
大資料技術之Hadoop
阿新 • • 發佈:2019-05-07
大資料產生背景
主要解決海量資料的儲存和海量資料的分析計算問題。大資料特點
1.大量
2.高速
3.多樣
4.低價值密度大資料應用場景
1.物流倉儲:大資料分析系統助力商家精細化運營,提升銷量,節約成本。
2.零售:分析使用者消費習慣,為使用者購買商品提供方便,從而提升商品銷量。3.旅遊:深度結合大資料能力與旅遊行業需求,共建旅遊產業智慧管理,智慧服務和智慧營銷。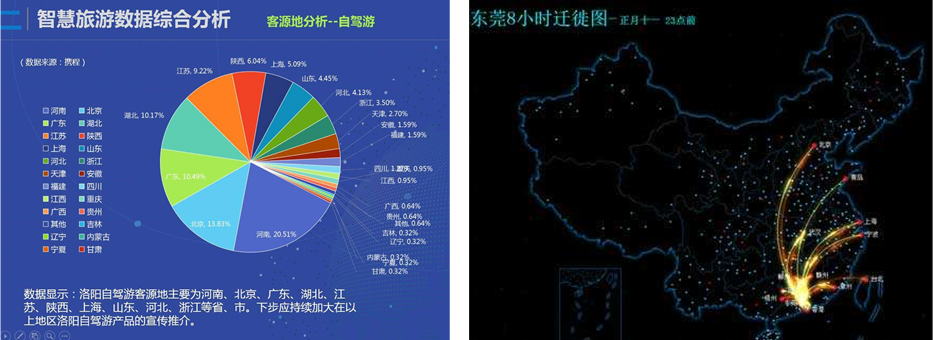
4.商品廣告推薦:給使用者推薦可能喜歡的產品。5.保險:海量資料探勘與風險預測,助力保險行業精準營銷,提升精細化定價能力。 6.金融:多維度體現使用者特徵,幫助金融機構推薦優質客戶,防範欺詐風險。 7.房產:大資料全面助力房地產行業,打造精準機制與營銷,選出更合適的地,建設更適合的樓,賣給更合適的人。
8.人工智慧:
大資料發展前景
1.國家實施大資料戰略
2.十九大提出:推動網際網路,大資料,人工智慧和實體經濟深度融合
3.大資料人才缺口大
4.北大,清華,北郵等高校申請開設大資料課程
5.大資料屬於高新技術,大牛少,升職競爭小
6.大資料一線開發大牛百萬年薪,還在持續上漲大資料組織結構

Hadoop的優勢
1.高可靠性:Hadoop底層維護多個數據副本,即使Hadoop某個計算元素或儲存出現故障,也不會導致資料的丟失。 2.高擴充套件性:在叢集間分配任務資料,可方便擴充套件數以千計的節點。 3.高效性:在MapReduce的思想下,Hadoop是並行工作的,以加快任務處理速度。 4.高容錯性:能夠自動將任務重新分配。
Hadoop組成
Hadoop1.x和Hadoop2.x區別

在Hadoop1.x時代,Hadoop中的MapReduce同時處理業務邏輯運算和資源排程,耦合性比較大;
在Hadoop2.x時代,增加了Yarn,Yarn只負責資源排程,MapReduce只負責運算。HDFS架構概述
NameNode:儲存檔案的目錄
DataNode:儲存資料
Secondary NameNode:監控HDFS狀態的輔助後臺程式,並生成快照檔案。YARN架構概述
1.ResourceManager: (1)處理客戶端請求 (2)監控NodeManager (3)資源的分配與排程
2.NodeManager:
(1)管理單個節點上的資源
(2)處理來自ResourceManager的命令
(3)處理ApplicationMaster的命令3.ApplicationMaster:
(1)負責資料的切分
(2)為應用程式申請資源,並分配給內部的任務
(3)任務的監控與容錯4.Container:
(1)Container是Yarn中資源的抽象,封裝某個節點上的多維度資源,比如CPU,記憶體,磁碟,網路。MapReducer架構概述
計算過程分為兩個階段
1.Map階段:並行處理資料
2.Reducer階段:對Map結果進行彙總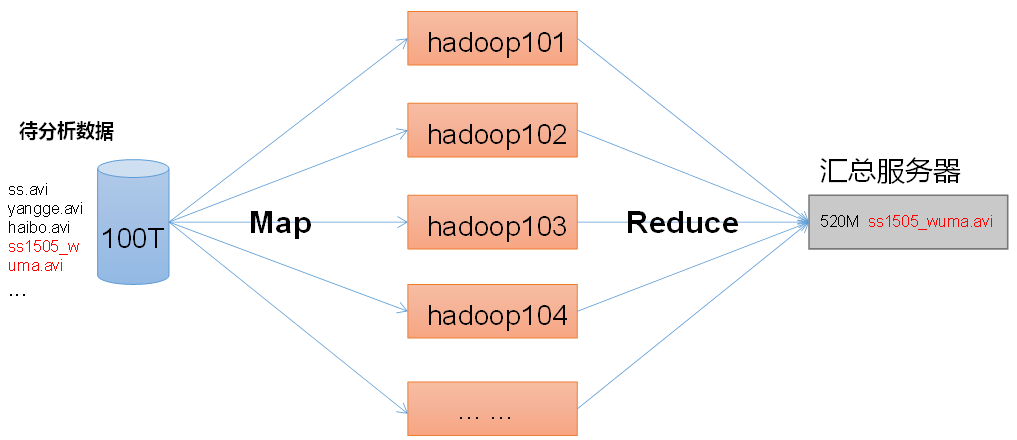
大資料技術生態體系
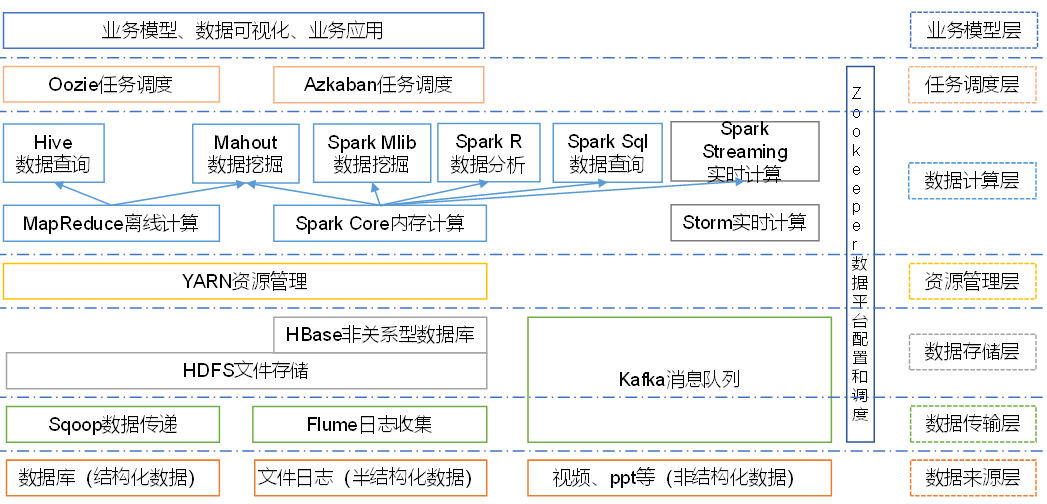
。