
java中利用hanlp比較兩個文字相似度的步驟
使用 HanLP - 漢語言處理包 來處理,他能處理很多事情,如分詞、呼叫分詞器、命名實體識別、人名識別、地名識別、詞性識別、篇章理解、關鍵詞提取、簡繁拼音轉換、拼音轉換、根據輸入智慧推薦、自定義分詞器

使用很簡單,只要引入hanlp.jar包,便可處理(新版本的hanlp安裝包可以去github下載安裝),下面是某位大神的操作截圖:
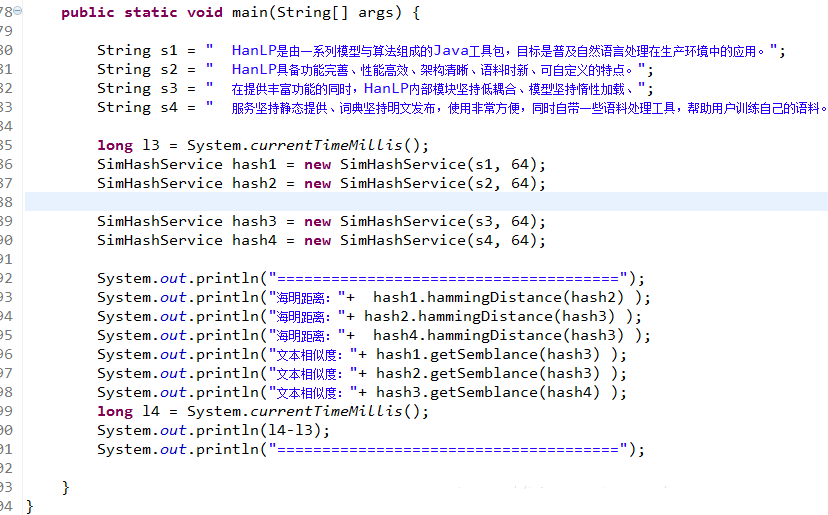
相關推薦
java中利用hanlp比較兩個文字相似度的步驟
使用 HanLP - 漢語言處理包 來處理,他能處理很多事情,如分詞、呼叫分詞器、命名實體識別、人名識別、地名識別、詞性識別、篇章
java中list排序和兩個string的大小比較
此文章簡單記錄一波: list排序方法一Comparator形式: List<String> keyList = new ArrayList<>(); keyList.add("User_Tel"); keyList.add("SystemId"); keyList.
Java中方法重寫的兩個面試題
col class 返回 load 重寫 this strong gpo 不同 1:方法重寫和方法重載的區別?方法重載能改變返回值類型嗎? 方法重寫: 在子類中,出現和父類中一模一樣的方法聲明的現象。(包含方法名、參數列表和返回值類型都一樣) 方法重載
在Java中,如何把兩個String[]合併為一個 與 list 合併有異曲同工之妙
在Java中,如何把兩個String[]合併為一個? 看起來是一個很簡單的問題。但是如何才能把程式碼寫得高效簡潔,卻還是值得思考的。這裡介紹四種方法,請參考選用。 一、apache-commons 這是最簡單的辦法。在apache-commons中,有一個ArrayUtils.addAll
java中double型別顯示兩個小數,比如12.00
本在載自:http://blog.csdn.net/chaozhidan/article/details/8161862 Double型別的資料如何保留兩位小數? 各位大蝦,現有Double型別的資料,如何轉換為保留兩位小數的數,返回值的型別仍然是Double型別的,而不
java中按順序執行兩個執行緒的方法
比如有執行緒A和B,在A執行完成後B再開始執行 線上程A run方法最後啟動執行緒B - - 共享一個volatile boolean型別的標識變數,B一直檢查該變數的值,而A則在執行完成後改變A的
Java中產生隨機數的兩個方法
方法一、Math類有個random方法可以實現隨機數的生成。Math.random()返回的是:返回帶正號的 double 值,該值大於等於 0.0 且小於 1.0。在此基礎上我們修改下就能得到一定範圍的隨機數: (int)(Math.random()*10)返回0到9的隨
opencv java小應用:比較兩個圖片的相似度
package com.company; import org.opencv.core.*; import org.opencv.imgcodecs.Imgcodecs; import org.opencv.imgproc.Imgproc; import org.opencv.objdetect.Casc
如何比較兩個文字的相似度 .
目標 嘗試了一下把PageRank演算法結合了文字相似度計算。直覺上是想把一個list裡,和大家都比較靠攏的文字可能最後的PageRank值會比較大。因為如果最後計算的PageRank值大,說明有比較多的文字和他的相似度值比較高,或者有更多的文字向他靠攏。這樣是不是就可以得到一些相對核心的文字,或者相對代表
DOS命令比較兩個文字檔案txt的內容差異
將需要比較的文字檔案放置在同一個資料夾下。 如把a.txt、b.txt、c.txt放在資料夾/home/q/compare下。 1、開啟windows,輸入cmd,開啟DOS視窗。進入檔案目錄/home/q/compare下。 2、如果比較a.txt和b.txt兩個檔案。輸
檔案輸入輸出 c++ 比較兩個文字內容
先看一個小程式: #include <fstream> #include <iostream> using namespace std; int main(){ ofstream op("text1.txt"); o
java中如何高效判斷兩個容器是否有相同元素(時間複雜度為O(1))
很多時候我們需要知道兩個容器是否存在相同的元素,這裡以電商網站中的優惠活動為例。比如我們想知道一個商品是否參與了滿件折扣活動(幾件幾折),已知一個商品可能會參與多種優惠活動,比如滿減活動(滿多少減多少)、臨期降價等優惠活動。我們知道每一種優惠活動都可以建立一張優
JAVA比較兩張圖相似度
利用直方圖原理比較2張圖片相似度 package com.uiwho.com; import javax.imageio.*; import java.awt.image.*; import java.awt.*;//Color import java.io.*; publi
python實現機器學習中的各種距離計算及文字相似度演算法
在自然語言處理以及機器學習的分類或者聚類中會涉及到很多距離的使用,各種距離的概念以及適用範圍請自行百度或者參考各種距離 import numpy as np import math # 依賴包numpy、python-Levenshtein、scipy
計算兩個字串相似度的演算法
該方法是使用的Levenshtein演算法的一個實現。 簡單介紹下Levenshtein Distance(LD):LD 可能衡量兩字串的相似性。它們的距離就是一個字串轉換成那一個字串過程中的新增、刪除、修改數值。 舉例: 如果str1="test",st
java中比較兩個double型別值的大小
非整型數,運算由於精度問題,可能會有誤差,建議使用BigDecimal型別,具體 BigDecimal的詳細說明參考jdk開發幫助文件。 import java.math.BigDecimal; public class DoubleCompare { public String co
java方法中的傳參機制以及利用反射交換兩個引數
Java方法的值傳遞機制可以訪問這篇部落格:https://www.cnblogs.com/lixiaolun/p/4311863.html, 今天我要寫的是如何利用反射來交換兩個變數的值。 private static void swap(Integer x, Integer y) {
Java:比較兩個物件中全部屬性值是否相等
Java:比較兩個物件中全部屬性值是否相等 例如下述Java類: import java.io.Serializable; import java.util.List; public class Bean_Topology implements Serial
Java中比較兩個字串是否相等的問題
Java中,關於比較兩個字串是否相等的問題,經常會出現。下面將分析使用 ==(注意:Java中 = 是賦值運算子,== 是比較是否相等) 和 equals()方法 來比較兩個字串相等的區別: 簡單一句話,==比較的是兩個字串的地址是否為相等(同一個地址),equals()方
java中比較兩個double型別的資料大小
double a = 0.001; double b = 0.0011; BigDecimal data1 = new BigDecimal(a); BigDecimal data2 = new BigDecimal(b); data1.compareTo(data2)非整型數,運算由於精度問題,可能會有