
馬蜂窩ABTest多層分流系統的設計與實現
導讀:
5 月 23 日,馬蜂窩旅遊網宣佈完成 2.5 億美元新一輪融資,此輪融資由騰訊領投。
在接授騰訊《潛望》欄目的專訪時,馬蜂窩 CEO 陳罡談到,「現在馬蜂窩是個資料驅動的公司,要以結果說話,能用 ABTest 解決的問題就沒有必要談其他」。
作為一家資料驅動的公司,當前在馬蜂窩 ABTest 已經基本覆蓋所有業務線並穩定執行。本篇文章,我們就來說一說驅動馬蜂窩快速增長和優化的 ABTest 是什麼,它究竟長什麼樣子。
什麼是 ABTest
產品的改變不是由我們隨便「拍腦袋」得出,而是需要由實際的資料驅動,讓使用者的反饋來指導我們如何更好地改善服務。正如馬蜂窩 CEO 陳罡在接受專訪時所說:「有些東西是需要 Sense,但大部分東西是可以用 Science 來做判斷的。」
說到 ABTest 相信很多讀者都不陌生。簡單來說,ABTest 就是將使用者分成不同的組,同時線上試驗產品的不同版本,通過使用者反饋的真實資料來找出採用哪一個版本方案更好的過程。
我們將原始版本作為對照組,以每個版本進行儘量是小的流量迭代作為原則去使用 ABTest。一旦指標分析完成,使用者反饋資料表現最佳的版本再去全量上線。
很多時候,一個按鈕、一張圖片或者一句文案的調整,可能都會帶來非常明顯的增長。這裡分享一個ABTest 在馬蜂窩的應用案例:

如圖所示,之前我們交易中心的電商業務團隊希望優化一個關於「滑雪」的搜尋列表。可以看到優化之前的頁面顯示從感覺上是比較單薄的。但是大家又不確定複雜一些的展現形式會不會讓使用者覺得不夠簡潔,產生反感。因此,我們將改版前後的頁面放在線上進行了 ABTest。最終的資料反饋表明,優化之後的樣式 UV 提高了 15.21%,轉化率提高了 11.83%。使用 ABTest 幫助我們降低了迭代的風險。
通過這個例子,我們可以更加直觀地理解 ABTest 的幾個特性:
-
先驗性:採用流量分割與小流量測試的方式,先讓線上部分小流量使用者使用,來驗證我們的想法,再根據資料反饋來推廣到全流量,減少產品損失。
-
並行性:我們可以同時執行兩個或兩個以上版本的試驗同時去對比,而且保證每個版本所處的環境一致的,這樣以前整個季度才能確定要不要發版的情況,現在可能只需要一週的時間,避免流程複雜和週期長的問題,節省驗證時間。
-
科學性:統計試驗結果的時候,ABTest 要求用統計的指標來判斷這個結果是否可行,避免我們依靠經驗主義去做決策。
為了讓我們的驗證結論更加準確、合理並且高效,我們參照 Google 的做法實現了一套演算法保障機制,來嚴格實現流量的科學分配。
基於 Openresty 的多層分流模型
大部分公司的 ABTest 都是通過提供介面,由業務方獲取使用者資料然後呼叫介面的方式進行,這樣會將原有的流量放大一倍,並且對業務侵入比較明顯,支援場景較為單一,導致多業務方需求需要開發出很多分流系統,針對不同的場景也難以複用。
為了解決以上問題,我們的分流系統選擇基於 Openresty 實現,通過 HTTP 或者 GRPC 協議來傳遞分流資訊。這樣一來,分流系統就工作在業務的上游,並且由於 Openresty 自帶流量分發的特性不會產生二次流量。對於業務方而言,只需要提供差異化的服務即可,不會侵入到業務當中。
選型 Openresty 來做 ABTest 的原因主要有以下幾個:

整體流程
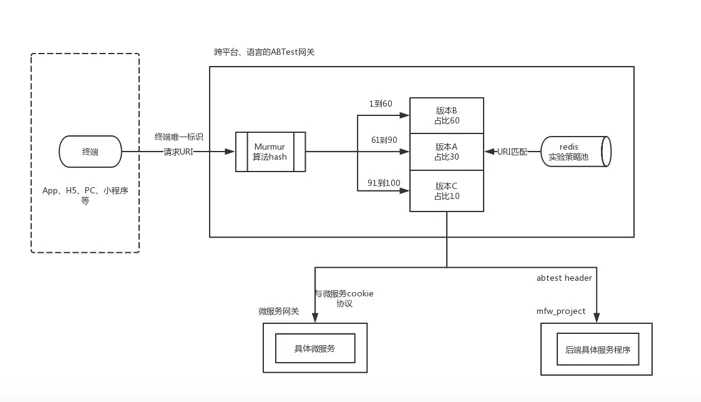
在設計 ABTest 系統的時候我們拆分出來分流三要素,第一是確定的終端,終端上包含了裝置和使用者資訊;第二是確定的 URI ;第三是與之匹配的分配策略,也就是流量如何分配。
首先裝置發起請求,AB 閘道器從請求中提取裝置 ID 、URI 等資訊,這時終端資訊和 URI 資訊已經確定了。然後通過 URI 資訊遍歷匹配到對應的策略,請求經過分流演算法找到當前匹配的 AB 實驗和版本後,AB 閘道器會通過兩種方式來通知下游。針對執行在物理 web 機的應用會在 header 中新增一個名為 abtest 的 key,裡面包含命中的 AB 實驗和版本資訊。針對微服務應用,會將命中微服務的資訊新增到 Cookie 中交由微服務閘道器去處理。
穩定分流保障:MurmurHash演算法
分流演算法我們採用的 MurmurHash 演算法,參與演算法的 Hash 因子有裝置 id、策略 id、流量層 id。
MurmurHash 是業內 ABTest 常用的一個演算法,它可以應用到很多開源專案上,比如說 Redis、Memcached、Cassandra、HBase 等。MurmurHash 有兩個明顯的特點:
-
快,比安全雜湊演算法快幾十倍
-
變化足夠激烈,對於相似字串,比如說「abc」和「 abd 」能夠均勻散佈在雜湊環上,主要是用來實現正交和互斥實驗的分流
下面簡單解釋下正交和互斥:
-
互斥。指兩個實驗流量獨立,使用者只能進入其中一個實驗。一般是針對於同一流量層上的實驗而言,比如圖文混排列表實驗和純圖列表實驗,同一個使用者在同一時刻只能看到一個實驗,所以他們互斥。
-
正交。正交是指使用者進入所有的實驗之間沒有必然關係。比如進入實驗 1 中 a 版本的使用者再進行其它實驗時也是均勻分佈的,而不是集中在某一塊區間內。
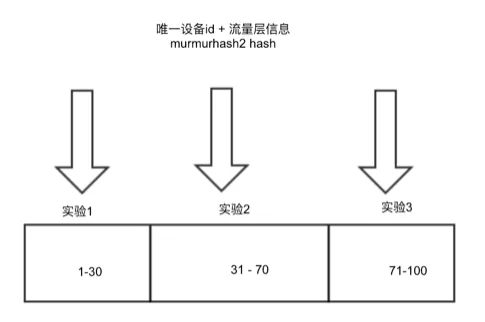
流量層內實驗分流
流量層內實驗的 hash 因子有裝置 id、流量層 id。當請求流經一個流量層時,只會命中層內一個實驗,即同一個使用者同一個請求每層最多隻會命中一個實驗。首先對 hash 因子進行 hash 操作,採用 murmurhash2 演算法,可以保證 hash 因子微小變化但是結果的值變化激烈,然後對 100 求餘之後+1,最終得到 1 到 100 之間的數值。
示意圖如下:
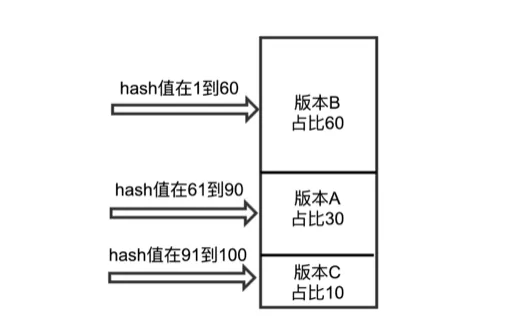
實驗內版本分流
實驗的 hash 因子有裝置 id、策略 id、流量層 id。採用相同的策略進行版本匹配。匹配規則如下:
穩定性保障:多級快取策略
剛才說到,每一個請求來臨之後,系統都會嘗試去獲取與之匹配的實驗策略。實驗策略是在從後臺配置的,我們通過訊息佇列的形式,將經過配置之後的策略,同步到我們的策略池當中。
我們最初的方案是每一個請求來臨之後,都會從 Redis 當中去讀取資料,這樣的話對 Redis 的穩定性要求較高,大量的請求也會對 Redis 造成比較高的壓力。因此,我們引入了多級快取機制來組成策略池。策略池總共分為三層:
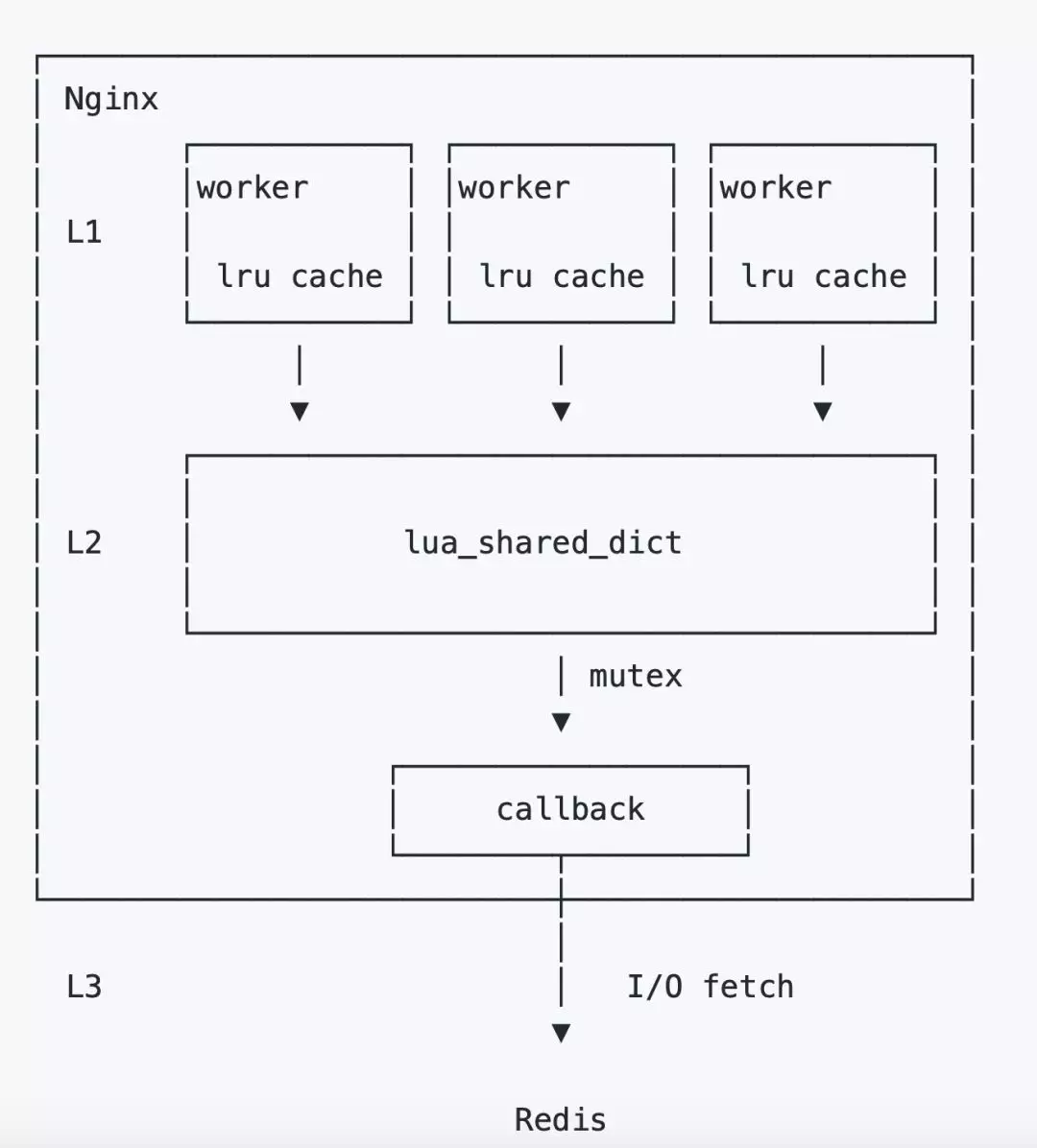
第一層 lrucache,是一個簡單高效的快取策略。它的特點是伴隨著 Nginx worker 程序的生命週期存在,worker 獨佔,十分高效。由於獨佔的特性,每一份快取都會在每個 worker 程序中存在,所以它會佔用較多的記憶體。
第二層 lua_shared_dict,顧名思義,這個快取可以跨 worker 共享。當 Nginx reload 時它的資料也會不丟失,只有當 restart 的時候才會丟失。但有個特點,為了安全讀寫,實現了讀寫鎖。所以再某些極端情況下可能會存在效能問題。
第三層 Redis。
從整套策略上來看,雖然採用了多級快取,但仍然存在著一定的風險,就是當 L1、L2 快取都失效的時候(比如 Nginx restart),可能會面臨因為流量太大讓 Redis 「裸奔」的風險,這裡我們用到 lua-resty-lock 來解決這個問題,在快取失效時只有拿到鎖的這部分請求才可以進行回源,保證了 Redis 的壓力不會那麼大。
我們在快取 30s 的情況下對線上資料的進行統計顯示,第一級快取命中率在 99% 以上,第二級快取命中率在 0.5 %,回源到 Redis 的請求只有 0.03 %。
關鍵特性
-
吞吐量:當前承擔全站 5% 流量
-
低延遲:線上平均延時低於 2ms
-
全平臺:支援 App、H5、WxApp、PC,跨語言
-
容災:
-
自動降級:當從 redis 中讀取策略失敗後,ab 會自動進入到不分流模式,以後每 30s 嘗試 (每臺機器) 讀取 redis,直到讀取到資料,避免頻繁傳送
-
請求手動降級:當出現 server_event 日誌過多或系統負載過高時,通過後臺「一鍵關閉」來關閉所有實驗或關閉 AB 分流
效能表現
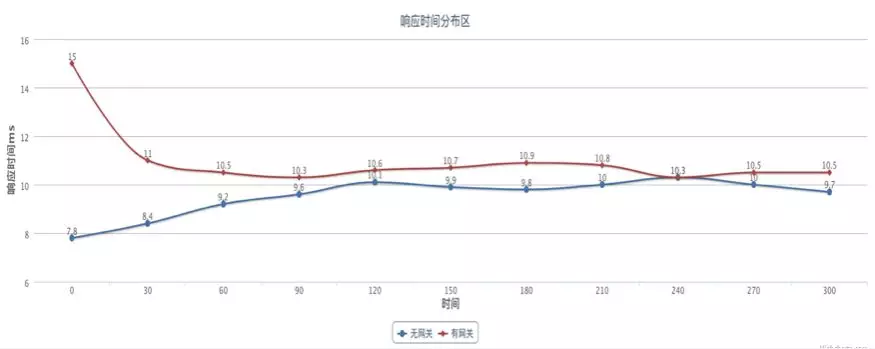
響應時間分佈
TPS 分佈
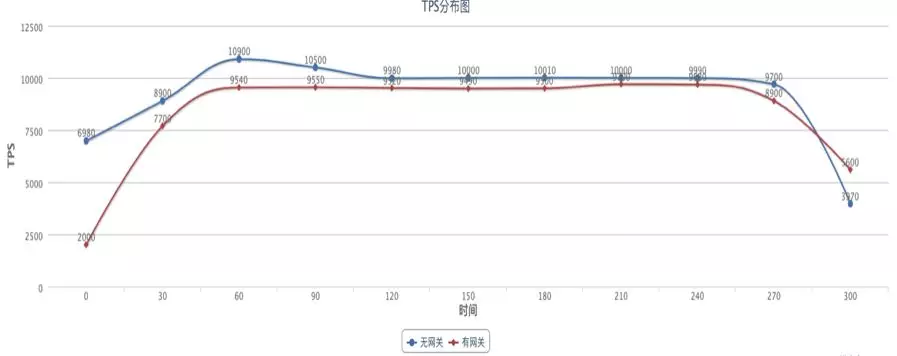
測試工具採用 JMeter,併發數 100,持續 300s。
從響應時間來看,除了剛開始的時候請求偏離值比較大,之後平均起來都在 1ms 以內。分析剛開始的時候差距比較大的原因在於當時的多級快取裡面沒有資料。
TPS的壓測表現有一些輕微的下降,因為畢竟存在 hash 演算法,但總體來說在可以接受的範圍內。
A/B釋出
常規 A/B 釋出主要由 API 閘道器來做,當面臨的業務需求比較複雜時, A/B 釋出會通過與與微服務互動的方式,來開放更復雜維度的 A/B 釋出能力。
小結
需要注意的是,ABTest 並不完全適用於所有的產品,因為 ABTest 的結果需要大量資料支撐,日流量越大的網站得出結果越準確。通常來說,我們建議在進行 A/B 測試時,能夠保證每個版本的日流量在 1000 個 UV 以上,否則試驗週期將會很長,或很難獲得準確(結果收斂)的資料結果推論。
要設計好一套完整的 ABTest 平臺,需要進行很多細緻的工作,由於篇幅所限,本文只圍繞分流演算法進行了重點分享。總結看來,馬蜂窩 ABTest 分流系統重點在以下幾個方面取得了一些效果:
-
採用流量攔截分發的方式,摒棄了原有介面的形式,對業務程式碼沒有侵入,效能沒有明顯影響,且不會產生二次流量。
-
採用流量分層並繫結實驗的策略,可以更精細直觀的去定義分流實驗。通過和客戶端上報已命中實驗版本的機制,減少了服務資料的儲存並可以實現序列實驗分流的功能。
-
在資料傳輸方面,通過在 HTTP 頭部增加分流資訊,業務方無需關心具體的實現語言。
近期規劃改善:
-
監控體系。
-
使用者畫像等精細化定製AB。
-
統計功效對於置信區間、特徵值等產品化功能支援。
-
通過 AARRR 模型評估實驗對北極星指標的影響。
這套系統未來需要改進的地方還有很多,我們也將持續探索,期待和大家一起交流。
本文作者:李培,馬蜂窩基礎平臺資訊化研發技術專家;張立虎,馬蜂窩酒店研發靜態資料團隊工程師。
(馬蜂窩技術原創內容,轉載務必註明出處儲存文末二維碼圖片,謝謝配合。)

關注馬蜂窩技術,找到更多你需要的