
Coding and Paper Letter(六十四)
資源整理。
1 Coding:
1.互動式瓦片編輯器。
2.R語言包autokeras,autokeras的R介面。autokeras是一個開源的自動機器學習的軟體。
3.斯坦福網路分析平臺,用於網路分析與圖挖掘學習。
4.高階NLP與spaCy:免費線上課程。
5.Python科學堆疊,編譯為WebAssembly。它提供了Javascript和Python之間物件的透明轉換。
6.中國 R 會議會場資訊。
7.致力於提高公民科學家對生物多樣性取樣的演算法
8.適用於21世紀的終端模擬器。
9.資料工匠:R的地理空間柵格和向量資料簡介,公開課程。
10.用於資料科學的ML產品的AutoML專案。 此工具允許使用者上傳資料集,只需單擊一下即可執行。R語言版。
11.R語言包phangorn,phangorn是R語言中用於系統發育重建和分析的包。 Phangorn提供了使用基於距離的方法,最大簡約性或最大似然(ML)和執行Hadamard共軛來重建系統發育的可能性。
12.一份精心挑選的中文Quant相關資源索引。
13.h2o機器學習平臺的教程和訓練材料。
14.R語言包quanteda,用於文字資料定量分析的R包。
15.cvpr2019論文,極市團隊整理。
16.七天學會NodeJS,NodeJS的新手教程。
17.Nodejs學習筆記以及經驗總結,公眾號"程式猿小卡"。
18.drakeR包的使用者手冊。
19.R語言包projmgr,旨在更好地將專案管理整合到您的工作流程中,併為R編碼和資料分析等更激動人心的任務騰出時間。
20.R語言包robustlmm,提供了以穩健方式估計線性混合效應模型的功能。
21.Petri Kiuru在LakeKuivajärvi應用MyLake-C,重點關注氣體轉移速度。此版本的MyLake包括溶解氧和有機碳的新描述(有3個DOC池和2個POC池)以及溶解有機碳物種的描述。
22.此repo自動檢測LiDAR資料的物件。
23.R語言包TITAN2,TITAN2是閾值指標分類群分析的第二個R實現。
24..用MATLAB編寫的快速簡單的二維三角網格生成器,專為解決淺水方程的沿海模型而設計。
24.基於Qt開發的輕量級HTTP/HTTPS伺服器。
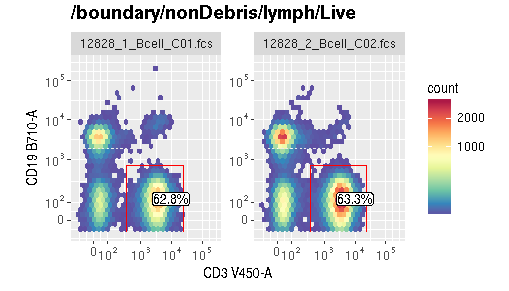
25.R語言包ggcyto,ggcyto是一種基於ggplot和圖形正規化語法構建的細胞計數資料視覺化工具。 該軟體擴充套件了許多資料科學家已經熟悉的流行ggplot2框架,使其能夠識別用於門控和註釋細胞計數資料的核心Bioconductor流式細胞儀資料結構。 它簡化了出版質量圖形的流資料的視覺化和繪圖。
26.比較fragstats中landscapemetrics的相關性,以構建最佳配置不一致度量。
27.R語言包epuRate,用於報告的乾淨R Markdown模板
28.censusapi是美國人口普查局API的訪問介面。 提供超過300種人口普查API終點,包括十年人口普查,美國社群調查,貧困統計和人口估計API。
29.Jiagu深度學習自然語言處理工具 中文分詞 詞性標註 命名實體識別 情感分析 知識圖譜關係抽取 新詞發現 關鍵詞 文字摘要。
30.R語言包croplandbias,該R包包含Estes等人的程式碼,資料和手稿的來源,文章"A Large-Area, Spatially Continuous Assessment of Land Cover Map Error and Its Impact on Downstream Analyses"已發表在生態學top期刊GCB上,所有資料(或者,在大型開放資料集[例如GLobCover 2009]的情況下,連結到下載位置)和處理步驟都包含在該包中。 對於此分析中使用的兩個專有資料集,此處提供了後處理版本,並且從那時起所有分析都應完全可重現。
31.Relay的實驗提前編譯器。
32.GitHub學習實驗室儲存庫,用於介紹GitHub,機器人。 GitHub學習實驗室機器人,幫助指導您學習和掌握本課程涵蓋的各種主題。 使用Issue和Pull Request評論與您溝通。
33.Python庫PVGeo,包含用於地球物理資料視覺化的VTK驅動工具,這些工具包裝在Kitware應用程式ParaView中直接使用。 這些工具專為地球科學中的資料視覺化而量身定製,重點關注結構化資料集,如2D或3D時變網格。
34.R語言包leafem,leafem為leaflet包提供擴充套件,其中許多包由mapview使用。 該軟體包的目的是增強leaflet功能,以便在互動式繪製空間資料時提供更像GIS的感覺。
35.一個MXNet實現的文章Drop a Octave:使用Octave卷積減少卷積神經網路中的空間冗餘。
36.ThunderGBM的使命是幫助使用者輕鬆有效地應用GBDT和隨機森林來解決問題。 ThunderGBM利用GPU實現高效率。 ThunderGBM的主要功能如下:通常是其他庫的10倍效率。支援Python(scikit-learn)介面。支援的作業系統:Linux和Windows。支援分類,迴歸和排序。
37.ThunderSVM的使命是幫助使用者輕鬆高效地應用SVM來解決問題。 ThunderSVM利用GPU和多核CPU實現高效率。 ThunderSVM的主要功能如下:支援LibSVM的所有功能,例如單類SVM,SVC,SVR和概率SVM。使用與LibSVM相同的命令列選項。支援Python,R和Matlab介面。支援的作業系統:Linux,Windows和MacOS。
38.Octave是一種類似於Matlab的高階(開源)程式語言。 我2011年斯坦福機器學習課程的octave練習。
39.QMUI iOS——致力於提高專案 UI 開發效率的解決方案
40.技術分享週刊,每週五發布。
41.2019春季課程:CS294; AI用於AI的系統和系統。
42.這段程式碼是用於模擬歷史和未來土地利用的計算機模型。 該模型採用一個或多個土地利用影象,並將為每個使用者定義的時間步長(例如一年)輸出土地利用的“預測”。 該模型基於元胞自動機和基於智慧體的建模的組合。
43.Haskell中的元胞自動機。 目的是在該軟體包中實現大多數元胞自動機,因此它可以作為編寫元胞自動機的參考/庫。
44.此儲存庫顯示了一個R markdown指令碼(exam.Rmd)的示例,該指令碼讀入考試問題的csv檔案並將其轉換為考試對應的格式。
45.這個儲存庫伴隨著我的書“資料視覺化:圖表,地圖和互動式圖形”,由CRC出版社於2018年與美國統計協會合作出版。它是CRC-ASA系列關於科學與社會統計推理的一部分。
46.一個帶pulp magazines CSS的bookdown模板。
47.Hotpot計劃是復旦留學申請資料開源計劃的代稱,旨在為復旦學弟學妹無償分享留學申請經驗、暑研動態、海外生活/工作等一切相關資訊。
48.Python庫elevation,全球地理高程資料下載變得簡單。 Elevation提供了輕鬆下載,快取和訪問由美國國家航空航天局和NGA託管在亞馬遜S3的全球資料集SRTM 30m和SRTM 90米數字高程資料庫。
49.R語言包subsemble,Subsemble演算法的R實現。 子集是一般子集集合預測方法,可用於小型,中型或大型資料集。 子集將完整資料集劃分為觀察子集,在每個子集上擬合指定的基礎演算法,並使用獨特形式的k折交叉驗證來輸出組合子集特定擬合的預測函式。
50.R語言包nvsmi,R的nvidia-smi介面,這可以通過NVML工作,並且不需要安裝nvidia-smi實用程式。 最終,該軟體包將具有完整的NVML介面。
51.該(建議)儲存庫包含2019年全球宜居性指標(“柳葉刀系列”)專案中使用的文件和流程。
52.Minie專案旨在改進Bullet Real-Time Physics與jMonkeyEngine遊戲引擎的整合。
53.這個repo包含我用來自動生成我的簡歷作為網頁的來源和來自YAML和BibTeX輸入的PDF。generate.py從cv.yaml和publication中讀取並使用Jinja模板輸出LaTeX和Markdown。
54.Python庫spcvm,多級空間相關方差分量模型。
55.R語言包ggcart,ggcart的目標是在傳統的阿爾伯斯地圖中包括波多黎各,維爾京群島和關島。 此外,ggcart將更容易在Albers投影中對映線,點和其他資料。
56.該儲存庫託管了Wilson和Wakefield撰寫的“無點連續空間表面重建”論文中執行模擬和資料分析所需的程式碼和資料。
57.R語言包live,區域性解釋(模型不可知)視覺解釋 - 基於LIME方法的迴歸問題和表格資料的模型視覺化。
58.Meshroom是一款基於AliceVision攝影測量計算機視覺框架的免費開源3D重建軟體。
59.R語言包nvctr,使用地球的橢圓體模型實現地理位置計算的n向量方法。
60.在NIMBLE中的“生態學應用層次建模”(Kéry和Royle)第一卷中執行WinBUGS/OpenBUGS/JAGS示例。
61.R語言包fullPage,fullPage.js, pagePiling.js和multiScroll.js的shiny框架。
62.該儲存庫是社群努力的一部分,用於收集,策劃和共享由drake R軟體包提供支援的公開可用的資料分析專案示例。 每個資料夾都是自己的示例,帶有一組自給自足的程式碼和資料檔案。 最終,您將能夠使用drake本身下載單個示例。
63.計劃召開澳大利亞再生性危機會議(2019年4月8日)
64.R語言包see,視覺化工具箱,適用於美觀和出版物。
65.R語言包RSelenium,Selenium Remote WebDriver的R客戶端,Selenium自動化測試神器+爬蟲神器。
66.R語言包tic,tic的目標是增強和簡化與Travis CI或AppVeyor for R專案等持續整合(CI)系統的協作。
67.R語言包shinyPlugins,shiny外掛是Shiny模組,當它們的命名符合指定條件時會自動新增到Shiny應用程式中。
68.nodejs庫,將GeoJSON檔案拆分為更小的部分。
69.Repo用於跟蹤已分享的有關Datacamp備選方案的所有連結。
70.R語言包bayestestR,用於分析貝葉斯模型和後驗分佈的實用程式。
71.R語言包mpoly,mpoly是一個簡單的工具集合,有助於在R中象徵性地和功能性地處理多元多項式。使用mp()函式定義多項式。
72.R語言包memer,一個tidyverse相容包,用於使用magick包在R中建立模因。
73.R語言包CytoML,該包用於使用gatingML2.0和FCS3.0細胞計資料標準將分層門控細胞計資料匯入/匯出R(特別是openCyto框架)。 該軟體包使用GatingSet R物件和資料模型,以便使用openCyto和ggCyto等工具輕鬆地在R中操作和視覺化匯入的資料。
74.一套整合的工具,用於基於指數族隨機圖模型(ERGM)分析和模擬網路。 'ergm'是用於網路分析的Statnet包套件的一部分。
75.R語言包scatterD3,基於D3.js的R散點圖htmlwidget。
76.Minimal Mistakes是一個靈活的兩列Jekyll主題,非常適合構建個人網站,部落格和投資組合。
77.R語言包rolldown,用於講故事的R Markdown輸出格式。
78.R語言包rbokeh,Bokeh的R介面。
79.論文"The Spatial and Temporal Domains of Modern Ecology"的倉庫,發表於Nature Ecology and Evolution。
80.R語言包plumber,將您的R程式碼轉換為Web API。
81.這是一個基於NSF Awards API的應用程式。 雖然NSF獎勵搜尋工具很棒,但這對於獲得NSF獎項的快速報告和統計資料非常有用。Python庫nsfsearch。
82.R語言包CompGLM,Conway-Maxwell-Poisson GLM和分佈函式。
83.Nabil在業餘時間工作的實驗3D水深測量觀察器。
84.R語言包synthesisr,實證研究專案的資料匯入和重複資料刪除。
85.Python庫pyfor,pyfor是一個Python包,可幫助處理森林庫存環境中的點雲資料。 這包括操縱點資料,支援分析以及用於管理大量點雲資料集的記憶體優化API。

86.構建通用GTFS資料的最佳實踐。GTFS是谷歌的資料結構。
87.一種資料格式,它將靈活的公共交通服務建模為GTFS的擴充套件。
88.適用於iOS,Android和Edge裝置的精彩移動機器學習資源的精選列表。
Awesome Mobile Machine Learing
89.SLAM的精彩資料集的精選列表。
90.Pytorch實現Octave卷積。
91.論文"CenterNet: Keypoint Triplets for Object Detection"的程式碼。
92.用於構建互動式R入門課程的倉庫。
93.PyTorch專案的可擴充套件模板,包括影象分割,物件分類,GAN和強化學習等示例。
94.awesome bot檢查檔案中的有效URL,它可用於驗證更新README的拉取請求。
95.R中用於程式設計和分析的有用程式碼。
96.來自Win / OpenBUGS,Nimble,CARBayes和INLA的BDM程式碼示例此儲存庫旨在作為一系列包含適合分層貝葉斯模型和小區域健康資料的包的程式碼示例的開源。 這些例子代表了一系列應用:空間;時空; 多變數,多尺度。 他們還重申了一系列軟體包:基於MCMC的軟體包,如Win / OpenBUGS,CARBayes,Nimble等; 通過INLA進行LAplace近似。
97.R語言包gprofiler,在R程式碼後面描述C ++。
98.MXNet上的人臉分析專案。

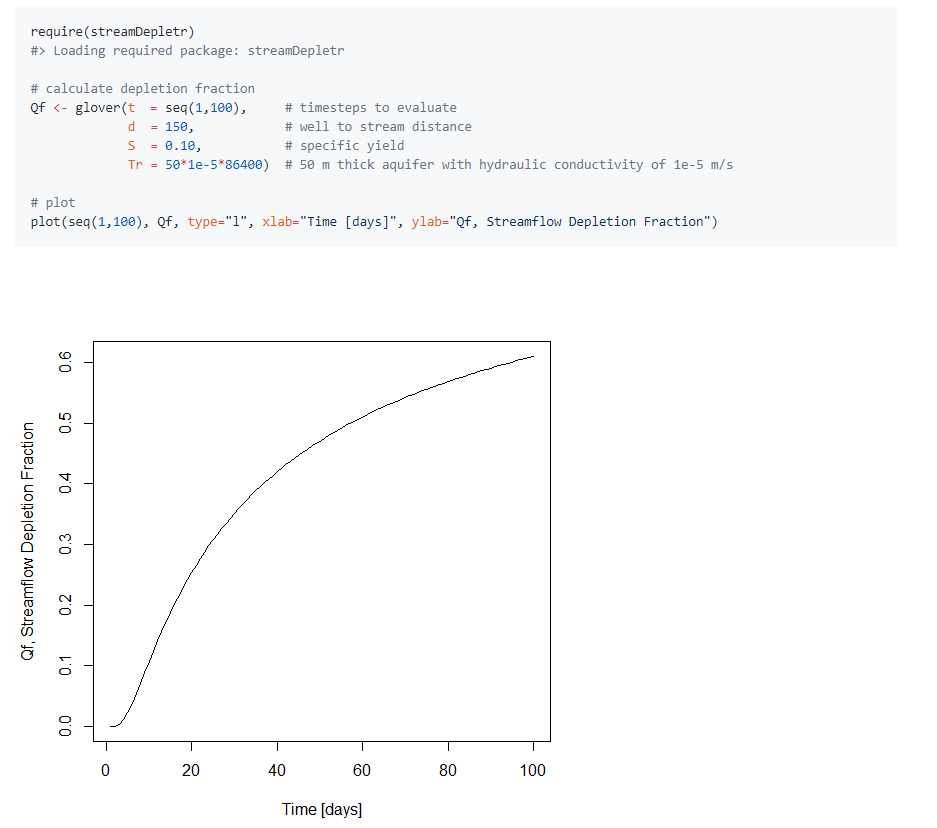
99.R語言包streamDepletr,用於評估由於地下水抽水造成的流量損失。
100.R語言包getopt,旨在與Rscript一起使用來編寫“#!” - shebang指令碼,接受短標記和長標記/選項。 許多使用者更願意使用optparse包,它增加了額外的功能(自動生成的幫助選項和用法,支援預設值,基本位置引數支援)。
101.嗨,我們是微軟的一個名為Bling(超越語言理解)的團隊,我們幫助Bing更聰明。
102.Ignite是一個高階庫,可以幫助在PyTorch中訓練神經網路。ignite可以幫助您在幾行程式碼中編寫緊湊但功能齊全的訓練迴圈,你可以獲得一個訓練迴圈,包括指標,早期停止,模型檢查點和其他沒有樣板的功能。
103.R語言包metasim,模擬meta分析資料的包。
104.DeepWeeds:用於深度學習的多類雜草種類影象資料集,該儲存庫提供了工作的原始碼和公共資料集,“DeepWeeds:用於深度學習的多類雜草種類影象資料集”,由Scientific Reports開放訪問:https://www.nature.com/articles/s41598-018-38343-3。 DeepWeeds資料集由17,509個影象組成,捕獲8種不同的雜草種類,這些種類原生於澳大利亞原位與鄰近的植物群。 在我們的工作中,使用ResNet50深度卷積神經網路將資料集分類為平均準確度為95.7%。以及IEEE接收的論文,用於處理資料的引擎。
Low Power and High Speed Deep FPGA Inference Engines for Weed Classification
105.我收集的一些論文被認為是很好閱讀,這也是我即將閱讀的內容。關於模型壓縮。
Awesome model compression and acceleration
106.用於貝葉斯建模的C ++庫,主要通過馬爾可夫鏈蒙特卡羅,但支援其他一些方法。 BOOM =“貝葉斯面向物件建模”。 它也是計算機崩潰時發出的聲音。
107.機器學習系統研究的精選清單。
Awesome System for Machine Learning
108.R語言包NNLM,這是非負線性模型(NNLM)的包。 它實現了非負線性迴歸和非負矩陣分解(NMF或NNMF)的快速順序座標下降演算法。 它支援均方誤差和Kullback-Leibler散度損失。 還實現了許多其他特徵,包括缺失值插補,領域知識整合,可設計的W和H矩陣以及多種形式的正則化。
109.R語言包rmdTemplates,包含Rmarkdown模板集合的R包。 包括用於撰寫科學論文,稿件評論和其他Rmarkdown文件的模板,支援引文和不同的參考書目風格。 它還包括在HTML檔案中嵌入資料和Rmarkdown原始檔的功能。 以及用metropolis主題製作投影儀(PDF)幻燈片的模板。
110.使用R做線性,廣義和混合/多級模型的介紹。
111.R語言包dbarts,離散貝葉斯加性迴歸樹取樣器。
112.R語言包simr,基於模擬的廣義線性混合模型的功率分析。
113.R語言包textmineR,R中的文字挖掘輔助工具,其語法應該是有經驗的R使用者所熟悉的。 為幾個主題模型提供包裝器,這些主題模型採用類似格式的輸入並提供類似格式的輸出。 具有用於分析和診斷主題模型的附加功能。
114.R語言包glmmplus,glmmplus是一個R包,基於這樣的概念:缺失資料幾乎是任何分析的基本部分,並且允許擬合線性模型和變數選擇的旗艦程式應該包括比彈出行以處理缺失值更好的選項。
115.R語言包geomexperimentsResearch,非官方包,Google開發的地理實驗分析方法的開源實現。
116.R語言包MAB,實現靜平穩和非平穩“多臂抽獎”問題的策略。 這個包中包含各種廣泛使用的策略及其集合。
117.R語言包CausalImpact,使用貝葉斯結構時間序列模型進行因果推斷,該R包實現了一種估計設計干預對時間序列的因果影響的方法。例如,廣告活動產生了多少額外的每日點選次數?當沒有隨機實驗時,回答這樣的問題可能很困難。該方案旨在使用結構貝葉斯時間序列模型來解決這一困難,以估計如果沒有發生干預,干預後響應度量可能如何演變。
118.RAPPOR是一種新穎的隱私技術,可以在保留個人使用者隱私的同時推斷人口統計資料。
2 Paper:
中國的社會經濟發展,包括城市化,正面臨著減少碳排放的關鍵挑戰。本研究分析了中國貨運碳排放的驅動因素和城市化對貨運碳排放的影響。建立空間durbin模型(SDM) - 迴歸對人口,富裕和技術(STIRPAT)模型和地理加權迴歸模型(GWR)-STIRPAT模型的隨機影響,分析中國上述影響的共同特徵和區域差異。 結果表明:(1)中國的貨運碳排放總量已從1988年的373.52萬噸增加到2016年的96.4158百萬噸。公路貨運是貨運領域碳排放量增幅最大的子行業。 (2)城市化水平對公路和航空運輸碳排放產生積極影響,對部分省份的鐵路和水路運輸碳排放產生顯著的負面影響,但對周邊省份產生積極影響。多貨運碳排放存在顯著的地區差異。 (3)貨運的碳排放具有“路徑依賴”的特徵。人口規模和能源強度對貨運碳排放產生重大影響。與水路貨運不同,鐵路,公路,航空貨運和人均GDP的碳排放呈倒U型關係。我們根據調查結果提供政策影響,預計將有助於中國交通運輸行業的碳減排。巨集觀層面上分析了城市化對貨運碳排放的影響,利用恐空間迴歸模型分析了區域差異。交通排放是一個碳排放較難核算的領域,同時涉及到跨界,巨集觀的分析是很必要的。
城市住宅能源消耗和二氧化碳排放量的增加對區域碳減排政策構成了嚴峻挑戰。該研究整合了兩個夜間燈光資料集:DMSP-OLS和Suomi NPP VIIRS夜間燈光資料,以改進估計城市住宅二氧化碳排放量從2000年到2015年,解析度為1公里。然後,基於覆蓋288個地級城市的面板資料,利用空間計量經濟學模型討論了包括社會經濟因素和氣候因素在內的驅動力。結果表明,在估算城市居民二氧化碳排放量時,為北部和南部地區建立的模型分別比整個國家的模型表現更好,這有力地表明氣候因素影響城市居民的行為和二氧化碳排放。時空分析顯示,省會城市排放量快速增長,主要集中在中部地區。國內生產總值和能源利用技術與二氧化碳排放量增加有關,而人均國內生產總值和就業人數則產生負面影響。基於日平均溫度的測量與二氧化碳排放呈顯著負相關。相比之下,夏季每日最高氣溫的平均值與較高的二氧化碳排放量相關。我們的結論是,極端天氣事件和能源效率應該是決策者特別關注的問題。基於DMSP-OLS和NPP VIIRS資料整合分析中國城市居民二氧化碳排放量。並且分析了氣候因素對居民碳排放的影響,結合了空間計量經濟學模型。極端天氣對於碳排放的影響也是一個值得關注的問題。
世界各地的研究已經估計了長期暴露於細小氣載粒子(PM2.5)導致的死亡人數,但有關短期接觸的資訊有限,特別是在中國。此外,大多數現有研究假設短期PM2.5-死亡率關聯是線性的。因此,使用線性暴露 - 響應函式計算中國短期暴露於PM2.5的疾病負擔可能不合適。迫切需要對與中國短期PM2.5暴露相關的疾病負擔進行全面的,基於證據的評估。在這裡,我們探討了中國104個縣的短期PM2.5暴露與全因死亡率之間的非線性關聯;估計由於該國所有縣的短期PM2.5暴露造成的縣特定死亡率負擔,並分析了由於中國短期PM2.5暴露導致的死亡率負擔的空間特徵。彙集的PM2.5-死亡率關聯是非線性的,具有反轉的J形。我們發現死亡率從0到62μg/ m3大致線性增加,風險從62到250μg/ m3降低。我們估計2015年全中國PM2.5短期接觸死亡人數共計169,862人。使用PM2.5死亡率協會的線性暴露 - 反應函式的模型估計有32,186人因PM2.5暴露而死亡,這是5.3倍低於非線性效應模型的估計值。短期PM2.5暴露對中國的死亡負擔貢獻很大,約為慢性影響估計值的七分之一。在考慮中國等發展中國家PM2.5引起的疾病負擔時,將短期PM2.5相關死亡率估算納入其中至關重要且至關重要。傳統的線性效應模型可能低估了短期接觸PM2.5導致的死亡率負擔。分析了PM2.5短期暴露與死亡率的非線性關係,並提出是一個倒J形。是一個比較有意思也很關鍵的研究,以往的人口暴露都是基於線性響應函式的,這個研究將為中國未來空氣質量和人群健康相關的研究提供先驗知識。
中國的十個基本氣溶膠模型來自基於地面遙感測量的太陽 - 天空輻射計觀測網路(SONET)的聚類研究。氣溶膠尺寸分佈分解技術用於產生具有獨立折射率的單獨的精細和粗糙模式尺寸分佈函式。包含18種氣溶膠微物理引數的總共10773條記錄用於產生10個典型的聚類,並驗證聚類魯棒性。十個群集提出五種典型的細顆粒氣溶膠模型,包括城市汙染,二次汙染,混合汙染,汙染的粉煤灰和大陸背景,以及五種粗糙模型,包括夏季粉煤灰,冬季粉煤灰,初級粉塵,運輸粉塵和中國地區的背景塵埃。代表性和共同外觀分析再次揭示了基礎模型基礎上的5種主導氣溶膠模式。這些模型可用於化學模型模擬,衛星遙感,氣候和環境分析。氣溶膠機理性研究,利用氣溶膠資料,聚類分析之後得到十種典型的氣溶膠模型,這些模型可以有效地應用在各種化學模型模擬和衛星遙感反演上。總的來說研究關鍵意義得到氣溶膠的理論分佈型。
亞洲夏季風(ASM)影響著數十億人的生態系統,生物多樣性和糧食安全。近幾十年來,ASM強度(以降水為代表)一直在下降,但儀器測量只能在很短的時間內完成。最近趨勢的啟動和動態尚不清楚。這是我們第一次使用來自ASM中西部邊緣的十個樹木年輪寬度年表的集合來重建ASM變異的細節,回到公元1566年。重建捕獲弱/強ASM事件並且還反映了主要的蝗蟲災難。值得注意的是,我們在448年的重建過程中發現了前所未有的80年ASM強度下降的趨勢,這與溫室氣候變暖的預期相反。我們的耦合氣候模型顯示,北半球人為硫酸鹽氣溶膠排放增加可能是導致ASM減少的主要因素。古氣候結合氣候模型分析亞洲夏季風的變化,並且發現了與溫室氣候變暖相反的結果。
越來越多的“地方”,包括物理和地理特徵以及社會意義,被認為是推動個人和社群健康風險的重要因素。在低收入和中等收入國家(LMIC)的邊緣化人群中尤其如此,其環境也可能更難以使用傳統方法進行研究。在美國國立衛生研究院資助的Mapa de Salud縱向研究中,我們採用了一種新方法來探索兩個墨西哥/美國的女性性工作者(FSWs)的風險環境。邊境城市,蒂華納和CiudadJuárez。在本文中,我們描述了用於捕捉LMIC環境中FSW的HIV風險環境的定量和定性工具組合的開發,實施和可行性。方法是:1)參與式製圖; 2)定量訪談; 3)性工作場地現場觀察; 4)時間 - 地點 - 活動日記; 5)對日常活動空間的深入訪談。我們發現所概述的混合方法既可行,又可供參與者接受。這些方法可以生成地理空間資料,以評估環境對高風險人群中藥物和性風險行為的作用。此外,在資源有限的背景下對邊緣化人口的現有方法進行調整,為公共衛生干預提供了新的機會。關美寶老師團隊的成果,結合參與、定量訪談活動日記以及深入訪談的混合方法,生成HIV風險空間資料。非常有意思的一個研究。
在本文中,我們將對五個專家訪談進行分析,每個訪談來自不同的應用領域。這種分析對於理解分析地理嵌入式流資料的真實場景至關重要。 我們的分析結果表明,在不同的領域進行了類似的高階任務。 為了更好地描述這些任務的目標,我們提出了三個流量目標來分析地理嵌入的流量資料:單流量,總流量和區域流量。關於流向圖或者流資料分析以及視覺化的一個探究,利用專家訪談來分析。該論文發表在泰國曼谷舉辦的IEEE2019年太平洋視覺化會議。
隨著城市化和工業化的加速,大氣顆粒物汙染已成為中國最嚴重的環境問題之一。本研究根據植被結構引數,即水平結構,垂直結構和植被型別,將寶雞市的綠地分為不同的模式。基於環境因素的“矩陣效應”,即位置,時間,風速,選擇了11種不同結構的綠地,用於研究大氣顆粒物(PM)濃度與不同植被結構的綠地之間的關係。溫度,溼度和麵積與綠色空間中PM2.5和PM10的濃度有關。結果表明:(1)位置,時間,風速,溫度和溼度對PM2.5和PM10的濃度有顯著影響。在晴天和微風的天氣條件下,PM2.5和PM10濃度隨風速和溼度的增加而增加,隨溫度的升高而降低。 PM10濃度範圍大於PM2.5濃度範圍。 (2)不到2公頃的綠地對PM2.5和PM10的濃度沒有顯著影響。 (3)PM2.5和PM10的濃度在所有綠色空間和對照組之間沒有顯著差異。不同結構綠地間PM2.5濃度的降低差異不顯著,但PM10濃度的降低存在顯著差異。以上結果為今後有效改善城市空氣質量的城市綠地結構優化提供了理論依據和實踐方法。考察不同結構綠地對於大氣汙染物的影響,為以後的結構優化研究提供科學依據。
我們如何鼓勵人們做出可持續的交通選擇,減少汽車依賴性以及相關的二氧化碳排放和能源消耗?利用智慧手機裝置的廣泛可用性,我們設計了GoEco!,這是一款利用自動移動跟蹤,生態反饋,社交比較和遊戲化元素的應用程式(app),可說服個人改變他們的交通方式。應用程式的功能和內容基於行為變化的跨理論模型,旨在避免過度依賴“一刀切”,簡單的基於點的系統。 GoEco!應用程式是以使用者為中心的方法設計的,並在瑞士進行了為期三個月的實驗,涉及約150名自願使用者。在本文中,我們從現場測試人員的角度介紹了應用程式的功能並對其評估進行了評論。我們通過線上調查問卷和個人訪談收集的見解使我們能夠為類似的說服性應用程式提出建議,並確定未來的未來挑戰。特別是,我們建議為這些應用程式提供多模式旅行計劃元件和功能,喚起對社群的歸屬感,提供支援和幫助關係。非常有意思的一個研究,針對人的心理與行為展開的研究。如何通過手機應用引導使用者做出更可持續的交通選擇。
快速的城市化導致土地利用,生物地球化學迴圈,氣候,水力系統和生物多樣性的變化。政策制定者制定了生態保護措施,以促進可持續發展。然而,傳統的保護規劃主要側重於保護特定的綠色空間,從棲息地網路角度考慮綠色空間之間的連通性有限。利用公民科學資料和佔用模型,我們預測了棲息地的適宜性,建立了棲息地網路,並根據它們對三種焦點水,森林和開放棲息地鳥類棲息地網路的功能連通性的貢獻,確定了關鍵棲息地斑塊。根據棲息地的要求,小型水體和中間森林以及開放式棲息地覆蓋有利於保護水,森林和開放棲息地的鳥類。關於網路分析,我們發現具有高保護優先順序的關鍵棲息地斑塊通常具有相對較大的斑塊大小和/或位於棲息地網路中的關鍵位置(在棲息地網路的中心位置,或接近大的位置)斑塊)。我們建議,在未來的城市規劃中,限制建成區的主要棲息地區域將轉變為保護區或作為農田保留。我們強調焦點物種概念在城市生物多樣性保護中的作用。我們的研究從居住網路的角度為城市規劃者提供保護建議,以保護城市生物多樣性和生態系統健康。利用網路分析,結合人居需求,如何保護生物多樣性,設定樣地。清華大學楊軍老師團隊的成果,事實上生物多樣性本身就是受到城市化影響較大的。
受地面觀測站數量的限制,從遙感資料中反演PM2.5是對常規地面觀測的有效補充,是當前的研究熱點。PM2.5的遙感反演背後的一般原理是首先反演氣溶膠光學厚度(AOD)並通過基於AOD的統計關係計算PM2.5。該方法可能導致誤差傳播,這導致反演模型的不穩定性。在本文中,我們提出了一種PM2.5遙感反演方法,通過整合隨機森林機器學習方法直接建立中解析度成像光譜儀(MODIS)影象與地面觀測PM2.5之間的關係,以避免大氣氣溶膠的反演誤差光學深度和獲得PM2.5反演結果具有更高的精度和空間解析度。該方法首先使用隨機森林訓練和驗證MODIS影象和地面觀測站PM2.5資料;然後,選擇根據確定係數R平方(R2)索引的最佳多模型組。最後,在整個MODIS影象上使用最優多模型組,得到整個區域的PM2.5反演結果。為了嘗試使用機器學習技術反演PM2.5,實驗在廣東省的四個季節中選擇了大量的MODIS影象資料進行驗證,並比較了三個效能指標(R2,RMSE和相關係數(CC)來驗證該演算法的優越性。事實上著就是直接尋找MODIS影響與地面觀測的PM2.5的關係,避免AOD反演過程中誤差的二次傳播。
12.Characterizing preferred motif choices and distance impacts/表徵首選主題選擇和距離影響
人們的日常旅行是結構化的,可以表達為網路。很少有研究探索人們如何組織他們的日常旅行以及哪些行為原則導致特定網路型別的選擇。在本研究中,我們首先從高解析度手機定位資料中為眾多個體重建定位網路和活動網路,並將頻繁的網路定義為主題。結果表明,99.9%的人的旅行可以通過一組有限的基於位置的圖案和基於活動的圖案來表徵。結果進一步揭示了最小努力原則通過量化秩頻特性來控制優選的主題選擇。距離的縮放特性特徵性地影響圖案,並且它們通過節點數和圖案型別的縮放差異與圖案的流行度一致,驗證了圖案選擇中的自適應性;也就是說,雖然個人旅行具有獨特的傾向,但他們總是傾向於選擇滿足其需求的最低消費主題。分析了人的履行行為選擇,基於手機定位資料的一個時空行為研究的分析。深圳大學李清泉老師團隊成果。
以沉陽市6種植物為研究物件,選擇5種降雨量,利用氣溶膠發生器對植物葉片進行PM2.5的動態觀察保留;研究結果探討了降雨過程中植物葉片對PM2.5的保留作用。結果表明,單位葉面積PM2.5的吸附能力可以有效去除不同樹種的降雨量,去除率在0.04~0.23μg·cm -2之間。去除率為24.02-46.15%,寬葉PM2.5容量較容易去除;闊葉樹的去除率(37.69%)高於針葉樹(27.76%)。這與降雨量呈正相關,植物葉片PM2.5去除量是降雨量與單位葉面積PM2.5去除量之間曲線模型的3倍(R²> 0.62)。降雨後第二天每單位葉面積PM2.5吸附量的樹種迅速增加,單位葉面積PM2.5吸附量在降雨後第四天恢復到6.07-43.92%。這是因為植物葉子的PM2.5含量被雨水沖洗,並且在它再次達到飽和容量之前大約是16天。通過雨水清除的PM2.5含量的增加速度和倍數對於闊葉樹而言比針葉樹更大,這與PM2.5吸附的大氣PM2.5濃度和每單位葉面積的不同物種有關。數量,與PM2.5去除能力呈負相關。研究結果有助於揭示大氣顆粒物葉片滯留的機理和過程,為葉片滯留粉塵的定量評價提供科學依據。分析植物葉片與降雨對於PM2.5滯塵效應的實驗研究。可以為植被空間配置提供建議。
土壤侵蝕的形成機制和影響因素識別是當前研究的核心和前沿問題。然而,關於多因素合成的研究仍然相對缺乏。本研究基於RUSLE模型和地理探測器方法,在典型的喀斯特盆地中,對不同地貌型別的土壤侵蝕模擬及其定量歸因分析進行了研究。考慮了土地利用型別,坡度,降雨量,海拔,巖性和植被覆蓋等影響因素。結果表明,在不同的地貌型別中,六種影響因子與土壤侵蝕之間的關聯強度存在顯著差異。土地利用型別和坡度是三岔河流域土壤侵蝕的主導因素,特別是土地利用型別,土壤侵蝕的決定因素(q值)的功率遠高於其他因素。坡度q值隨山區緩坡量的增加而下降,即中高海丘>小浮山>中山浮山。多因素相互作用被證明可以顯著加強土壤侵蝕,特別是土地利用型別與坡度的結合,這可以解釋70%的土壤侵蝕分佈。可以發現,不同坡度的同一土地利用型別的土壤侵蝕(如坡度為5°和25°以上的旱地)或坡度相同的不同土地利用型別(如旱地和森林)斜率為5°),變化很大。這表明禁止陡坡耕作和退耕還林工程是控制喀斯特地區土壤侵蝕的合理措施。根據各影響因子不同層次之間土壤侵蝕差異的統計,風險檢測結果表明,至少在小型山地和中部山區中,有顯著差異的分層組合量佔55%。因此,應研究不同地貌型別土壤侵蝕的空間異質性及其影響因素,以更有效地控制喀斯特土壤流失。土壤侵蝕的定量成因分析,利用了地理探測器,先用RUSLE模型完成土壤侵蝕模擬,接著利用地理探測器分析空間異質性和影響因素。
行動電話位置資料已被廣泛用於通過使用移動性指標來理解人類移動模式。通過連續記錄之間的時間間隔測量的時間取樣間隔(TSI)確定這些資料能夠描述人類活動並影響人類活動指標的值的程度。然而,對TSI如何影響人類活動指標的系統研究仍然很少,並且描述這些關係是許多相關研究的基礎研究問題。本研究使用包含19,370個密集取樣個體軌跡(TSI 小於5分鐘)的行動電話位置資料集,系統地評估TSI對四個典型移動指標的影響,這些指標從不同方面描述人類移動模式,即運動熵,回轉半徑,偏心率和每日出行頻率。我們發現不同的TSI對不同流動性指標的價值有著複雜的影響。具體而言,(1)較粗略的TSI往往低估了四個選定指標的不同程度的價值; (2)使用者對於偏心率和日常行進頻率的低估程度差異很大,但對於旋轉半徑和運動熵具有較高的使用者間一致性。上述發現有助於更好地理解人類流動性研究的差異。分析了時間取樣間隔對於手機定位資料估計人類互動模式精度的影響。事實上手機定位資料本身就有較多的不確定性,除了時間之外還有一些其他因素,考慮這些資料的不確定性,是對這些資料進一步挖掘的重要工作。
16.Recent global cropland water consumption constrained by observations/通過對地觀測資料發現最近全球農田用水受到限制
在當前全球變暖和人口增長加速的情況下,農田灌溉用水已經成為限制人類 - 自然耦合系統可持續性的核心問題。該研究提出了對近期全球農田用水量的新估計,這些估算受到觀測的限制,併為近期趨勢提供了歸因。通過結合觀測,包括提取的農田葉面積指數(LAI)和灌溉閾值資料,該研究提供了對近期全球農田蒸散和蒸騰以及灌溉用水和抽取的改進估計。全球年消費量和灌溉用水量分別估計約為874 km3和1867 km3(2005年)。從2000年到2014年,農田灌溉迅速增加,特別是在缺水地區(即超乾旱,乾旱和半乾旱地區)。氣候變化主要由溫度上升和水分條件下降組成,通常被認為是主要的驅動因素。人為引起的作物冠層覆蓋增加也促成了乾旱和乾旱地區的更多灌溉。該研究還提供了基於蒸騰比(即蒸騰與蒸散的比率)在缺水地區以節水為目標的農田管理的建議。分析了農田灌溉用水的分析。利用對地觀測資料分析了農田用水的情況,全球尺度的研究,結合觀測資料對ET等水文資料分析,提出一些農田管理建議。還是