
阿里靠什麼支撐 EB 級計算力?

阿里妹導讀:MaxCompute 是阿里EB級計算平臺,經過十年磨礪,它成為阿里巴巴集團資料中臺的計算核心和阿里雲大資料的基礎服務。去年MaxCompute 做了哪些工作,這些工作背後的原因是什麼?大資料市場進入普惠+紅海的新階段,如何與生態發展共贏?人工智慧進入井噴階段,如何支援與借力?本文從過去一年的總結,核心技術概覽,以及每條技術線路未來展望等幾個方面做一個概述。
BigData 概念在上世紀90年代被提出,隨 Google 的3篇經典論文(GFS,BigTable,MapReduce)奠基,已經發展了超過10年。這10年中,誕生了包括Google 大資料體系,微軟 Cosmos 體系,開源 Hadoop 體系等優秀的系統,這其中也包括阿里雲的飛天系統。這些系統一步一步推動業界進入“數字化“和之後的“ AI 化”的時代。
同時,與其他老牌系統相比(如,Linux 等作業系統體系,資料庫系統、中介軟體,很多有超過30年的歷史),大資料系統又非常年輕,隨著雲端計算的普惠,正在大規模被應用。海量的需求和迭代推動系統快速發展,有蓬勃的生機。(技術體系的發展,可以通過如下 Hype-Cycle 概述,作者認為,大資料系統的發展進入技術復興期/Slope of Enlightenment,並開始大規模應用 Plateau of Productivity。)
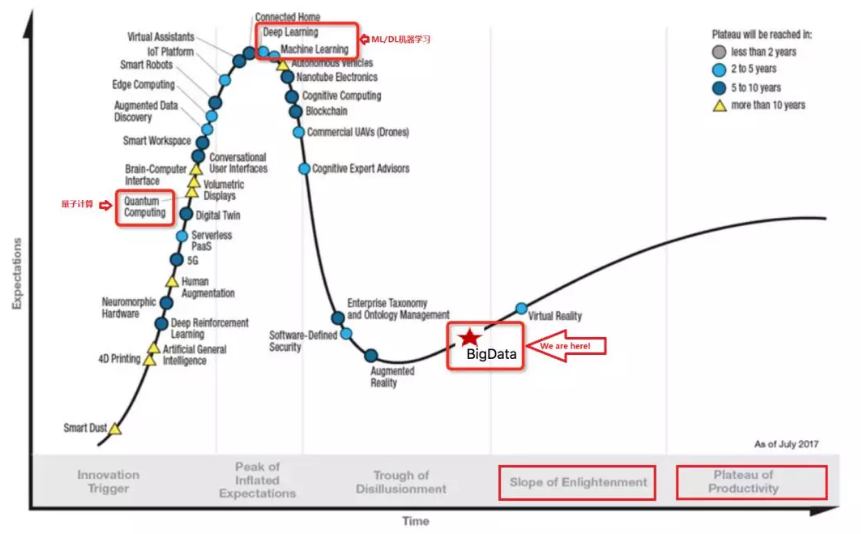
如果說,0到1上線標誌一個系統的誕生,在集團內大規模部署標誌一個系統的成長,在雲上對外大規模服務標誌一個系統的成熟。
MaxCompute 這10年已經走向成熟,經過多次升級換代,功能、效能、服務、穩定性已經有一個體系化的基礎,成為阿里巴巴集團資料中臺的計算核心和阿里雲大資料的基礎服務。
1. MaxCompute(ODPS)概述
1.1 背景資訊:十年之後,回頭看什麼是大資料
"Big data represents the information assets characterized by such a high volume, velocity and variety torequire specific technology and analytical methods for its transformation intovalue. "
用5個“V”來描述大資料的特點:
- Volume (資料量):資料量非線性增長,包括採集、儲存和計算的量都非常大,且增速很快。
- Variety (資料型別):包括結構化和非結構化的資料,特別是最近隨音檢視興起,非結構化資料增速更快。
- Velocity(資料儲存和計算的增長速度):資料增長速度快,處理速度快,時效性要求高。
- Veracity(信噪比):資料量越大,噪聲越多,需要深入挖掘資料來得到結果。
- Value(價值):資料作為一種資產,有 1+1>2 的特點。

1.3 競品對比與分析
大資料發展到今天,資料倉庫市場潛力仍然巨大,更多客戶開始選擇雲資料倉庫,CDW仍處於高速增長期。當前網際網路公司和傳統數倉廠家都有進入領導者地位,競爭激烈,阿里巴巴CDW在全球權威諮詢與服務機構Forrester釋出的《The Forrester WaveTM: CloudData Warehouse, Q4 2018》報告中位列中國第一,全球第七。
在 CDW 的領導者中,AWS Redshift 高度商業化、商業客戶部署規模領先整個市場,GoogleBigQuery 以高效能、高度彈性伸縮獲得領先,Oracle 雲數倉服務以自動化數倉技術獲得領先。
MaxCompute 當前的定位是市場競爭者,目標是成為客戶大資料的“航母”級計算引擎,解決客戶在物聯網、日誌分析、人工智慧等場景下日益增長的資料規模與計算效能下降、成本上升、複雜度上升、資料安全風險加大之間的矛盾。在此目標定位下,對 MaxCompute 在智慧數倉、高可靠性、高自動化、資料安全等方面的能力提出了更高的要求。
2. 2018年MaxCompute技術發展概述
過去的一個財年,MaxCompute 在技術發展上堅持在核心引擎、開放平臺、技術新領域等方向的深耕,在業務上繼續匠心打造產品,擴大業界影響力。
效率提升
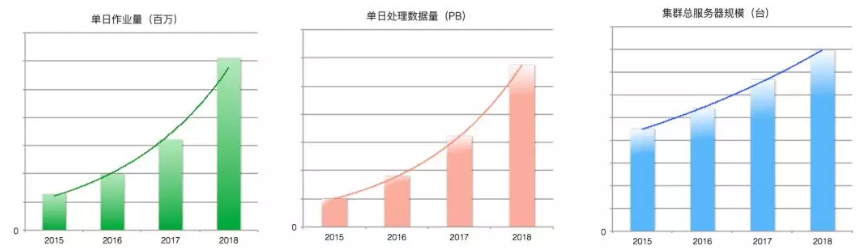
2018年9月雲棲大會發布,MaxCompute 在標準測試集 TPC-BB 100TB整體指標較2017年提升一倍以上。

得益於整體效率的提升,在集團內部 MaxCompute 以20%的硬體增長支撐了超過70%的業務增長。
系統開放性和與生態融合
- 聯合計算平臺 Cupid 逐步成熟,效能與 EMR Spark Benchmark 持平,支援K8S 介面,支援完整的框架安全體系,Spark On MaxCompute 已開始支援雲上業務。
- Python 分散式專案 MARS 正式釋出,開源兩週內收穫1200+ Star,填補了國內在 Python 生態上支援大規模分散式科學計算的空白,是競品 Dask 效能的3倍。
探索新領域
MaxCompute 持續在前沿技術領域投入,保持技術先進性。在下一代引擎方向,如:
- AdaptiveOperators
- Operator Fusion
- ClusteredTable
智慧數倉 Auto Datawarehouse 方向上的調研都取得了不錯的進展。在漸進計算、Advanced FailChecking and Recovery 、基於 ML的分散式計算平臺優化、超大資料量 Query 子圖匹配等多個方向上的調研也在進行中。
深度參與和推動全球大資料領域標準化建設
2018年11月,
MaxCompute 與 DataWorks/AnalyticDB一起代表阿里雲入選 Forrester Wave™ Q4 2018雲資料倉庫研究報告,在產品能力綜合得分上力壓微軟,排名全球第七,中國第一。
2019年3月,MaxCompute 正式代表 Alibaba 加入了 TPC 委員會推動融入和建立標準。
MaxCompute 持續在開源社群投入。成為全球兩大熱門計算儲存標準化開源體系 ORC 社群的 PMC,MaxCompute 成為近兩年貢獻程式碼量最多的貢獻者,引導儲存標準化;在全球最熱門優化器專案 Calcite,擁有一個專委席位,成為國內前兩傢俱備該領域影響力的公司,推動數十個貢獻。
3. 核心技術棧
大資料市場進入普惠+紅海的新階段,如何借力井噴階段中的人工智慧,如何與生態發展共贏?
基於橫向架構上的核心引擎和系統平臺,MaxCompute 在計算力、生態化、智慧化3個縱向上著力發展差異化的競爭力。
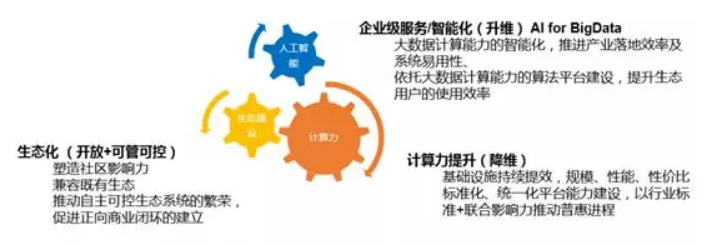
3.1 計算力
首先我們從計算力這個角度出發,介紹一下 MaxCompute 的技術架構。
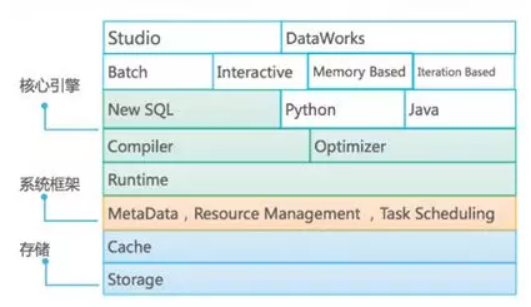
a.核心引擎
支撐 MaxCompute 的計算力的核心模組之一是其 SQL 引擎:在 MaxCompute 的作業中,有90%以上的作業是 SQL 作業,SQL 引擎的能力是 MaxCompute 的核心競爭力之一。
在 MaxCompute 產品框架中,SQL 引擎將使用者的 SQL 語句轉換成對應的分散式執行計劃來執行。SQL 引擎由3個主要模組構成:
- 編譯器 Compiler:對 SQL 標準有友好支援,支援100% TPC-DS 語法;並具備強大都錯誤恢復能力,支援 MaxCompute Studio 等先進應用。
- 執行時 Runtime:基於LLVM優化程式碼生產,支援列式處理與豐富的關係算符;基於 CPP 的執行時具有更高效率。
- 優化器 Optimizer:支援HBO和基於 Calcite 的 CBO, 通過多種優化手段不斷提升 MaxCompute 效能。
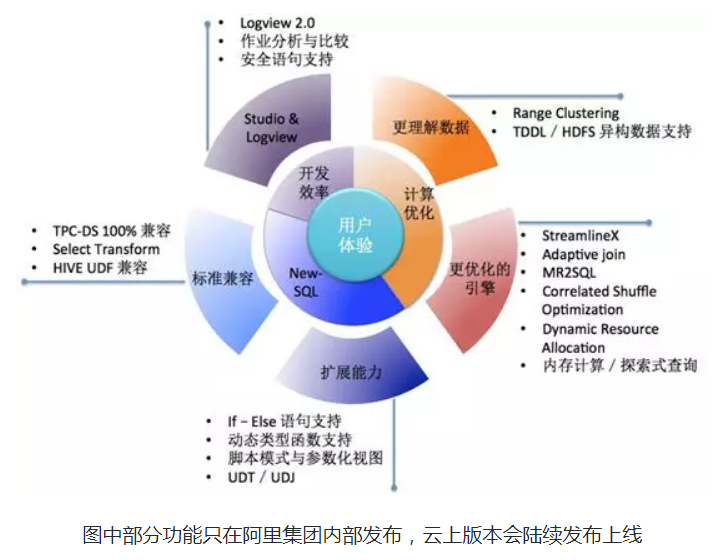
MaxComputeSQL 引擎當前的發展,以提升使用者體驗為核心目標,在 SQL 語言能力、引擎優化等多個方向上兼顧發力,建立技術優勢,在 SQL 語言能力方面, 新一代大資料語言 NewSQL 做到了 Declarative 語言和 Imperative 語言的融合,進一步提升語言相容性,目前已100% 支援 TPC-DS 語法。過去一年中,MaxCompute 新增了對 GroupingSets,If-Else 分支語句,動態型別函式,等方面的支援。
b.儲存
MaxCompute 不僅僅是一個計算平臺,也承擔著大資料的儲存。阿里巴巴集團99%的大資料儲存都基於 MaxCompute,提高資料儲存效率、穩定性、可用性,也是MaxCompute一直努力的目標。
MaxCompute 儲存層處於 MaxCompute Tasks 和底層盤古分散式檔案系統之間,提供一個統一的邏輯資料模型給各種各樣的計算任務。MaxCompute 的儲存格式演化,從最早的行存格式 CFile1,到第一個列儲存格式 CFile2,到第三代儲存格式。支援更復雜的編碼方式,非同步預讀等功能,進一步提升效能。在儲存和計算2個方面都帶來了效能的提升。儲存成本方面,在阿里巴巴集團內通過 新一代的列存格式節省約8%儲存空間,直接降低約1億成本;在計算效率上,過去的一個財年中釋出的每個版本之間都實現了20%的提升。目前在集團內大規模落地的過程中。
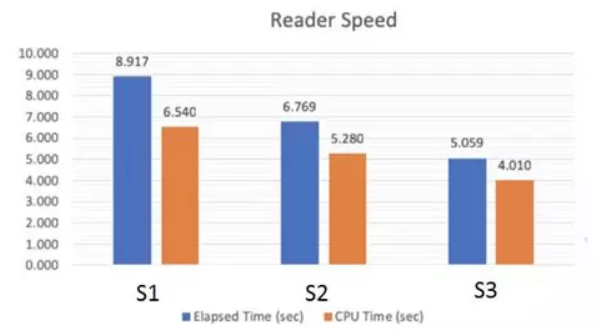
在歸檔以及壓縮方面,MaxCompute 支援 ZSTD 壓縮格式,以及壓縮策略,使用者可以在 Normal,High 和 Extreme 三種 Stategy 裡面選擇。更高的壓縮級別,帶來更高效的儲存,但也意味著更高的讀寫 CPU 代價。
2018年, MaxCompute 陸續推出了 Hash Clustering 和 Range Clustering 支援富結構化資料,並持續的進行了深度的優化,例如增加了 ShuffleRemove,Clustering Pruning 等優化。從線上試用資料,以及大量的 ATA 使用者實踐案例也可以看出,Clustering 的收益也獲得了使用者的認可。
c.系統框架
資源與任務管理:MaxCompute 框架為 ODPS 上面各種型別的計算引擎提供穩定便捷的作業接入管理介面,管理著 ODPS 各種型別 Task 的生命週期。過去一年對短作業查詢的持續優化,縮短 e2e 時間,加強對異常作業(OOM)的自動檢測與隔離處理,全面開啟服務級別流控,限制作業異常提交流量,為服務整體穩定性保駕護航。
MaxCompute 儲存著海量的資料,也產生了豐富的資料元資料。在離線元倉統計T+1的情況下,使用者至少需要一天後才能做事後的資料風險審計,現實場景下使用者希望更早風險控制,將資料訪問事件和專案空間授權事件通過 CUPID 平臺實時推送到使用者 DataHub 訂閱,使用者可以通過消費 DataHub 實時獲取專案空間表、volume資料被誰訪問等。
元資料管理:元資料服務支撐了 MaxCompute 各個計算引擎及框架的執行。每天執行在 MaxCompute 的作業,都依賴元資料服務完成 DDL,DML 以及授權及鑑權的操作。元資料服務保障了作業的穩定性和吞吐率,保障了資料的完整性和資料訪問的安全性。元資料服務包含了三個核心模組:
- Catalog :完成DDL,DML及DCL(許可權管理)的業務邏輯,Catalog保障MaxCompute作業的ACID特性。
- MetaServer:完成元資料的高可用儲存和查詢能力。
- AuthServer:是高效能和高QPS的鑑權服務,完成對 MaxCompute 的所有請求的鑑權,保障資料訪問安全。
元資料服務經過了模組化和服務化後,對核心事務管理引擎做了多次技術升級,通過資料目錄多版本,元資料儲存重構等改造升級,保障了資料操作的原子性和強一致,並提高了作業提交的隔離能力,並保障了線上作業的穩定性。
在資料安全越來越重要的今天,元資料服務和阿里巴巴集團安全部合作,許可權系統升級到了2.0。核心改進包括:
- MAC(強制安全控制)及安全策略管理:讓專案空間管理員能更加靈活地控制使用者對列級別敏感資料的訪問,強制訪問控制機制(MAC)獨立於自主訪問控制機制(DAC)。
- 資料分類分級:新增資料的標籤能力,支援對資料做隱私類資料打標。
- 精細許可權管理:將ACL的管控能力拓展到了 Package 內的表和資源,實現欄位級的許可權的精細化管理。
系統安全:系統安全方面,MaxCompute 通過綜合運用計算虛擬化和網路虛擬化技術,為雲上多租戶各自的使用者自定義程式碼邏輯提供了安全而且完善的計算和網路隔離環境。
SQL UDF(python udf 和 java udf),CUPID聯合計算平臺(Sparks/Mars等),PAI tensorflow 等計算形態都基於這套統一的基礎隔離系統構建上層計算引擎。
MaxCompute 還通過提供原生的儲存加密能力,抵禦非授權訪問儲存裝置的資料洩露風險。MaxCompute 內建的儲存加密能力,可以基於KMS雲服務支援使用者自定義祕鑰(BYOK)以及AES256加密演算法,並計劃提供符合國密合規要求的SM系列加密演算法支援。
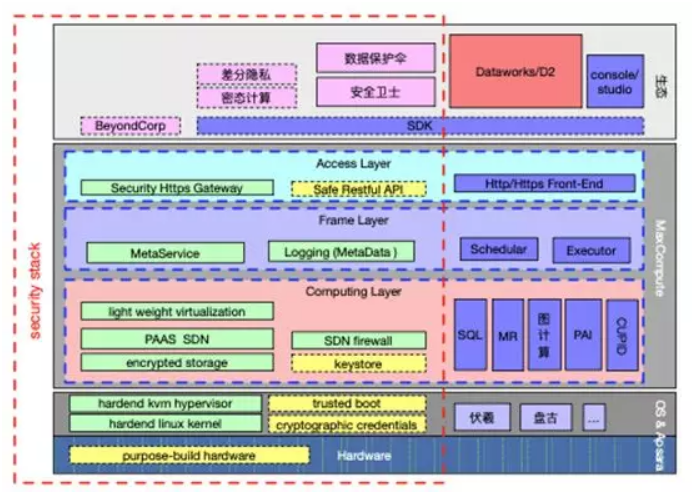
結合MaxCompute元倉(MetaData)提供的安全審計能力和元資料管理(MetaService)提供的安全授權鑑權能力,以及資料安全生態中安全衛士和資料保護傘等安全產品,就構成了 MaxCompute安全棧完整大圖。
3.2 生態化
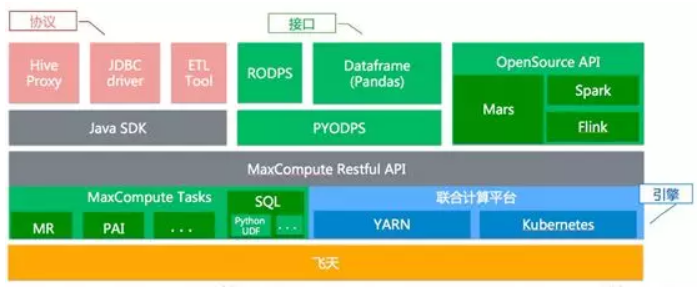
作為一個大規模資料計算平臺,MaxCompute 擁有來自各類場景的EB級資料,需要快速滿足各類業務發展的需要。在真實的使用者場景中,很少有使用者只用到一套系統:使用者會有多份資料,或者使用多種引擎。聯合計算融合不同的資料,豐富 MaxCompute 的資料處理生態,打破資料孤島, 打通阿里雲核心計算平臺與阿里雲各個重要儲存服務之間的資料鏈路。聯合計算也融合不同的引擎,提供多種計算模式,支援開源生態。開源能帶來豐富和靈活的技術以賦能業務,通過相容開源API對接開源生態。另一方面,在開源過程中我們需要解決最小化引入開源技術成本及打通資料、適配開源介面等問題。
**a.Cupid 聯合計算平臺
**
聯合計算平臺 Cupid 使一個平臺能夠支援 Spark、Flink、Tensorflow、Numpy、ElasticSearch 等多種異構引擎, 在一份資料上做計算。在資料統一、資源統一的基礎上,提供標準化的介面,將不同的引擎融合在一起做聯合計算。
Cupid 的工作原理是通過將 MaxCompute 所依賴的 Fuxi 、Pangu 等飛天組間介面適配成開源領域常見的 Yarn、HDFS 介面,使得開源引擎可以順利執行。現在,Cupid 新增支援了 Kubernetes 介面,使得聯合計算平臺更加開放。
案例:Spark OnMaxCompute
Spark 是聯合計算平臺第一個支援的開源引擎。基於 Cupid 的 Spark on MaxCompute 實現了與 MaxCompute 資料/元資料的完美整合;遵循 MaxCompute 多租戶許可權及安全體系;與Dataworks、PAI平臺整合;支援 Spark Streaming,Mllib, GraphX,Spark SQL,互動式等完整 Spark生態;支援動態資源伸縮等。
b.多源異構資料的互聯互通
隨著大資料業務的不斷擴充套件,新的資料使用場景在不斷產生,使用者也期望把所有資料放到一起計算,從而能取得 1+1 > 2 這樣更好的結果。
MaxCompute 提出了聯合計算,將計算下推,聯動其他系統:將一個作業在多套系統聯動,利用起各個系統可行的優化,做最優的決策,實現資料之間的聯動和打通。
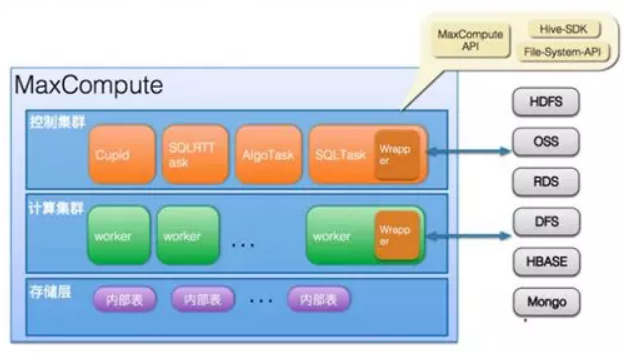
圖為MaxCompute集團內和專有云能力,公共雲已實現與OSS、OTS的資料互通
MaxCompute 通過異構資料支援來提供與各種資料的聯通,這裡的“各種資料”是兩個維度上的:
- 多樣的資料儲存介質(外部資料來源),外掛式的框架可以對接多種資料儲存介質。當前支援的外部資料來源有:
- OSS
- TableStore(OTS)
- TDDL
- Volume
- 多樣的資料儲存格式:開源的資料格式支援,如 ORC、Parquet 等;半結構化資料,如包括 CSV、Json等隱含一定schema 的文字檔案;完全無結構資料,如對OSS上的文字,音訊、影象及其他開源格式的資料進行計算。
基於MaxCompute 異構資料支援,使用者通過一條簡單的 DDL 語句即可在 MaxCompute 上建立一張EXTERNAL TABLE(外表),建立 MaxCompute 表與外部資料來源的關聯,提供各種資料的接入和輸出能力。
建立好的外表在大部分場景中可以像普通的 MaxCompute 表一樣使用,充分利用 MaxCompute 的強大計算力和資料整合、作業排程等功能。MaxCompute 外表支援不同資料來源之間的 Join,支援資料融合分析,從而幫助您獲得通過查詢獨立的資料孤島無法獲得的獨特見解。從而MaxCompute 可以把資料查詢從資料倉庫擴充套件到EB級的資料湖(如OSS),快速分析任何規模的資料,沒有MaxCompute儲存成本,無需載入或 ETL。
異構資料支援是MaxCompute 2.0升級中的一項重大更新,意在豐富 MaxCompute 的資料處理生態,打破資料孤島,打通阿里雲核心計算平臺與阿里雲各個重要儲存服務之間的資料鏈路。
c.Python 生態和 MARS科學計算引擎
MaxCompute 的開源生態體系中,對 Python 的支援主要包括 PyODPS、Python UDF、和MARS。
PyODPS 一方面是 MaxCompute 的 PythonSDK,同時也提供 DataFrame 框架,提供類似 pandas 的語法,能利用 MaxCompute 強大的處理能力來處理超大規模資料。基於 MaxCompute 豐富的使用者自定義函式(UDF)支援,使用者可以在 ODPS SQL 中編寫 Python UDF 來擴充套件 ODPS SQL。 MARS 則是為了賦能 MaxCompute 科學計算,全新開發的基於矩陣的統一計算框架。使用 Mars 進行科學計算,不僅能大幅度減少分散式科學計算程式碼編寫難度,在效能上也有大幅提升。
3.3 智慧化
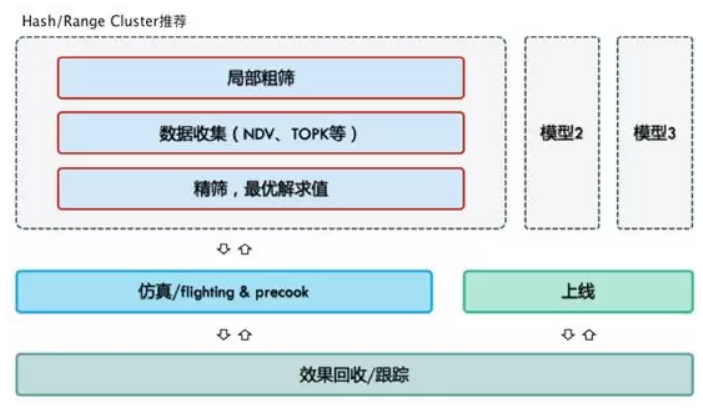
隨著大資料的發展,我們在幾年前就開始面對資料/作業爆發式增長的趨勢。面對百萬計的作業和表,如何做管理呢?MaxCompute 通過對歷史作業特徵的學習、基於對資料和作業的深刻理解,讓 MaxCompute 上的業務一定程度實現自適應調整,讓演算法和系統幫助使用者自動、透明、高效地進行數倉管理和重構優化工作,實現更好地理解資料,實現資料智慧排布和作業全球排程,做到大資料處理領域的“自動駕駛”,也就是我們所說的Auto DataWarehousing。
Auto Data Warehousing 在線上真實的業務中,到底能做什麼呢?我們以Hash Clustering 的自動推薦來小試牛刀。Hash Clustering 經過一年多的發展,功能不斷完善,但對使用者來說,最難的問題仍然在於,給哪些表建立怎樣的 Clustering 策略是最佳的方案?
MaxCompute 基於 Auto Data Warehousing,來實現為使用者推薦如何使用 HashClustering,回答如何選擇 Table、如何設定Cluteringkey 和分桶數等問題,讓使用者在海量資料、海量作業、快速變化的業務場景下,充分利用平臺功能。
4. 商業化歷程
從2009年雲梯到 ODPS,再到 MaxCompute,MaxCompute(ODPS) 這個大資料平臺已經發展了十年。回顧 MaxCompute 的發展,首先從雲梯到完成登月,成為了一個統一的大資料平臺。
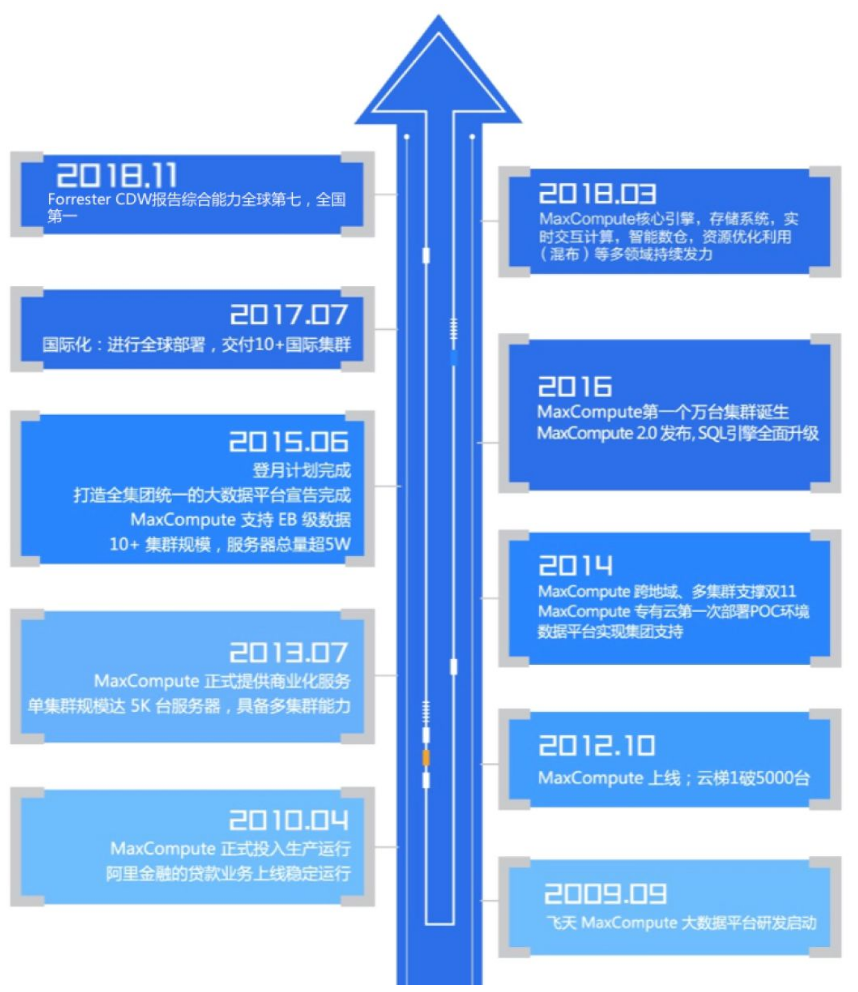
2014年,MaxCompute 開始商業化的歷程,走出集團、向公共雲和專有云輸出,直面中國、乃至全球的使用者。面對挑戰,MaxCompute 堅持產品核心能力的增強,以及差異化能力的打造, 贏得了客戶的選擇。回顧上雲歷程,公共雲的第一個節點華東2上海在2014(13年)年7月開服,經過4年多發展,MaxCompute 已在全球部署18個Region,為雲上過萬家使用者提供大資料計算服務,客戶已覆蓋了新零售、傳媒、社交、網際網路金融、健康、教育等多個行業。專有云的起點則從2014年8月第一套POC環境部署開始,發展至今專有云總機器規模已超過10000臺;輸出專案150+套,客戶涵蓋城市大腦,大安全,稅務,等多個重點行業。
今天,MaxCompute 在全球有超過十萬的伺服器,通過統一的作業排程系統和統一的元資料管理,這十萬多臺伺服器就像一臺計算機,為全球使用者提供提供包括批計算、流計算、記憶體計算、機器學習、迭代等一系列計算能力。這一整套計算平臺成為了阿里巴巴經濟體,以及阿里雲背後計算力的強有力支撐。MaxCompute 作為一個完整的大資料平臺,將不斷以技術驅動平臺和產品化發展,讓企業和社會能夠擁有充沛的計算能力,持續快速進化,驅動數字中國。
原文連結
本文為雲棲社群原創內容,未經