
程序員筆記|全面解析Oracle等待事件的分類、發現及優化
大家可能有些奇怪,為什麽說等待事件,先談到了指標體系。其實,正是因為指標體系的發展,才導致等待事件的引入。總結一下,Oracle的指標體系,大致經歷了下面三個階段:
- 以命中率為主要參考指標
以各種命中率為主要的優化入口依據,常見的有”library cache hit radio“等。但這種方式弊端很大,一個命中率為99%的系統,不一定就比95%的系統優化的更好。在老的Oracle版本中,往往采用這種方式,如8i、9i等。
- 以等待事件為主要參考指標
以各種等待事件為優化入口依據,常見的有"db file sequential read"等。可以較直觀的了解,在一段時間內,數據庫主要經歷了那些等待。這些"瓶頸",往往就是我們優化的著手點。在10g、11g版本中,廣泛使用。
- 以時間模型為主要參考指標
以各種資源整體消耗為優化入口依據。可以從整體角度了解數據庫在一段時間內的消耗情況。較等待事件的方式,更有概括性。常見的如"DB Time"。Oracle在不斷加強這個方面的工作。
從上面三個階段可見,等待事件的引入,正是為了解決以命中率為指標的諸多弊端。與後面的時間模型相比,等待事件以更加直觀、細粒度的方式觀察Oracle的行為,往往作為優化的重要入口。而時間模型,更側重於整體、系統性的了解數據庫運行狀態。兩者的側重點不同。
二、等待事件分類
讓我們首先從等待事件的分類入手,認識等待事件。從大的分類上來看,等待事件可分為空閑的、非空閑的兩大部分
可以通過下面的方法,觀察系統包含的等待事件數量及大致分類(以下語句在11g環境運行)。

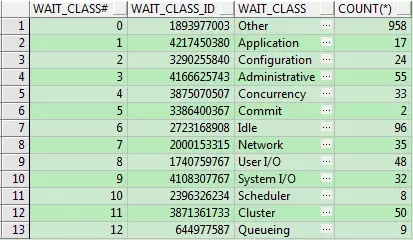
其中WAIT_CLASS為“Idle”的等待事件就是空閑的,其他的都是非空閑的等待事件。
1. 區分 — 空閑與非空閑等待事件
空閑等待事件,是指Oracle正等待某種工作,比如用sqlplus登錄之後,但沒有進一步發出任何命令,此時該session就處於SQL*Net message from/to client等待事件狀態,等待用戶發出命令,任何的在診斷和優化數據庫的時候,一般不用過多註意這部分事件。
非空閑等待事件,專門針對Oracle的活動,指數據庫任務或應用運行過程中發生的等待,這些等待事件是調整數據庫的時候應該關註與研究的。
2. 等待事件分類說明
- 管理類-Administrative
此類等待事件是由於DBA的管理命令引起的,這些命令要求用戶處於等待狀態(比如,重建索引) 。
- 應用程序類-Application
此類等待事件是由於用戶應用程序的代碼引起的(比如,鎖等待) 。
- 群集類-Cluster
此類等待事件和真正應用群集RAC的資源有關(比如,gc cr block busy等待事件) 。
- 提交確認類-Commit
此類等待事件只包含一種等待事件——在執行了一個commit命令後,等待一個重做日誌寫確認(也就是log file sync) 。
- 並發類-Concurrency
此類等待事件是由內部數據庫資源引起的(比如閂鎖) 。
- 配置類-Configuration
此類等待事件是由數據庫或實例的不當配置造成的(比如,重做日誌文件尺寸太小,共享池的大小等) 。
- 空閑類-Idle
此類等待事件意味著會話不活躍,等待工作(比如,sql * net messages from client) 。
- 網絡類-Network
和網絡環境相關的一些等待事件(比如sql* net more data to dblink) 。
- 其它類-Other
此類等待事件通常比較少見(比如wait for EMON to spawn) 。
- 調度類-Scheduler
此類等待事件和資源管理相關(比如resmgr: become active‘) 。
- 系統I/O類-System I/O
此類等待事件通過是由後臺進程的I/O操作引起的(比如DBWR等待-db file paralle write) 。
- 用戶I/O類-User I/O
此類等待事件通常是由用戶I/O操作引起的(比如db file sequential read) 。
三、理解等待事件
每一個等待事件,都表明數據庫的一種活動狀態。從上面的查詢可見,系統內置了很多等待事件,可以通過數據字典V$EVENT_NAME去了解每個等待事件。下面通過一個最為常見的等待事件進行說明。

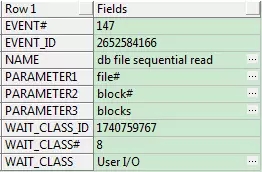
這個等待事件“db file sequential read”,直譯過來為“數據文件順序讀取”,是屬於“User I/O”類的等待事件。它通常是與單個數據塊相關的讀取操作,大多數情況下讀取一個索引塊或者通過索引讀取一個數據塊,會記錄這個等待。該事件說明在單個數據塊上大量等待,該值過高通常是由於表間連接順序很糟糕,或者使用了非選擇性索引。通過將這種等待與statspack報表中已知其它問題聯系起來(如效率不高的sql),通過檢查確保索引掃描是必須的,並確保多表連接的連接順序來調整,DB_CACHE_SIZE可以決定該事件出現的頻率。
該等待事件包含了三個參數,分別為:
-
file#: 代表oracle要讀取的文件的絕對文件號
-
block#: 從這個文件中開始讀取的起始數據塊塊號
- blocks: 讀取的block數量。通常是1,表示單個block讀取。
通過上面這些參數,關聯數據字典可以確定發生等待事件的對象(即找到了熱點對象)。然後針對不同的情況,有針對性的進行解決。
對等待事件的了解越多,可更加深入理解數據庫運行機制,進而提高整體優化能力。後面,我會介紹一下常見的等待事件。
四、觀察等待事件
系統內置了一些視圖,通過這些視圖可以了解整體(系統級)、局部(會話級)的等待事件發生情況及各類別事件的分類統計。下面針對一些主要的視圖,說明一下。
1、v$event_name
系統支持的等待事件,可以查看等待事件所屬類別、參數的含義等信息。
2、v$system_wait_class
displays the instance-wide time totals for each registered wait class.
等待事件類別的統計信息(系統級)。通過這一視圖,可從全局角度了解系統那類操作等待較多。
3、v$system_event
等待事件的統計信息(系統級)。展開來說,是提供了自實例啟動後各個等待事件的概括。常用於獲取系統等待信息的歷史影象。而通過兩個snapshot獲取等待項增量,則可以確定這段時間內系統的等待項。
主要的字段包括:
- TOTAL_WAITS
自數據庫啟動到現在,此等待事件總等待次數。
- TIME_WAITED
此等待事件的總等待時間(單位:百分之一秒)。這個數據表示從數據庫啟動以來這個等待事件在所有會話(包括已經結束和正保持連接狀態的會話)總的等待事件之和。
- AVERAGE_WAIT
此等待事件的平均等待用時(單位:百分之一秒)。
time_waited/total_waits
- TOTAL_TIMEOUTS
此等待事件總等待超時次數。
SQL – 按等待時長查看頂級事件

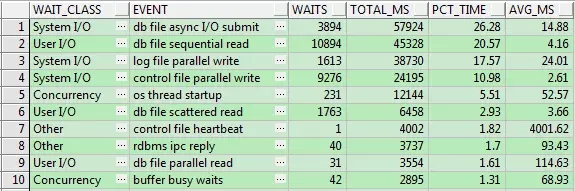
4、v$session_event
和v$system_event相類似,記錄的是會話在其生命周期中各個等待事件的累計值。跟前者相比,增加了session_id信息。這些信息也會被同時累積到v$system_event中。需要註意的是,當一個會話重新建立時,統計信息將被設置為0。
5、v$session_wait、v$session
活動會話正在等待的資源或事件信息。在10g將這個視圖和v$session視圖進行了合並。這是一個尋找性能瓶頸的關鍵視圖。它提供了任何情況下session在數據庫中當前正在等待什麽。當系統存在性能問題時,本視圖可以做為一個起點指明探尋問題的方向。
需要註意的是,當等待不再存在時,會話先前出現的那些等待的歷史也將消失,從而使得事後診斷非常困難。V$SESSION_EVENT提供了累積的但不是非常詳細的數據。可以通過歷史視圖v$session_wait_history獲得歷史信息。
主要的字段包括:
- EVENT
會話當前等待的事件,或者最後一次等待事件。
- WAIT_TIME
會話等待事件的時間(單位:百分之一秒)。
值>0: 最後一次等待時間(單位:10ms),當前未在等待狀態。
值=0: session正在等待當前的事件。
值=-1: 最後一次等待時間小於1個統計單位,當前未在等待狀態。
值=-2: 時間統計狀態未置為可用,當前未在等待狀態。
- STATE
等待狀態(提供對wait_time和second_in_wait字段的解釋)
1) waiting:
SESSION正等待這個事件。
2) waited unknown time:
由於設置了timed_statistics值為false,導致不能得到時間信息。表示發生了等待,但時間很短。
3)wait short time:
表示發生了等待,但由於時間非常短不超過一個時間單位,所以沒有記錄。
4)waited knnow time:
如果session等待然後得到了所需資源,那麽將從waiting進入本狀態。
- WAIT_TIME/SECOND_IN_WAIT
Wait_time和Second_in_wait字段值與state相關。
1)state=waiting
wait_time無用,second_in_wait值是實際的等待時間(單位:秒)。
2)state=wait unknow time
wait_time和second_in_wait都無用。
3)state=wait short time
wait_time和second_in_wait都無用。
4)state=waiting known time
wait_time值就是實際等待時間(單位:秒),second_in_wait值無用。
6、v$session_wait_history
記錄會話最近n次等待事件,即v$session_wait的歷史記錄。默認是記錄10次,可進行修改。
7、v$event_histogram
這個視圖記錄了等待事件的柱狀圖分布,從而可以對一個等待事件具體分布有進一步了解。在v$session_event或v$system_event視圖記錄的是累積信息以及關於等待的平均值,無法得知個別等待消耗的時間。
下面將會話等待事件與各視圖之間的關系,總結整理如下:
-
一個會話一次只發生一個等待事件。如果看到了其他的等待事件,那僅僅表示在下一個時間片上發生了等待。在某個時刻只存在一個等待。
-
v$session_wait中的wait_time和second_in_wait字段以秒為單位,而v$session_event中的time_waited和average_wait字段是以百分之一秒為單位。
-
v$session_wait的等待事件結束後,v$session_event的統計信息將會發生改變。
-
v$session_wait的統計信息意義不大,因為信息是實時變化的。
- 當v$session_wait裏面的等待事件結束時,v$session_wait中的seconds_in_wait字段值被復制到v$session_event中time_waited字段,而v$session_event視圖的average_time字段同時也被修改。
五、常見等待事件
Oracle的等待事件非常多,不同的版本也有些差異。下面對一些常見的等待事件進行說明。希望對大家的日常工作能帶來幫助。
1、buffer busy waits
發生原因:
當一個會話將數據塊從磁盤讀到內存中時,它需要到內存中找到空閑的內存空間來存放這些數據塊,當內存中沒有空閑的空間時,就會產生這個等待。除此之外,還有一種情況就是會話在做一致性讀時,需要構造數據塊在某個時刻的前映像。此時需要申請內存塊來存放這些新構造的數據塊,如果內存中無法找到這樣的內存塊,也會發生這個等待事件。
參數含義:
- File#
等待訪問數據塊所在的文件id號
- Blocks
等待訪問的數據塊號
- Id
10g之前,這個值表示等待事件原因;10g之後則表示等待事件的類別。
優化方向:根據產生此等待事件的類別不同,優化方向也不太一樣。
- 數據塊
一般優化方向是優化SQL,減少邏輯讀、物理讀;或者是減少單塊的存儲數據規模。
- 數據段頭
一般優化方向是增加FREELISTS和FREELIST GROUPS。確保FCTFREE和PCTUSED之間的間隙不是太小,從而可以最小化FREELIST的塊循環。
- 撤銷塊
一般優化方向為應用程序,錯峰使用數據對象。
- 撤銷段頭
如果是數據庫系統管理UNDO段,一般不需要幹預。如果是自行管理的,可以減少每個回滾段的事務個數。
2、buffer latch
發生原因:
內存中數據塊的存放位置是記錄在一個Hash列表當中的。當一個會話需要訪問某個數據塊時,它首先要搜索這個Hash列表,從列表中獲得數據塊的地址,然後通過這個地址去訪問需要的數據塊,這個列表oracle會使用一個latch來保護它的完整性。當一個會話需要訪問這個列表時,需要獲取一個latch,只有這樣,才能保證這個列表在這個會話的瀏覽當中不會發生改變。如果列表過長,導致會話搜索這個列表花費的時間太長,使其他的會話處於等待狀態。同樣的數據塊被頻繁訪問,就是我們通常說的熱塊問題。
參數含義:
- latch addr
會話申請的latch在SGA中的虛擬地址。
- chain#
buffer chains hash列表中的索引值。當這個參數的值等於0xffffff時,說明當前的會話正在等待一個LRU latch。
優化方向:
可以考慮的優化方向有使用多個buffer pool的方式來創建更多的buffer chains或者使用參數db_block_lru_latches來增加latch的數量,以便於更多的會話可以獲得latch,這兩種方法可以同時使用。
3、db file sequential read
發生原因:
通常是與單個數據塊相關的讀取操作,大多數情況下讀取一個索引塊或者通過索引讀取一個數據塊,會記錄這個等待。可能顯示表的連接順序不佳,或者不加選擇地進行索引。對於大量事務處理、調整良好的系統,這一數值大多是很正常的,但在某些情況下,它可能暗示著系統中存在問題。應當將這一等待統計量與性能報告中的已知問題(如效率較低的SQL)聯系起來。檢查索引掃描,以保證每個掃描都是必要的,並檢查多表連接的連接順序。
DB_CACHE_SIZE 也是這些等待出現頻率的決定因素。有問題的散列區域(Hash-area)連接應當出現在PGA 內存中,但它們也會消耗大量內存,從而在順序讀取時導致大量等待。它們也可能以直接路徑讀/寫等待的形式出現。
參數含義:
- file#
代表oracle要讀取的文件的絕對文件號
- block#
從這個文件中開始讀取的起始數據塊塊號
- blocks
讀取的block數量。通常是1,表示單個block讀取。
優化方向:
這個等待事件,不一定代表一定有問題。如果能確定是有問題,可以按照下面優化思路。
-
修改應用,避免出現大量IO的sql,或者減少其頻率。
-
增加data buffer,提高命中率。
- 采用更好的磁盤子系統,減少單個IO的響應時間,防止物理瓶頸的出現。
4、db file scattered read
發生原因:
這是一個用戶操作引起的等待事件,當用戶發出每次I/O需要讀取多個數據塊這樣的SQL操作時,會產生這個等待事件,最常見的兩種情況全表掃描和索引快速掃描。這個名稱中的scattered(發散)可能會導致很多人認為它是以scattered的方式來讀取數據塊的,其實恰恰相反,當發生這種等待事件時,SQL的操作都是順序地讀取數據塊的,比如FTS或IFFS方式。其實這裏scattered指的是讀取的數據塊在內存中的存放方式。它們被讀取到內存中後,是以分散的方式存放在內存中,而不是連續的。
參數含義:
- file#
代表oracle要讀取的文件的絕對文件號。
- block#
從這個文件中開始讀取的起始數據塊塊號。
- blocks
讀取的block數量。
優化方向:
這種情況通常顯示與全表掃描相關的等待。當全表掃描被限制在內存時,它們很少會進入連續的緩沖區內,而是分散於整個緩沖存儲器中。如果這個數目很大,就表明該表找不到索引,或者只能找到有限的索引。盡管在特定條件下執行全表掃描可能比索引掃描更有效,但如果出現這種等待時,最好檢查一下這些全表掃描是否必要。
5、direct path read
發生原因:
這個等待事件發生在會話將數據塊直接讀取到PGA當中而不是SGA中的情況,這些被讀取的數據通常是這個會話私有的數據,所以不需要放到SGA作為共享數據,因為這樣做沒有意義。這些數據通常是來自於臨時段上的數據,比如一個會話中SQL的排序數據,並行執行過程中間產生的數據,以及Hash join、Merge join產生的排序數據,因為這些數據只對當前會話的SQL操作有意義,所以不需要放到SGA當中。當發生direct path read等待事件時,意味著磁盤上有大量的臨時數據產生,比如排序、並行執行等操作,或者意味著PGA中空閑空間不足。
在11g中,全表掃描可能使用direct path read方式,繞過buffer cache,這樣的全表掃描就是物理讀了。在10g中,都是通過gc buffer來讀的,所以不存在direct path read的問題。
參數含義:
- file#
文件號
- first block#
讀取的起始塊號
- block count
以first block為起點,連續讀取的物理塊數
優化方向:
有了這個等待事件,需要區分幾種情況。一個方向是增大排序區等手段,一個方向是減少讀取IO量或判斷是否通過緩沖區讀的方式更加高效。
6、direct path write
發生原因:
發生在oracle直接從PGA寫數據到數據文件或臨時文件,這個操作可以繞過SGA。在磁盤排序中最為常見。對於這種情況應該找到操作最為頻繁的數據文件(如果是排序,很有可能是臨時文件),分散負載。
參數含義:
- file#
文件號
- first block#
讀取的起始塊號
- block count
以first block為起點,連續寫入的物理塊數
優化方向:減少IO寫入規模。
7、library cache lock
發生原因:
這個等待事件發生在不同用戶在共享池中由於並發操作同一個數據庫對象導致的資源爭用的時候。比如當一個用戶正在對一個表做DDL操作時,其他的用戶如果要訪問這張表,就會發生library cache lock等待事件,它要一直等到DDL操作完畢後,才能繼續操作。
參數含義:
- Handle address
被加載的對象的地址。
- Lock address
鎖的地址。
- Mode
被加載對象的數據片段。
- Namespace
被加載對象在v$db_object_cache視圖中的namespace的名稱。
優化方向:優化方向是查看鎖定對象,減少爭用。
8、library cache pin
發生原因:
這個等待事件和library cache lock一樣是發生在共享池中並發操作引起的等待事件。通常來講,如果oracle要對一些pl/sql或視圖這樣的對象做重新編譯,需要將這些對象pin到共享池中。如果此時這個對象被其他的對象持有,就會產生一個library cache pin的等待。
參數含義:
- Handle address
被加載的對象的地址。
- Lock address
鎖的地址。
- Mode
被加載對象的數據片段。
- Namespace
被加載對象在v$db_object_cache視圖中的namespace的名稱。
優化方向:優化方向是查看鎖定對象,減少爭用。
9、log file sync
發生原因:
這是一個用戶會話行為導致的等待事件。當一個會話發出一個commit命令時,LGWR進程會將這個事務產生的redo log從log buffer裏寫到磁盤上,以保證用戶提交的信息被安全地記錄到數據庫中。會話發出commit指令後,需要等待LGWR將這個事務產生的redo成功寫入到磁盤之後,才可以繼續進行後續的操作,這個等待事件就叫做log file sync。當系統中出現大量的log file sync等待事件時,應該檢查數據庫中是否有用戶在做頻繁的提交操作。這種等待事件通常發生在OLTP系統上。OLTP系統中存在很多小的事務,如果這些事務頻繁被提交,可能引起大量log file sync的等待事件。
優化方向:
-
提高LGWR性能,盡量使用快速磁盤
-
使用批量提交
- 適當使用nologging/unrecoverable等選項
10、SQL*Net message from client
發生原因:
表明前臺服務器進程等待客戶進行響應。這個等待事件是由於等待用戶進程的響應所引起的,它並不表明數據庫就存在什麽不正常。如果網絡出現故障時,這種等待時間就會經常發生。
11、SQL* Net message to client
發生原因:
這個等待事件發生在服務器端向客戶端發送消息的時候。當服務器端向客戶端發送消息產生等待時,可能的原因是用戶端太繁忙,無法及時接收服務器端送來的消息,也可能是網絡問題導致消息無法從服務器端發送給客戶端。
作者:韓鋒
來源:宜信技術學院
程序員筆記|全面解析Oracle等待事件的分類、發現及優化