
網路應用(1):抓包獲取APP的重要資訊 | charles
小白:何為抓包?
小程:就是截獲網路上收發的資料包。
小白:網路上那麼多資料包,怎麼知道哪些是有用的?
小程:只截獲目標app的資料包就縮小了範圍,但即便是縮小了範圍,也需要進一步分析與排查。
小白:在垃圾堆裡找壞人的行動時間與地點嗎?這是使徒行者2的橋段啊,你有沒有看過?
"抓包看看唄",這樣的話聽過不少了吧,不管怎麼表達,“抓包”,本質都是分析網路互動時的資料包,以取得想要的資訊。
我們有可能會遇到這樣的場景:“對方這個App是怎麼實現的?它傳送的網路請求有沒有帶上時間限制?”、“獲取這個資源的網路地址是什麼,要不要帶token?我能夠模擬傳送嗎?” ,等等,而在研究某個APP時,分析網路資料包,往往就是第一個手段。
本文解決一個問題:通過抓包分析出重要資訊。
抓包的工具有很多,適合在不同的平臺上使用。這裡只介紹charles的使用。
小白:都有什麼樣的抓包工具呢?
小程:比如wireshark、tcpdump、tcpflow、charles、fiddler、sniffer等等。
小白:為什麼只介紹charles,難道其它的不好用嗎?
小白:不是其它的不好用,是我一次只講一個東西!
小白:你......
Charles,是擷取網路資料包的工具。小程這裡演示的是mac系統下的charleas使用。
官網:http://www.charlesproxy.com
(1)破解charles
用破解的charles.jar,覆蓋到程式包內Contents/Java目錄即可(比如4.0.1版本)。
(2)使用charles
charles執行後,就可以看到截獲到的資料包。
charles的檢視分“按結構”跟“按順序(時間先後)”,按順序時可以篩選。
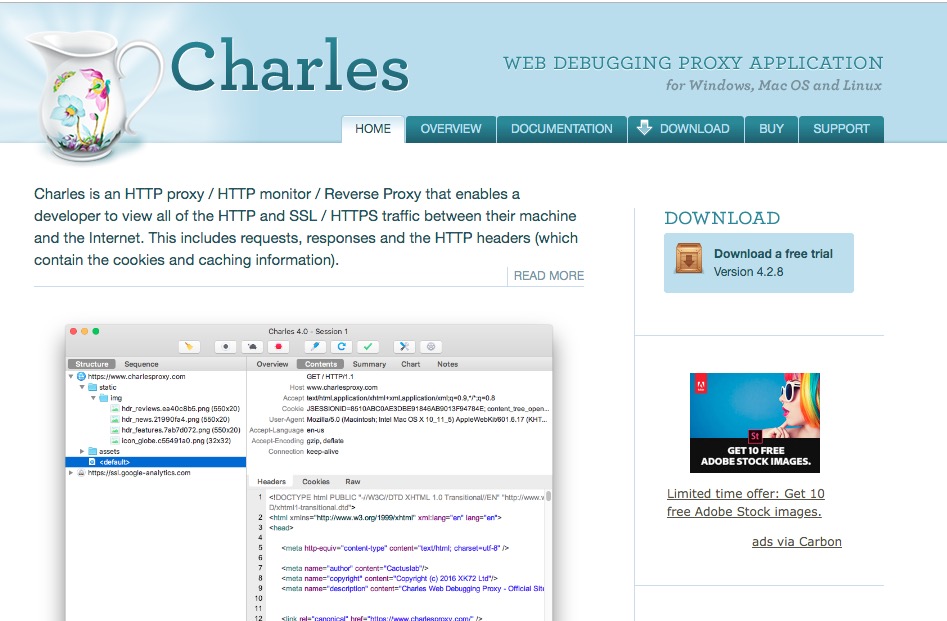
兩個檢視都可以選擇特定的url,再選擇focus,這樣就重點觀察這個url的相關請求與響應,不會跳來跳去。
mac上,抓https包,需要安裝ssl證書:
help->ssl proxying ->install charles root cer..,
同時要在keychain中資訊這個證書(簡介->信任->ssl設定為始終信任)。對於https包,確定url後,要右擊選擇enable ssl proxying,才可以做到解密https包。
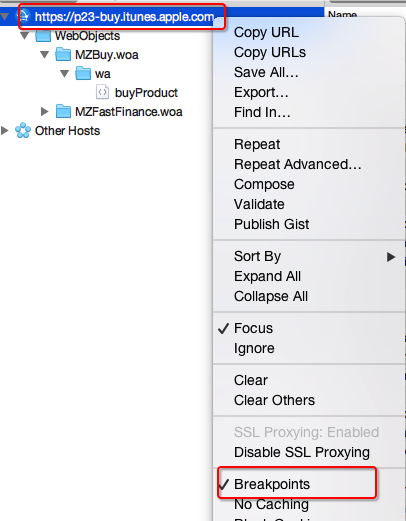
可以右鍵選擇breakpoints,這時會監控這個url的相關行為並下斷點(可以修改傳送請求等),在傳送請求時、收到回覆時、正在接收response body時,都會觸發斷點。觸發斷點後,可以執行“取消(即讓其繼續執行)”、“中止”、“執行”等操作,比如可以修改請求的值後再執行“execute”。
(3)演示:獲取appstore的app的歷史版本
iphone上使用的一些app,新版本還不如舊版本好使。
雖然appstore會把很舊的版本的下載連結給隱藏掉,但存貨還是在的。
如果你的itunes不支援appstore了,那你應該安裝itunes12.6.3或itunes12.6.5版本,再使用下面的辦法,因為這兩個版本還能使用appstore,如果都不能下載APP了,那這個演示還怎麼進行呢。
如何通過itunes拿到某個app的所有歷史版本的資訊,並下載到歷史版本呢?
操作如下:
開啟charles,再開啟itunes並搜尋到目標app,再下載這個app,會觀察到
https://p23-buy.itunes.apple.com 或 https://buy.itunes.apple.com
是目標url,focus這個url。
對這個url選擇enable ssl proxying,退出charles。
啟動charles,刪除掉itunes上已下載的目標aap,重新整理並重新下載。
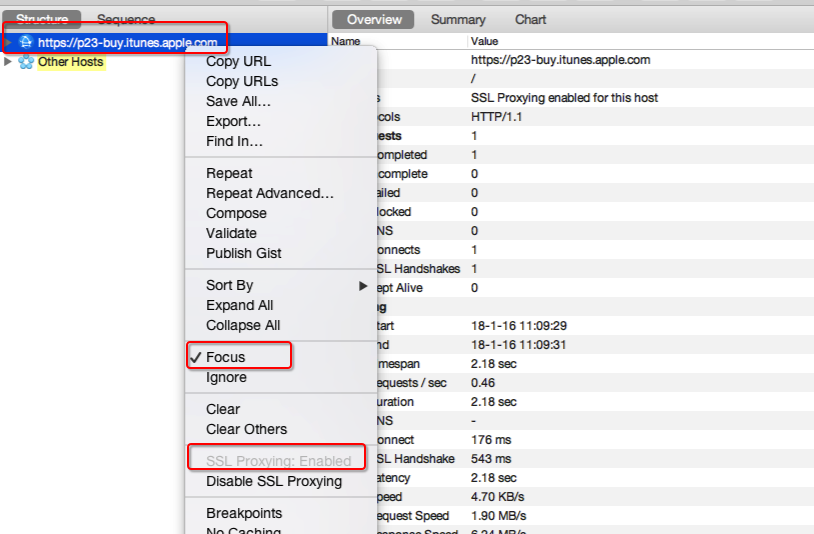
這時,在目標url下面的buyProduct頁面的contents的response部分,
會顯示一個array,是一堆id串,
這個就是不同版本的下載id(用xml text來檢視,可拷貝)。
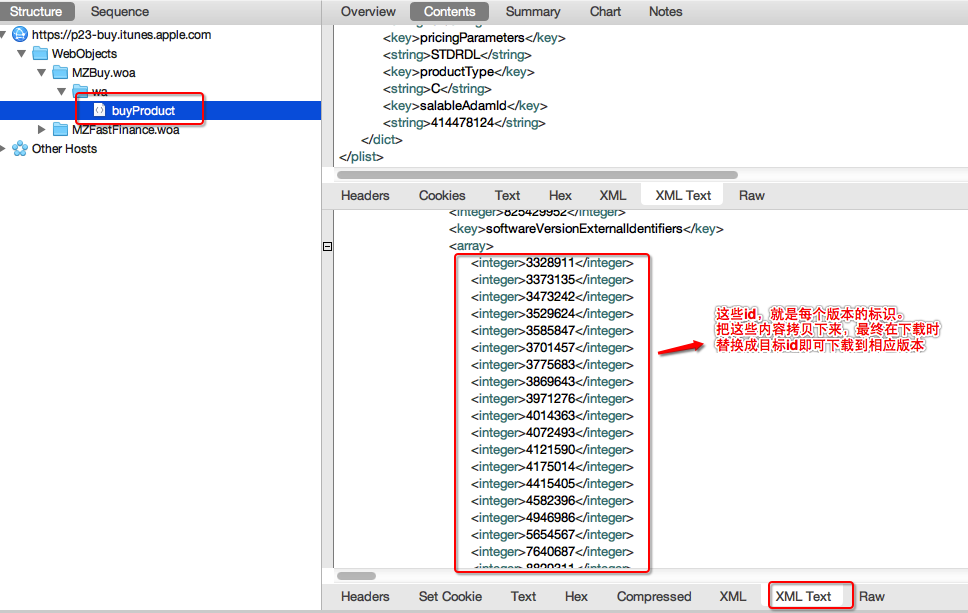
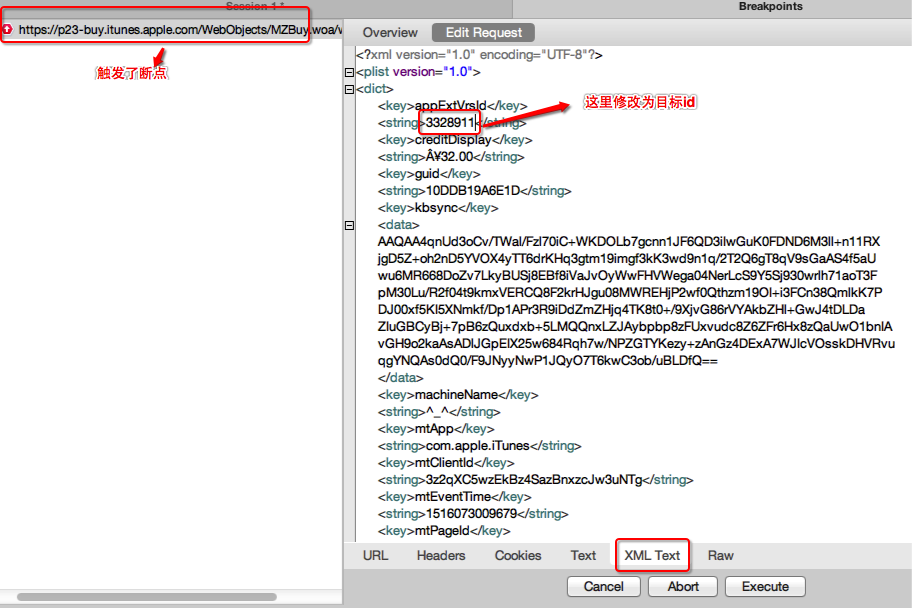
再次刪除已下載的app,並對目標url加上breakpoints,再次下載app。
在傳送request時會觸發斷點,選擇edit request頁面並選擇
xml text檢視模式,把下載id替換成目標下載id,
之後不斷點選execute或取消掉斷點再執行。
這時,itunes會下載到目標版本的app,之後可以找到對應的ipa,並同步到手機。以“微信”為例,大概的步驟是這樣的:
(a)下載微信時,在charles上focus目標url,並激活ssl:
(b)刪除已下載的微信,啟動charles後,重新下載微信,留意目標url下面的內容:
(c)刪除已下載的微信,對目標url加上breakpoints,再次下載,修改請求,再execute:
(d)下載到最舊版本的微信:

(4)演示:抓取手機qq音樂歌手詳情的資訊
這裡演示的是手機上的APP的抓包。操作如下:
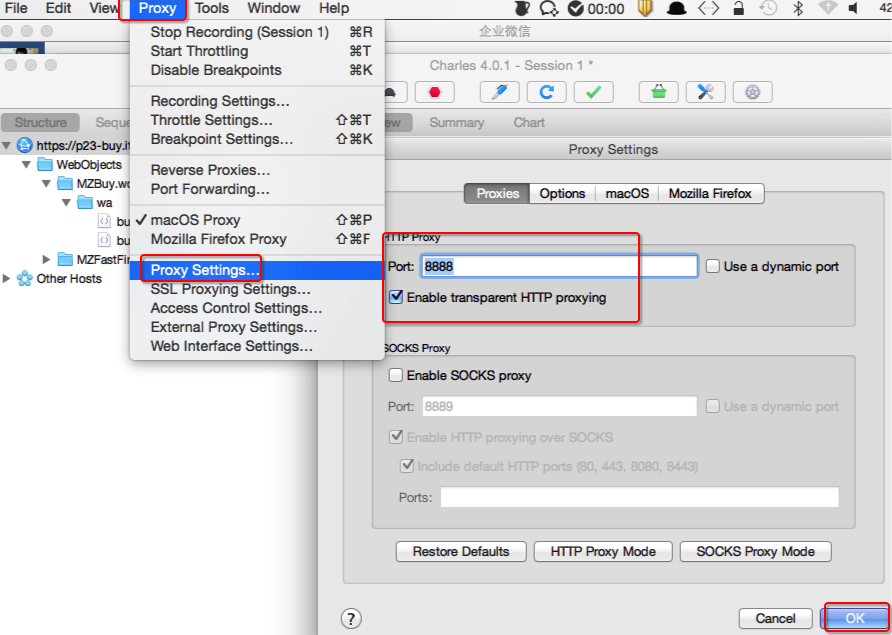
charles,proxy->proxy setting,port使用8888,
勾選enalbe transperent http proxying,開啟代理。
help->local ip address,檢視charles代理的ip地址。
設定手機,如iphone,wifi資訊->http代理,填寫伺服器(charles的代理ip)
與埠(8888)。
手機會連線上charles,允許它連線。
對於https協議,手機上需求安裝ssl的證書:
在safari上輸入http://charlesproxy.com/getssl,跳轉安裝證書。
鎖定目標url,即可拿到資料。
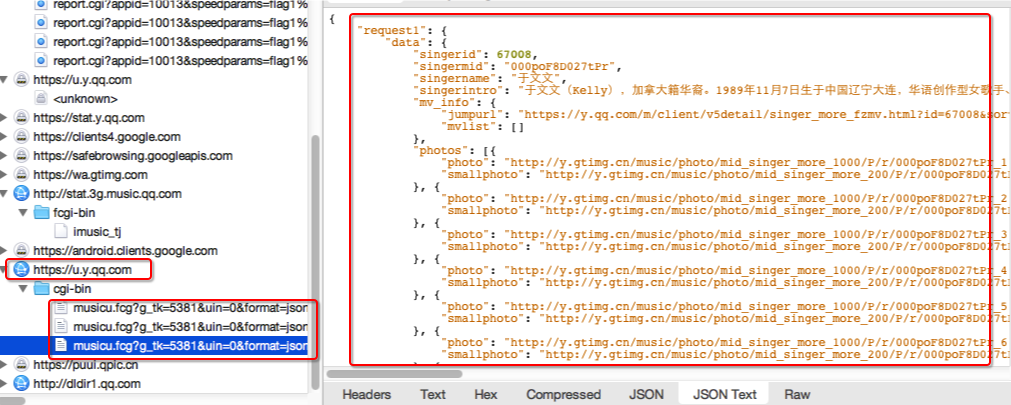
比如,對於iphone上的qq音樂的歌手詳情,目標url是
https://u.y.qq.com,focus它,
右鍵開啟ssl proxy,就可以拿到詳情資訊。大概的演示是這樣的:
(a)charles開啟代理:
(b)手機連上代理後,對https://u.y.qq.com特別處理,可以看到歌手資訊:
(5)演示:獲取“抖音短視訊”的歌曲下載連結
小白:我知道!這個抖音短視訊很好玩的,所有歌曲都只是副歌部分。它的下載連結是可以用的嗎?歌曲是否加密了?
小程:可以用,歌曲至少現在是沒有加密的。(此話的時間,大概是2018年中)
抖音,這時,大概有50幾萬首歌曲。
可以通過搜尋介面或者分類歌曲介面,來取得歌曲列表資訊。歌曲列表資訊是json格式的內容,其中包括這樣的資訊:
"play_url": {
"url_list": [
"http://p3.pstatp.com/obj/29c90000eb8b5ca6fff2"
],
"uri": "29c90000eb8b5ca6fff2"
}, url_list就是歌曲下載連結(請求時需要帶上額外的引數比如cookies等)。除了這個,還可以找到歌手名、歌曲名等。
小白:為什麼不詳細說說請求連結是什麼呀?
小程:因為演示只是為了學習,不應該涉及太多商業的內容。
小白:我去!

相關推薦
網路應用(1):抓包獲取APP的重要資訊 | charles
小白:何為抓包? 小程:就是截獲網路上收發的資料包。 小白:網路上那麼多資料包,怎麼知道哪些是有用的? 小程:只截獲目標app的資料包就縮小了範圍,但即便是縮小了範圍,也需要進一步分析與排查。 小白:在垃圾堆裡找壞人的行動時間與地點嗎?這是使徒行者2的橋段啊,你有沒有看過? "抓
[Python]網路爬蟲(一):抓取網頁的含義和URL基本構成
一、網路爬蟲的定義 網路爬蟲,即Web Spider,是一個很形象的名字。 把網際網路比喻成一個蜘蛛網,那麼Spider就是在網上爬來爬去的蜘蛛。 網路蜘蛛是通過網頁的連結地址來尋找網頁的。 從網站某一個頁面(通常是首頁)開始,讀取網頁的內容,找到在網頁中的其它連結地址
Java 網路程式設計(1):使用 NetworkInterface 獲得本機在區域網內的 IP 地址
原文地址:https://segmentfault.com/a/1190000007462741 1、問題提出 在使用 Java 開發網路程式時,有時候我們需要知道本機在區域網中的 IP 地址。很常見的一種做法是呼叫本地命令(比如 Windows 上的 ipconfig 命令和 Li
MATLAB神經網路學習(1):單層感知器
單層感知器由一個線性組合器和一個二值閾值元件組成。 輸入是一個N維向量 x=[x1,x2,...,xn],其中每一個分量對應一個權值wi,隱含層輸出疊加為一個標量值: 隨後在二值閾值元件中對得到的v值進行判斷,產生二值輸出:
NS3網路模擬(5): 資料包分析
快樂蝦歡迎轉載,但請保留作者資訊在我們生成的xml檔案中,是不包含生成的資料包的資料的,在我們的指令碼中新增下面的語句:pointToPoint.EnablePcapAll("first")再執行fir
手把手教你寫網路爬蟲(1):網易雲音樂歌單
Selenium:是一個強大的網路資料採集工具,其最初是為網站自動化測試而開發的。近幾年,它還被廣泛用於獲取精確的網站快照,因為它們可以直接執行在瀏覽器上。Selenium 庫是一個在WebDriver 上呼叫的API。WebDriver 有點兒像可以載入網站的瀏覽器,但是它也可以像BeautifulSoup
Linux網路程式設計(1):如何使用"unp.h"
俗話說萬事開頭難,學習新知識也是如此,當我們下定決心要實現UNP中的例子時,發現卻無法將程式部署上去,這種感覺是不是很令人沮喪?本文就是用來給我自己這種linux菜鳥掃盲用的。 首先,UNP的原始碼連結為 點選開啟連結,下載完成後使用tar -zxvf命令進行解壓。 $
python3實現網路爬蟲(1)--urlopen抓取網頁的html
準備開始寫一些python3關於爬蟲相關的東西,主要是一些簡單的網頁爬取,給身邊的同學入門看。 首先我們向網路伺服器傳送GET請求以獲取具體的網頁,再從網頁中讀取HTML內容。 我們大家平時都使用網路瀏覽器,並且它已經成為我們上網不可或缺的軟體。它建立資訊的資
網路應用(2):流量與位元速率等 | 流量、頻寬、速度、位元速率
架設網路,按規定,需要拿到工信部頒發的營業執照。我們使用的網路,由運營商提供。運營商指的是網路運營商(提供網際網路服務的組織,也叫ISP),包括:移動、電信、網通、鐵通、長城、天威、教育網、廣電、方正,等等。 現在,運營商提供網路,是收費的,收費的理由,主要還是運營商提供了通道(基站建議等),就相當收路費。那
網路應用(3):CDN與P2P的概念
我前面說了流量的概念,流量是使用網路時經常要考慮的一個因素--如何才能更快的使用流量,如何才能節省流量使用的成本,對於這樣的問題,你可能要了解一下什麼是cdn,什麼是p2p。 (1)cdn是什麼 cdn是一個基於已有的internet網路而進行擴充套件的網路系統,叫作內容分發網路,content delive
網路應用(4):塊的概念 | Range
分塊來處理,也算是自然的想法,就是化整為零。而於對於檔案的下載同樣使用這個道理,既可整體下載,也可分塊下載。 小程這裡以http協議為例,來看一下塊的概念與使用。 http的range http1.0請求與返回檔案都是整體,不支援“只拿一部分資料”,伺服器也不支援斷點續傳(因為不支援從某個點開始拿部分資料),
網路應用(6):http報文結構與curl的使用
http是一個協議,協議就是約定、規定,先不管為什麼這麼約定有什麼高深的東西,為了解決具體問題,我們先要能使用協議,理解協議中對我們有用的那部分資料,是的,我們不是研究生,更不是純研究,所有的研究都要由具體的問題來驅動。 那這裡的具體問題是什麼?就是看懂http的請求跟回覆啊,就像寫某某申請一樣,你不理申請最
網路應用(8):http的封裝與使用
之前講過http的協議,怎麼約定請求或響應的行、頭、體,也介紹怎麼使用curl來完成http的請求。這一次,再接再厲,換一個角度換一些角色,再次說http的封裝與使用。反正目的只有一個:加深對http協議的理解。 (1)tcp的實現 說http的實現,非講tcp不可(為什麼?後面會解釋),而之前講tcp協議的
微信開發(1) :網頁授權獲取使用者的基本資訊 實現微信登入(java)
微信開發(1) :網頁授權獲取使用者的基本資訊 實現微信登入 由於工作需要,最近進行微信開發,然而微信官方的文件,比較模糊。網上大多數,是PHP做的, 本文 使用java語言開發。(後續更新 java版的 微信開放平臺的 公眾號第三方平臺開發) 準備工
Vue系列(1):單頁面應用程序
str from logs 引擎 每次 應用 跳轉方式 新手上路 為什麽 前言:關於頁面上的知識點,如有侵權,請看 這裏 。 關鍵詞:SPA、單個 HTML 文件、全靠 JS 操作、Virtual DOM、hash/history api 路由跳轉、ajax 響應、按需
ASIO—下一代C++標準可能接納的網路庫(1)簡單的應用
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Spring Boot Actuator詳解與深入應用(一):Actuator 1.x
《Spring Boot Actuator詳解與深入應用》預計包括三篇,第一篇重點講Spring Boot Actuator 1.x的應用與定製端點;第二篇將會對比Spring Boot Actuator 2.x 與1.x的區別,以及應用和定製2.x的端點;第三篇將會介紹Actuator metric指
理解OpenShift(1):網路之 Router 和 Route Neutron 理解 (7): Neutron 是如何實現負載均衡器虛擬化的
理解OpenShift(1):網路之Router 和 Route 1. OpenShift 為什麼需要 Router 和 Route? 顧名思義,Router 是路由器,Route 是路由器中配置的路由。OpenShift 中的這兩個概念是為了解決從叢集外部(就是從除了叢集節點
Vue系列(1):單頁面應用程式
前言:關於頁面上的知識點,如有侵權,請看 這裡 。 關鍵詞:SPA、單個 HTML 檔案、全靠 JS 操作、Virtual DOM、hash/history api 路由跳轉、ajax 響應、按需載入、MVVM SPA 我們先來看一下在百科上面的解釋吧,emmmm,一般呢,我每次搜尋一些不懂的詞,都會
[Python]網路爬蟲(二):利用urllib2通過指定的URL抓取網頁內容
版本號:Python2.7.5,Python3改動較大,各位另尋教程。 所謂網頁抓取,就是把URL地址中指定的網路資源從網路流中讀取出來,儲存到本地。 類似於使用程式模擬IE瀏覽器的功能,把URL作為HTTP請求的內容傳送到伺服器端, 然後讀取伺服器端的響應資源。 在