2的時候,臟頁的集合是{P1,P2}。從Checkpoint開始,一直遍歷到Redo Log末尾,一旦遇到Redo Log操作的是新的Page,就把它加入臟頁集合,最終結果可能是{P1,P2,P3,P4}。
這裏有個關鍵點:從Checkpoint2到Crash,這個集合會只增不減。可能P1、P2在Checkpoint之後已經不是臟頁了,但把它認為是臟頁也沒關系,因為Redo Log是冪等的。
圖6-15 事務在Redo Log上排列示意圖
階段2:進行Redo
假設最後求出來的臟頁集合是{P1,P2,P3,P4,P5}。在這個集合中,可能都是真的臟頁,也可能是已經刷盤了。取集合中所有臟頁的recoveryLSN的最小值,得到firstLSN。從firstLSN遍歷Redo Log到末尾,把每條Redo Log對應的Page全部重刷一次磁盤。
關鍵是如何做冪等?磁盤上的每個Page有一個關鍵字段——pageLSN。這個LSN記錄的是這個Page刷盤時最後一次修改它的日誌對應的LSN。如果重放日誌的時候,日誌的LSN <= pageLSN,則不修改日誌對應的Page,略過此條日誌。
如圖6-16所示,Page1被多個事務先後修改了三次,在Redo Log的時間線上,分別對應的日誌的LSN為600、900、1000。當前在內存中,Page1的pageLSN = 1000(最新的值),因為還沒來得及刷盤,所以磁盤中Page1的pageLSN = 900(上一次的值)。現在,宕機重啟,從LSN=600的地方開始重放,從磁盤上讀出來pageLSN = 900,所以前兩條日誌會直接過濾掉,只有LSN = 1000的這條日誌對應的修改操作,會被作用到Page1中。
圖6-16 pageLSN實現Redo Log冪等示意圖
這點與TCP在接收端對數據包的判重有異曲同工之妙!在TCP中,是對發送的數據包從小到大編號(seq number),這裏是對所有日誌從小到大編號(LSN),接收的一方發現收到的日誌編號比之前的還要小,就說明不用重做了。
有了這種判重機制,我們就實現了Redo Log重放時的冪等。從而可以從firstLSN開始,將所有日誌全部重放一遍,這裏面包含了已提交事務和未提交事務的日誌,也包含對應的臟頁或者幹凈的頁。
Redo完成後,就保證了所有的臟頁都成功地寫入到了磁盤,幹凈頁也可能重新寫入了一次。並且未提交事務T3、T4、T5對應的Page數據也寫入了磁盤。接下來,就是要對T3、T4、T5回滾。
階段3:進行Undo
在階段1,我們已經找出了未提交事務集合{T3,T4,T5}。從最後一條日誌逆向遍歷,因為每條日誌都有一個prevLSN字段,所以可以沿著T3、T4、T5各自的日誌鏈一直回溯,最終直到T3的第一條日誌。
所謂的Undo,是指每遇到一條屬於T3、T4、T5的Log,就生成一條逆向的SQL語句來執行,其執行對應的Redo Log是Compensation Log Record(CLR),會在Redo Log尾部繼續追加。所以對於Redo Log來說,其實不存在所謂的“回滾”,全部是正向的Commit,日誌只會追加,不會執行“物理截斷”之類的操作。
要生成逆向的SQL語句,需要記錄對應的歷史版本數據,這點將在分析Undo Log的時候詳細解釋。
這裏要註意的是:Redo的起點位置和Undo的起點位置並沒有必然的先後關系,圖中畫的是Undo的起點位置小於Redo的起點位置,但實際也可以反過來。以為Redo對應的是所有臟頁的最小LSN,Undo對應的是所有未提交事務的起始LSN,兩者不是同一個維度的概念。
在進行Undo操作的時候,還可能會遇到一個問題,回滾到一半,宕機,重啟,再回滾,要進行“回滾的回滾”。
如圖6-17所示,假設要回滾一個未提交的事務T,其有三條日誌LSN分別為600、900、1000。第一次宕機重啟,首先對LSN=1000進行回滾,生成對應的LSN=1200的日誌,這條日誌裏會有一個字段叫作UndoNxtLSN,記錄的是其對應的被回滾的日誌的前一條日誌,即UndoNxtLSN = 900。這樣當再一次宕機重啟時,遇到LSN=1200的CLR,首先會忽略這條日誌;然後看到UndoNxtLSN = 900,會定位到LSN=900的日誌,為其生成對應的CLR日誌LSN=1600;然後繼續回滾,LSN=1700的日誌,回滾的是LSN=600。
這樣,不管出現幾次宕機,重啟後最終都能保證回滾日誌和之前的日誌一一對應,不會出現“回滾嵌套”問題。
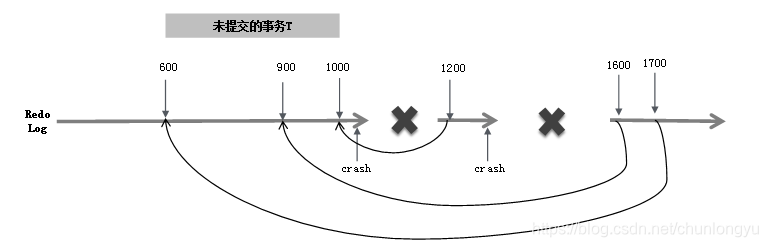
圖6-17 回滾過程中出現宕機後再次重啟回滾
到此為止,已經對事務的A(原子性)和D(持久性)有了一個全面的理解,接下來將討論I的實現。在此先對Redo Log做一個總結:
(1) 一個事務對應多條Redo Log,事務的Redo Log不是連續存儲的。
(2) Redo Log不保證事務的原子性,而是保證了持久性。無論提交的,還是未提交事務的日誌,都會進入Redo Log。從而使得Redo Log回放完畢,數據庫就恢復到宕機之前的狀態,稱為Repeating History。
(3) 同時,把未提交的事務挑出來並回滾。回滾通過Checkpoint記錄的“活躍事務表”+ 每個事務日誌中的開始/結束標記 + Undo Log 來實現。
(4) Redo Log具有冪等性,通過每個Page裏面的pageLSN實現。
(5) 無論是提交的、還是未提交的事務,其對應的Page數據都可能被刷到了磁盤中。未提交的事務對應的Page數據,在宕機重啟後會回滾。
(6) 事務不存在“物理回滾”,所有的回滾操作都被轉化成了Commit。
數據庫原理 - 序列4 - 事務是如何實現的? - Redo Log解析(續)