
Java高並發--緩存
Java高並發--緩存
在下圖中每一個部分都可以使用緩存的技術。
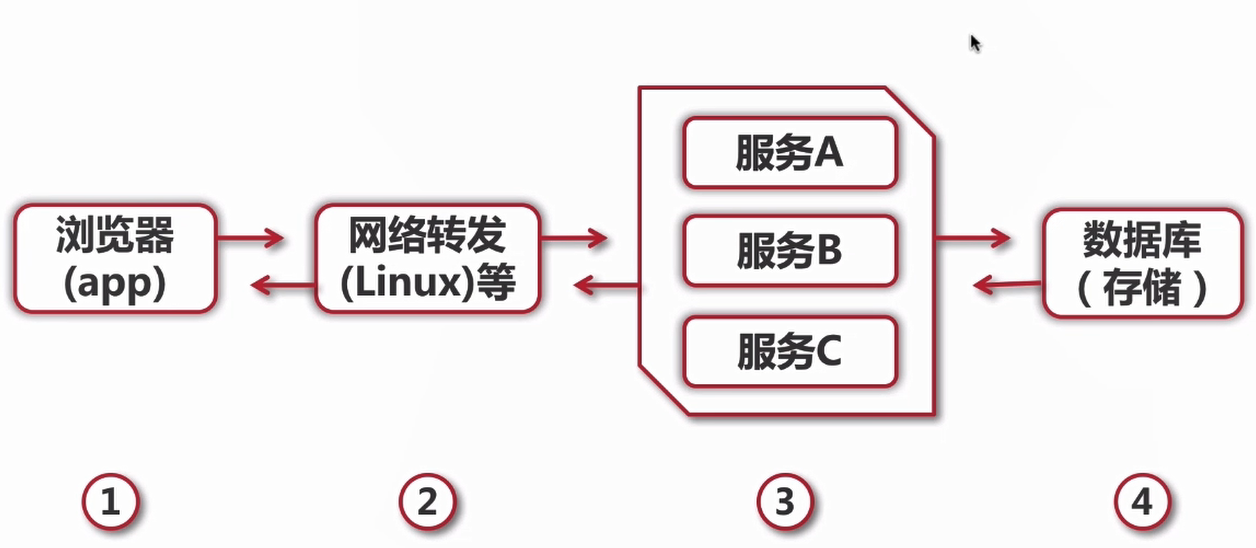
緩存的特征
緩存命中:直接通過緩存獲取到數據
命中率:命中數 / (命中數+ 未命中數)
最大元素(空間):超過最大空間將觸發緩存清空策略
清空策略:FIFO(先進先出)、LFU(最少使用)、LRU(最近最少使用)、過期時間、隨機
緩存的粒度越小,緩存命中率越高,對比緩存一整個集合和集合中的某一個元素,或者一整個對象和對象的其中一個屬性。
緩存適合的業務場景:讀多寫少,實時性要求越低,越適合緩存。因為實時性高,數據經常會表更新修改。
緩存的分類
- 本地緩存:編程實現(成員變量、局部變量、靜態變量)、Guava Cache。與程序耦合性高,各個應用需要維護自己的本地緩存
- 分布式緩存:Memcache、Redis。與程序是隔離的,緩存自身就是一個獨立的應用。多個應用可以共享緩存。
緩存一致性
對數據實時性高的應用,要求數據庫和緩存中的數據一致,這就比較依賴緩存的更新和更新策略了,一般在會在數據更改的時候主動更新緩存中的數據或者移除最近的緩存,這時候就可能出現緩存一致性問題。一般有以下四種情況。
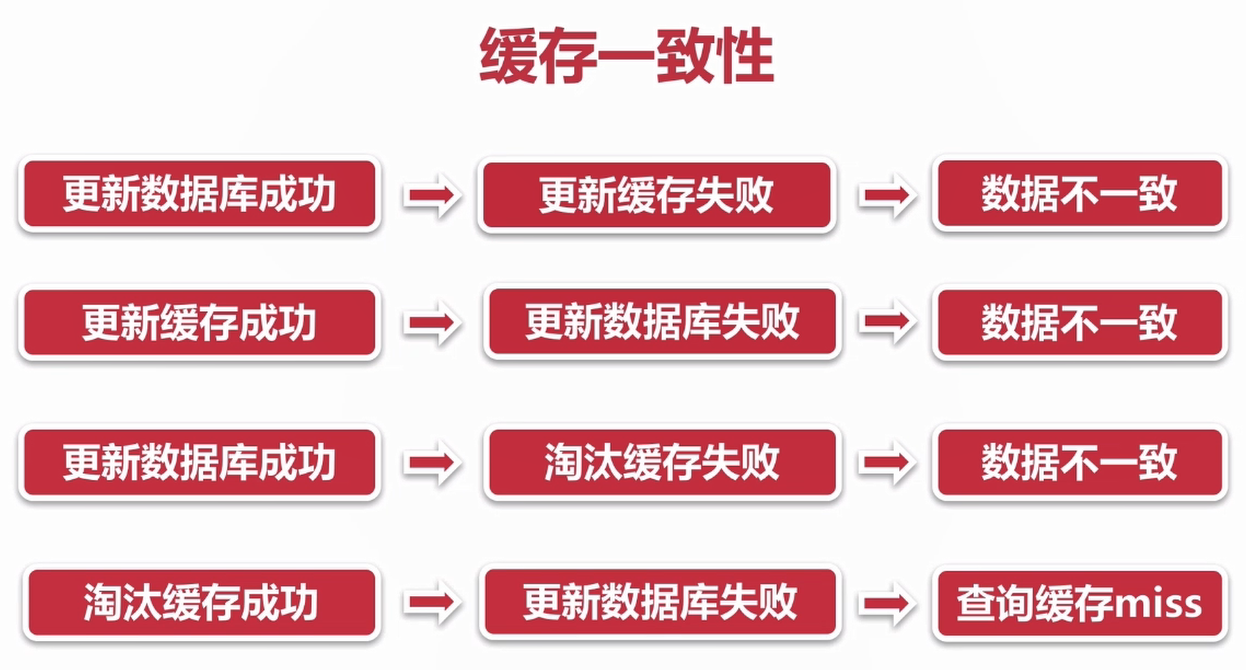
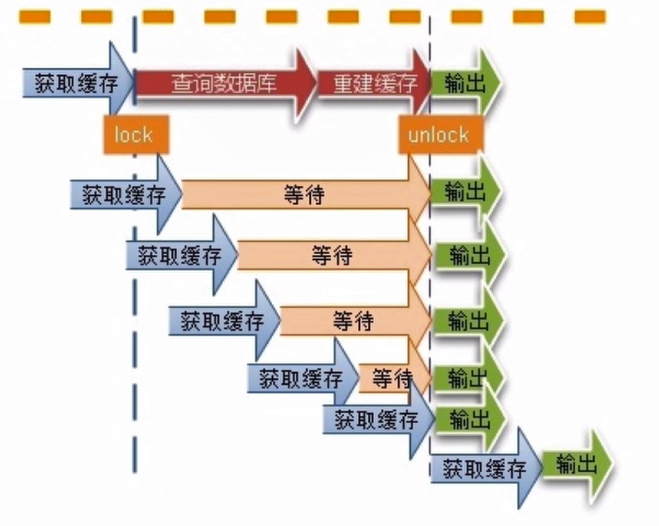
緩存並發問題
緩存未命中時會嘗試從後端數據庫獲取數據,在高並發的場景下可能會給數據庫造成極大的沖擊甚至導致緩存雪崩的現象,此外在某個緩存的key在被更新時,會被大量請求獲取,也可能造成緩存一致性問題。如何解決呢?可以使用類似於鎖的機制。在緩存更新或者過期的情況下,某個請求嘗試獲得鎖,其他的請求必須等待,當從數據庫獲取完畢後再釋放鎖。
緩存穿透
在高並發場景下,對某個key的並發訪問,沒有命中緩存,出於容錯性的考慮會從後端數據庫中獲取數據,導致大量請求對後端數據庫的訪問。當該key對應的數據本身是空的情況下,使得數據庫中進行了大量不必要的查詢操作,從而產生了大量的沖擊和壓力。
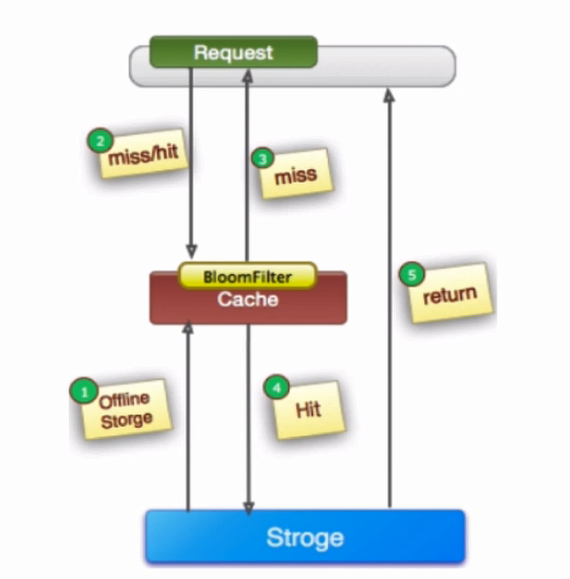
可以有以下幾種策略:
- 對於空對象也進行緩存,這樣避免請求穿透到數據庫了。需要保證緩存數據的時效性。這種實現簡單,比較適合命中不高但可能被頻繁更新的數據。
- 單獨過濾處理,對所有對應數據為空的key進行統一的存放,並在請求前作攔截,避免請求穿透到後端數據庫。這種實現相對復雜,比較適合命中不高且更新不頻繁的數據。
緩存雪崩
在說緩存雪崩時,先看看緩存抖動。緩存抖動比緩存雪崩更輕微的故障,通常是由於緩存結點的故障導致,推薦的做法是通過一致性哈希算法解決。緩存並發、緩存穿透、緩存抖動等都有可能導致緩存雪崩的發生。
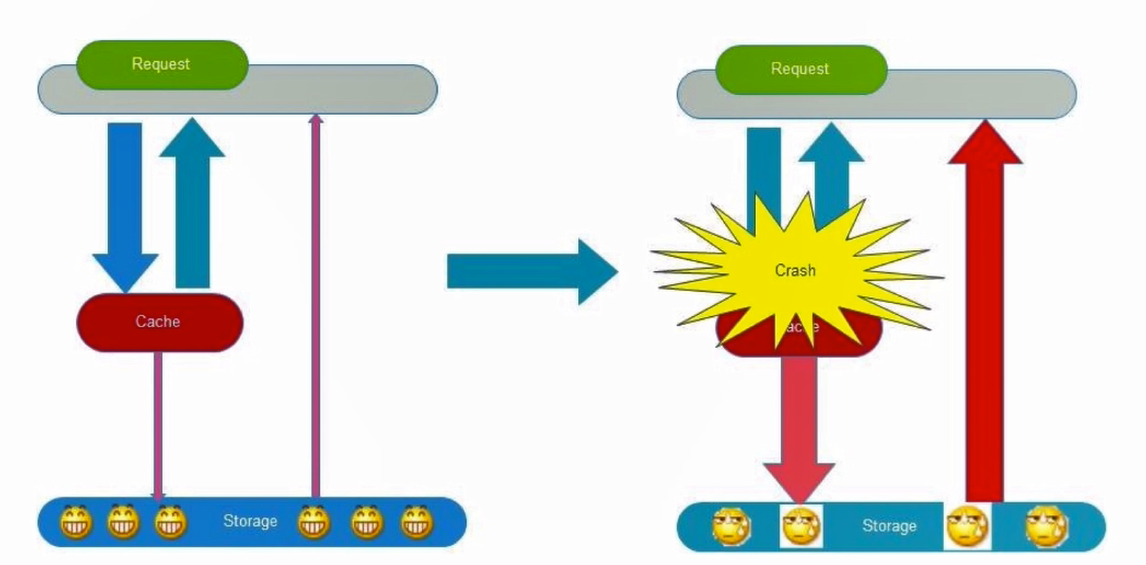
緩存雪崩是由於緩存的原因導致大量請求到達後端數據庫,從而導致數據庫崩潰的災難。
Java高並發--緩存