
Hadoop基礎學習(一)分析、編寫並執行WordCount詞頻統計程序
https://blog.csdn.net/jiq408694711/article/details/34181439
前面已經在我的Ubuntu單機上面搭建好了偽分布模式的HBase環境,當中包含了Hadoop的執行環境。
詳見我的這篇博文:http://blog.csdn.net/jiyiqinlovexx/article/details/29208703
我的目的主要是學習HBase,下一步打算學習的是將HBase作為Hadoop作業的輸入和輸出。
可是好像曾經在南大上學時學習的Hadoop都忘記得幾乎相同了,所以找到曾經上課做的幾個實驗:wordCount,PageRank以及InversedIndex。
發現曾經寫的實驗報告還是蠻具體的。非常easy看懂。恰好曾經做實驗用的也是hadoop0.20的版本號,所以依照我曾經寫的實驗手冊直接操作,熟悉一下Hadoop了。
以下是我曾經寫的WordCOunt的實驗報告:
一、實驗要求:
實驗內容與要求
1. 在Eclipse環境下編寫WordCount程序,統計全部除Stop-Word(如a, an, of, in, on, the, this, that,…)外全部出現次數k次以上的單詞計數。最後的結果依照詞頻從高到低排序輸出
3. 可自行建立一個Stop-Word列表文件。當中包含部分停詞就可以,不須要列出全部停詞;參數k作為輸入參數動態指定(如k=10)
4. 實驗結果提交:要求書寫一個實驗報告,當中包含:
實驗設計說明。包含主要設計思路、算法設計、程序和各個類的設計說明
程序執行和實驗結果說明和分析
性能、擴展性等方面存在的不足和可能的改進之處
源程序 。執行程序,停詞列表文件
執行結果文件
二、實驗報告:
Wordcount詞頻統計實驗
2012年4月1日星期日
19:04
1設計思路
Map:
(1)停詞存儲
由於停詞比較少。所以選擇將他們全部存儲到內存中,停詞不能有反復,還須要高速訪問。所以選擇
(2)map
對於map傳進來的每一行文本。首先用正在表達式將英文標點符號全部題換成空格,然後在循環分析每個單詞,假設這個單詞不包含在停詞集合中。則將其key設為單詞本身,值設置為1。並發射出去。
Reduce:
在reduce中對每個key,將其全部value累加起來。
假設value不小於某個詞頻。則將其output出去。
?
2遇到的問題
(1)hadoop API問題
(2)在hadoop的map中讀取hdfs文件內容
(3)怎樣按詞頻從高究竟輸出;
解決1:
參考非常多資料。找到正確使用的API,總之感覺hadoop不同版本號之間API非常混亂。
在API方面有兩個點花費我非常多時間。一是map和reduce的初始化函數setup。二是向map和reduce傳遞參數直接通過configuration來進行,有點相似於JSP中的session。
解決2:
開始我在map之外定義一個全局變量,開始的時候將停詞文件路徑復制給這個全局變量。可是在map裏面無法讀取這個文件的內容。不知道怎麽回事。
然後我們在網上查了一下,發現有一個分布式緩存文件的類DistributedCache。
主要先是獲取停詞文件的路徑,將其增加到cache中去,DistributedCache.addCacheFile(newPath(args[++i]).toUri(), conf);
然後在map中用DistributedCache.getLocalCacheFiles(context.getConfiguration());讀取該文件路徑,這樣就能夠讀取停詞文件的內容了。
解決3:
詞頻要在reduce完畢之後才幹計算出來。也就是說盡管map之後將鍵值對分發到reduce之前會依照鍵值進行一個sort的過程,可是我們也無法借助將key
value掉換的方法一次進行。
我們小組一起討論,想到了在第一次mapreduce統計完詞頻之後再進行一次mapreduce來依照詞頻對全部鍵值對排序。統計結果(中間結果)存放到暫時文件夾中。
在第二次mapreduce的過程中:
(1)InverseMapper:
在網上查了一下,hadoop本身就有一個將鍵值對顛倒順序的了一個mapper。名字叫做InverseMapper,在交換了鍵值之後。另一個問題。
(2)setSortComparatorClass:
hadoop中默認對IntWritable類型的key是以升序排列的,我們是要依照降序,所以重寫sort過程中進行key值比較所參考的比較類。使用setSortComparatorClass方法設置比較類。
(3)setNumReduceTasks(1):
至於reduce部分我們無須指定不論什麽reduce。由於不須要做不論什麽操作。僅僅須要指定將全部鍵值對發送到一個reduce就可以。
?
3執行過程
首先利用scp命令將停詞文件以及wordcount的可執行jar傳輸到集群的mater01節點上面去。然後使用ssh命令登錄到該節點:
?
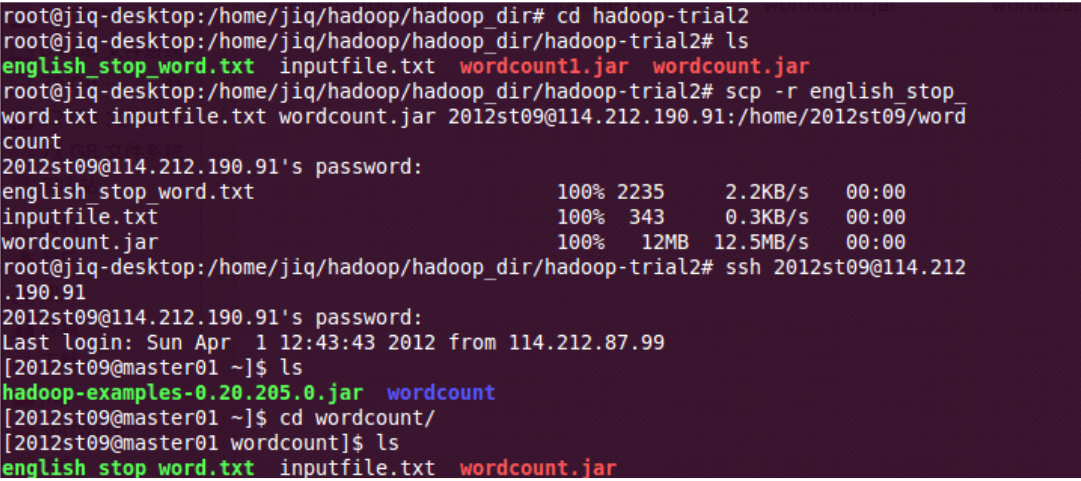
然後在hdfs上面我們小組的文件夾下創建一個wordcount文件夾。以及子文件夾input。
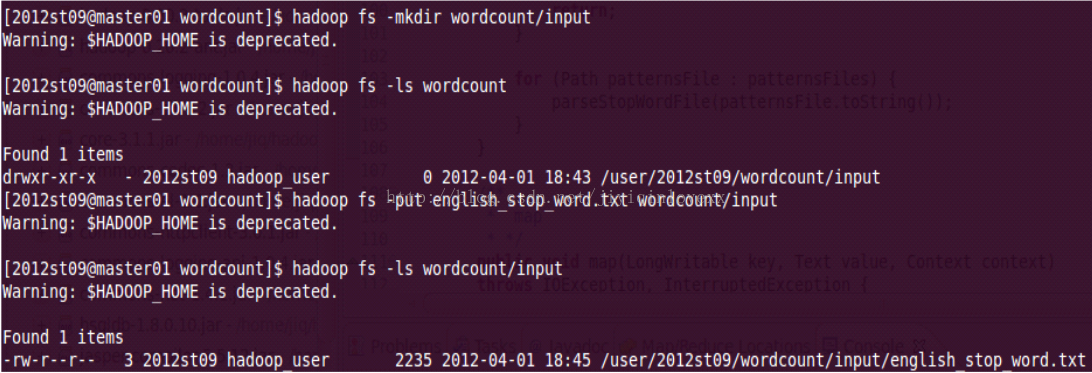
然後使用hadoopfs -put命令將停詞文件復制到該文件夾下:
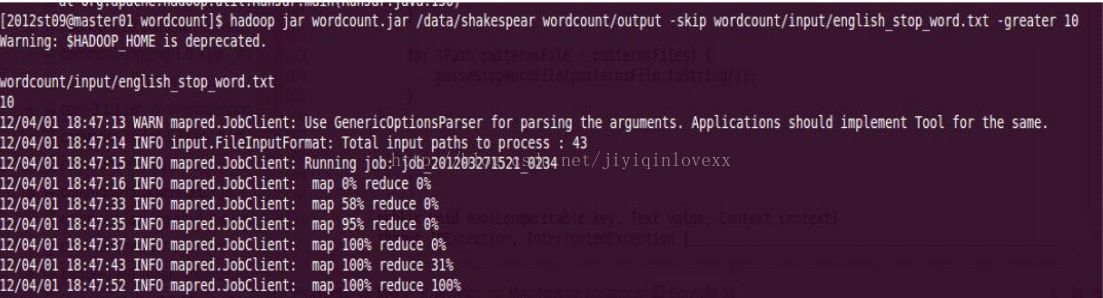
然後以節點上本來就有的/data/shakespear文件夾以下的數據作為輸入,將我們小組的/wordcount/output(不存在)作為輸入。執行參數為-skip指定聽此文件路徑,-greater指定要統計的最低詞頻的單詞。來執行wordcount:
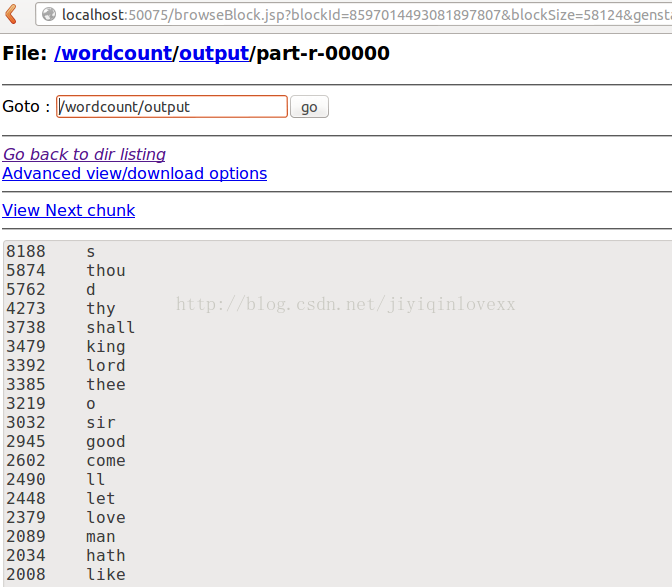
在wordcount/output文件夾以下生成結果文件part-r-00000。打開之後發現結果和預期全然一致。詞頻從高到低,最低詞頻為10,而且在統計之前已經將標點符號去掉。
能夠用hadoop fs -get /wordcount/output/part-r-00000 .命令下載到當前文件夾。
也能夠打開瀏覽器:http://localhost:50070/dfshealth.jsp。選擇Browse the filesystem來直接查看HDFS上面文件的內容。
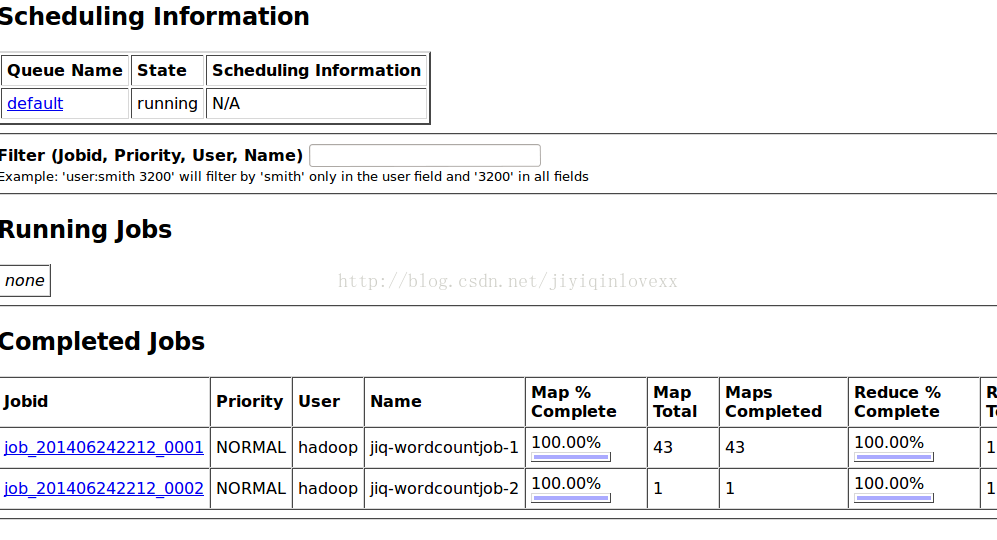
在瀏覽器中打開:http://localhost:50030/jobtracker.jsp,查看工作執行狀態以及結果:
?
4源程序,停詞文件,可執行jar文件均參見本文件夾裏。
=====================================================================================================
註意,我由於如今是在本機上面執行Hadoop作業,而不是像曾經那樣在遠端master機器上面跑。所以有些地方不一樣。
比方利用scp將wordcount.jar傳到master機器上,以及用ssh登陸這些都不須要。
可是停詞文本集合還是要上傳到HDFS。還有之前實驗莎士比亞文集的數據是老師已經放在HDFS上了,所以不須要我們上傳,這些要自己將莎士比亞文集的數據上傳到HDFS。命令是:
hadoop fs -put /shakespeare /data/shakespare
三、源代碼:
說實話。看著曾經的圖片。發現跑起來蠻快的,可是如今單機真心慢。。
。
停詞文本文件和莎士比亞文集數據有時間上傳到百度雲盤,這裏先把代碼貼出來供大家參考。
/**
* WordCount
* [email protected] - 季義欽
* 統計輸入文件各個單詞出現頻率
* 統計的時候對於“停詞”(從文本文件讀入)將不參與統計
* 最後按統計的詞頻從高究竟輸出
*
* 特別主import某個類的時候。確定你是要用哪個包所屬的該類
*
* */
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.map.InverseMapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
/**
* Map: 將輸入的文本數據轉換為<word-1>的鍵值對
* */
public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
String regex = "[.,\"!--;:?‘\\]]"; //remove all punctuation
Text word = new Text();
final static IntWritable one = new IntWritable(1);
HashSet<String> stopWordSet = new HashSet<String>();
/**
* 將停詞從文件讀到hashSet中
* */
private void parseStopWordFile(String path){
try {
String word = null;
BufferedReader reader = new BufferedReader(new FileReader(path));
while((word = reader.readLine()) != null){
stopWordSet.add(word);
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 完畢map初始化工作
* 主要是讀取停詞文件
* */
public void setup(Context context) {
Path[] patternsFiles = new Path[0];
try {
patternsFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration());
} catch (IOException e) {
e.printStackTrace();
}
if(patternsFiles == null){
System.out.println("have no stopfile\n");
return;
}
//read stop-words into HashSet
for (Path patternsFile : patternsFiles) {
parseStopWordFile(patternsFile.toString());
}
}
/**
* map
* */
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String s = null;
String line = value.toString().toLowerCase();
line = line.replaceAll(regex, " "); //remove all punctuation
//split all words of line
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
s = tokenizer.nextToken();
if(!stopWordSet.contains(s)){
word.set(s);
context.write(word, one);
}
}
}
}
/**
* Reduce: add all word-counts for a key
* */
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
int min_num = 0;
/**
* minimum showing words
* */
public void setup(Context context) {
min_num = Integer.parseInt(context.getConfiguration().get("min_num"));
System.out.println(min_num);
}
/**
* reduce
* */
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
if(sum < min_num) return;
context.write(key, new IntWritable(sum));
}
}
/**
* IntWritable comparator
* */
private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
/**
* main: run two job
* */
public static void main(String[] args){
boolean exit = false;
String skipfile = null; //stop-file path
int min_num = 0;
String tempDir = "wordcount-temp-" + Integer.toString(new Random().nextInt(Integer.MAX_VALUE));
Configuration conf = new Configuration();
//獲取停詞文件的路徑。並放到DistributedCache中
for(int i=0;i<args.length;i++)
{
if("-skip".equals(args[i]))
{
DistributedCache.addCacheFile(new Path(args[++i]).toUri(), conf);
System.out.println(args[i]);
}
}
//獲取要展示的最小詞頻
for(int i=0;i<args.length;i++)
{
if("-greater".equals(args[i])){
min_num = Integer.parseInt(args[++i]);
System.out.println(args[i]);
}
}
//將最小詞頻值放到Configuration中共享
conf.set("min_num", String.valueOf(min_num)); //set global parameter
try{
/**
* run first-round to count
* */
Job job = new Job(conf, "jiq-wordcountjob-1");
job.setJarByClass(WordCount.class);
//set format of input-output
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
//set class of output‘s key-value of MAP
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//set mapper and reducer
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
//set path of input-output
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(tempDir));
if(job.waitForCompletion(true)){
/**
* run two-round to sort
* */
//Configuration conf2 = new Configuration();
Job job2 = new Job(conf, "jiq-wordcountjob-2");
job2.setJarByClass(WordCount.class);
//set format of input-output
job2.setInputFormatClass(SequenceFileInputFormat.class);
job2.setOutputFormatClass(TextOutputFormat.class);
//set class of output‘s key-value
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
//set mapper and reducer
//InverseMapper作用是實現map()之後的數據對的key和value交換
//將Reducer的個數限定為1, 終於輸出的結果文件就是一個
/**
* 註意,這裏將reduce的數目設置為1個。有非常大的文章。
* 由於hadoop無法進行鍵的全局排序,僅僅能做一個reduce內部
* 的本地排序。 所以我們要想有一個依照鍵的全局的排序。
* 最直接的方法就是設置reduce僅僅有一個。
*/
job2.setMapperClass(InverseMapper.class);
job2.setNumReduceTasks(1); //only one reducer
//set path of input-output
FileInputFormat.addInputPath(job2, new Path(tempDir));
FileOutputFormat.setOutputPath(job2, new Path(args[1]));
/**
* Hadoop 默認對 IntWritable 按升序排序,而我們須要的是按降序排列。
* 因此我們實現了一個 IntWritableDecreasingComparator 類,
* 並指定使用這個自己定義的 Comparator 類對輸出結果中的 key (詞頻)進行排序
* */
job2.setSortComparatorClass(IntWritableDecreasingComparator.class);
exit = job2.waitForCompletion(true);
}
}catch(Exception e){
e.printStackTrace();
}finally{
try {
//delete tempt dir
FileSystem.get(conf).deleteOnExit(new Path(tempDir));
if(exit) System.exit(1);
System.exit(0);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
若有什麽疑問和不吝賜教。歡迎交流。聯系郵箱: [email protected]? 季義欽
作為興趣點,眼下本人正在研究HBase和Hadoop
Hadoop基礎學習(一)分析、編寫並執行WordCount詞頻統計程序