
Python 和 Elasticsearch 構建簡易搜尋
Python 和 Elasticsearch 構建簡易搜尋
作者:白寧超
2019年5月24日17:22:41
導讀:件開發最大的麻煩事之一就是環境配置,作業系統設定,各種庫和元件的安裝。只有它們都正確,軟體才能執行。如果從一種作業系統裡面執行另一種作業系統,通常我們採取的策略就是引入虛擬機器,比如在 Windows 系統裡面執行 Linux 系統。這種方式有個很大的缺點就是資源佔用多、冗餘步驟多、啟動慢。目前最流行的 Linux 容器解決方案之一就是Docker,它最大優點就是輕量、資源佔用少、啟動快。本文從什麼是Docker?Docker解決什麼問題?有哪些好處?如何去部署實現去全面介紹。
1 ES基本介紹
1.1 概念介紹
Elasticsearch是一個基於Lucene庫的搜尋引擎。它提供了一個分散式、支援多租戶的全文搜尋引擎,它可以快速地儲存、搜尋和分析海量資料。Elasticsearch可以用於搜尋各種文件。它提供可擴充套件的搜尋,具有接近實時的搜尋,並支援多租戶。Elasticsearch至少需要Java 8。Elasticsearch是分散式的,這意味著索引可以被分成分片,每個分片可以有0個或多個副本。每個節點託管一個或多個分片,並充當協調器將操作委託給正確的分片。相關資料通常儲存在同一個索引中,該索引由一個或多個主分片和零個或多個複製分片組成。一旦建立了索引,就不能更改主分片的數量。
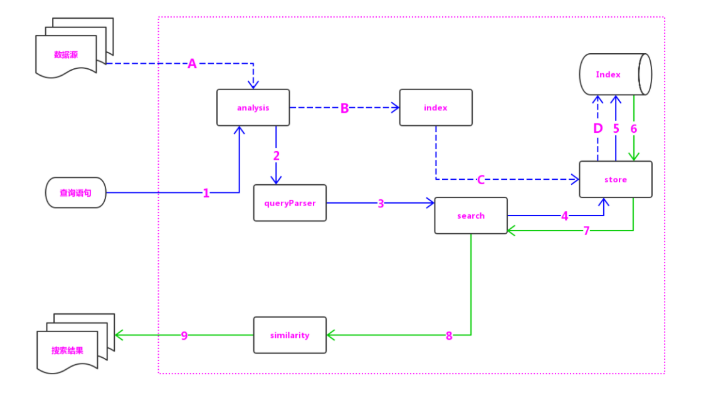
- 叢集(Cluster):叢集是一個或多個節點(伺服器)的集合,它們共同儲存您的整個資料,並提供跨所有節點的聯合索引和搜尋功能。本質上是一個分散式資料庫,允許多臺伺服器協同工作,每臺伺服器可以執行多個 Elastic 例項。單個 Elastic 例項稱為一個節點(node)。一組節點構成一個叢集(cluster)。
- 節點(Node):節點是作為叢集一部分的單個伺服器,儲存資料並參與群集的索引和搜尋功能。
- 索引(Index):索引是具有某些類似特徵的文件集合。索引由名稱標識(必須全部小寫),此名稱用於在對其中的文件執行索引,搜尋,更新和刪除操作時引用索引。 資料管理的頂層單位就叫做 Index(索引)。它是單個數據庫的同義詞。每個 Index (即資料庫)的名字必須是小寫。
- 文件(Document):文件是可以編制索引的基本資訊單元。Index 裡面單條的記錄稱為 Document(文件)。許多條 Document 構成了一個 Index。Document 使用 JSON 格式表示,同一個 Index 裡面的 Document,不要求有相同的結構(scheme),但是最好保持相同,這樣有利於提高搜尋效率。
- 分片和副本(Shards & Replicas):索引可能儲存大量可能超過單個節點的硬體限制的資料。為了解決這個問題,Elasticsearch提供了將索引細分為多個稱為分片的功能。建立索引時,只需定義所需的分片數即可。每個分片本身都是一個功能齊全且獨立的“索引”,可以託管在叢集中的任何節點上。
- 副本集很重要:它在分片/節點發生故障時提供高可用性。它允許您擴充套件搜尋量/吞吐量,因為可以在所有副本上並行執行搜尋。預設情況下,Elasticsearch中的每個索引都分配了5個主分片和1個副本,這意味著如果群集中至少有兩個節點,則索引將包含5個主分片和另外5個副本分片(1個完整副本),總計為每個索引10個分片。
1.2 應用場景
- 線上網上商店,允許客戶搜尋您銷售的產品。在這種情況下,可以使用Elasticsearch儲存整個產品目錄和庫存,併為它們提供搜尋和自動填充建議。
- 收集日誌或交易資料,並分析和挖掘此資料以查詢趨勢,統計資訊,摘要或異常。在這種情況下,您可以使用Logstash(Elasticsearch / Logstash / Kibana堆疊的一部分)來收集,聚合和解析資料,然後讓Logstash將此資料提供給Elasticsearch。一旦資料在Elasticsearch中,您就可以執行搜尋和聚合來挖掘您感興趣的任何資訊。
- 價格警報平臺,允許精通價格的客戶指定一條規則,例如“我有興趣購買特定的電子產品,如果小工具的價格在下個月內從任何供應商降至X美元以下,我希望收到通知” 。在這種情況下,您可以刮取供應商價格,將其推入Elasticsearch並使用其反向搜尋功能來匹配價格變動與客戶查詢,並最終在發現匹配後將警報推送給客戶。
1.3 核心模組
- analysis:主要負責詞法分析及語言處理,也就是我們常說的分詞,通過該模組可最終形成儲存或者搜尋的最小單元 Term。
- index 模組:主要負責索引的建立工作。
- store 模組:主要負責索引的讀寫,主要是對檔案的一些操作,其主要目的是抽象出和平臺檔案系統無關的儲存。
- queryParser 模組:主要負責語法分析,把我們的查詢語句生成 Lucene 底層可以識別的條件。
- search 模組:主要負責對索引的搜尋工作。
- similarity 模組:主要負責相關性打分和排序的實現。
1.4 檢索方式
- 單個詞查詢:指對一個 Term 進行查詢。比如,若要查詢包含字串“Lucene”的文件,則只需在詞典中找到 Term“Lucene”,再獲得在倒排表中對應的文件連結串列即可。
- AND:指對多個集合求交集。比如,若要查詢既包含字串“Lucene”又包含字串“Solr”的文件,則查詢步驟如下:在詞典中找到 Term “Lucene”,得到“Lucene”對應的文件連結串列。在詞典中找到 Term “Solr”,得到“Solr”對應的文件連結串列。合併連結串列,對兩個文件連結串列做交集運算,合併後的結果既包含“Lucene”也包含“Solr”。
- OR:指多個集合求並集。比如,若要查詢包含字串“Luence”或者包含字串“Solr”的文件,則查詢步驟如下:在詞典中找到 Term “Lucene”,得到“Lucene”對應的文件連結串列。在詞典中找到 Term “Solr”,得到“Solr”對應的文件連結串列。合併連結串列,對兩個文件連結串列做並集運算,合併後的結果包含“Lucene”或者包含“Solr”。
- NOT:指對多個集合求差集。比如,若要查詢包含字串“Solr”但不包含字串“Lucene”的文件,則查詢步驟如下:在詞典中找到 Term “Lucene”,得到“Lucene”對應的文件連結串列。在詞典中找到 Term “Solr”,得到“Solr”對應的文件連結串列。合併連結串列,對兩個文件連結串列做差集運算,用包含“Solr”的文件集減去包含“Lucene”的文件集,運算後的結果就是包含“Solr”但不包含“Lucene”。
通過上述四種查詢方式,我們不難發現,由於 Lucene 是以倒排表的形式儲存的。所以在 Lucene 的查詢過程中只需在詞典中找到這些 Term,根據 Term 獲得文件連結串列,然後根據具體的查詢條件對連結串列進行交、並、差等操作,就可以準確地查到我們想要的結果。相對於在關係型資料庫中的“Like”查詢要做全表掃描來說,這種思路是非常高效的。雖然在索引建立時要做很多工作,但這種一次生成、多次使用的思路也是很高明的。
1.5 ES特性
- Elasticsearch可擴充套件高達PB級的結構化和非結構化資料。
- Elasticsearch可以用來替代MongoDB和RavenDB等做文件儲存。
- Elasticsearch使用非標準化來提高搜尋效能。
- Elasticsearch是受歡迎的企業搜尋引擎之一,目前被許多大型組織使用,如Wikipedia,The Guardian,StackOverflow,GitHub等。
- Elasticsearch是開放原始碼,可在Apache許可證版本
2.0下提供。
1.6 ES優點
- Elasticsearch是基於Java開發的,這使得它在幾乎每個平臺上都相容。
- Elasticsearch是實時的,換句話說,一秒鐘後,新增的文件可以在這個引擎中搜索得到。
- Elasticsearch是分散式的,這使得它易於在任何大型組織中擴充套件和整合。
- 通過使用Elasticsearch中的閘道器概念,建立完整備份很容易。
- 與Apache Solr相比,在Elasticsearch中處理多租戶非常容易。
- Elasticsearch使用JSON物件作為響應,這使得可以使用不同的程式語言呼叫Elasticsearch伺服器。
- Elasticsearch支援幾乎大部分文件型別,但不支援文字呈現的文件型別。
1.7 ES缺點
- Elasticsearch在處理請求和響應資料方面沒有多語言和資料格式支援(僅在JSON中可用),與Apache Solr不同,Elasticsearch不可以使用CSV,XML等格式。
- Elasticsearch也有一些傷腦的問題發生,雖然在極少數情況下才會發生。
2 ES的安裝部署
本文主要採用Win10下的Elasticsearch安裝,當然Linux安裝操作起來更加簡便了。完成之後對python安裝elasticsearch包,並實現互動案例。
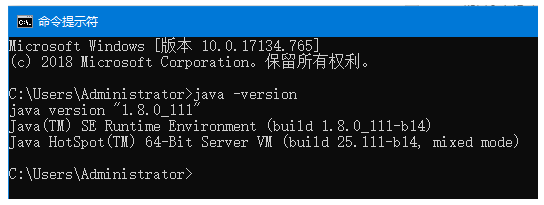
第一步:條件檢查:Elasticsearch至少需要Java 8,首先需要java -version檢視當前版本。
第二步:安裝ES,這裡採用elasticsearch-7.1.0-windows-x86_64下載地址連結: https://pan.baidu.com/s/1k5AOGpMy8uJEXtA6KoNb7g 提取碼: qtmj 。
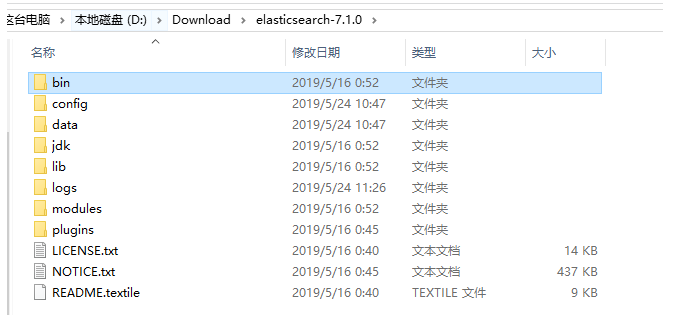
bin :執行Elasticsearch例項和外掛管理所需的指令碼 confg: 配置檔案所在的目錄 lib : Elasticsearch使用的庫 data : Elasticsearch使用的所有資料的儲存位置 logs : 關於事件和錯誤記錄的檔案 plugins: 儲存所安裝外掛的地方,比如中文分詞工具 work : Elasticsearch使用的臨時檔案,這個檔案我這暫時好像沒有,可以根據配置檔案來 配置這些個檔案的目錄位置,比如上面的data,logs,
然後去執行 bin/elasticsearch(Mac 或 Linux)或者 bin\elasticsearch.bat (Windows) 即可啟動 Elasticsearch 了。我們啟動後發現網頁並不現實資訊,測試下本地網路是否聯通:

發現是一般性故障,查詢資料顯示由於防火牆的問題,經過測試關閉”公用網路防火牆“即可:
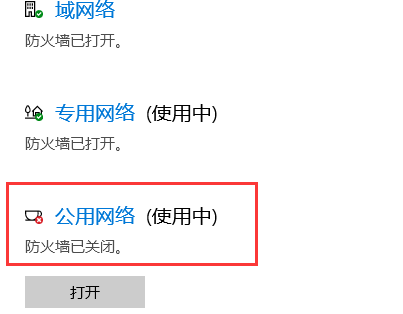
之後我們再去ping下本地IP:
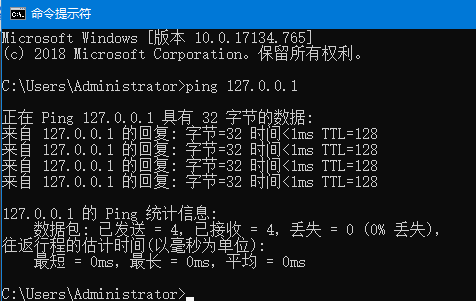
這時已經顯示ping通狀態,再次啟動bin\elasticsearch.bat (Windows),開啟http://localhost:9200/顯示如下表示成功安裝ES。
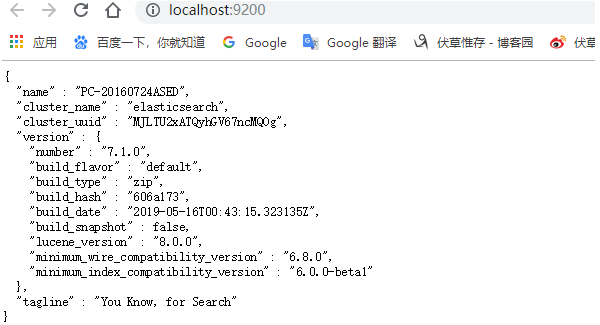
第三步:Python安裝ES, 下載地址是https://www.elastic.co/downloads/elasticsearch。如果在windows下安排部署參考文章http://www.cnblogs.com/viaiu/p/5715200.html。如果是Python開發可以使用pip install elasticsearch安裝。
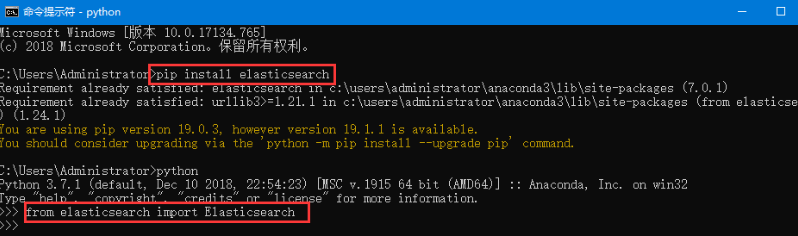
3 Python和ES構建搜尋引擎
插入資料:開啟python執行環境,首先匯入【from elasticsearch import Elasticsearch】,然後編寫插入資料的方法:
# 插入資料
def InsertDatas():
# 預設host為localhost,port為9200.但也可以指定host與port
es = Elasticsearch()
es.create(index="my_index",doc_type="test_type",id=11,ignore=[400,409],body={"name":"python","addr":'四川省'})
# 查詢結果
result = es.get(index="my_index",doc_type="test_type",id=11)
print('單條資料插入完成:\n',result)
例項化Elasticsearch,其中預設為空即host為localhost,port為9200。為空也可以指定網路IP與埠。通過建立索引index和文件類別doc_type,文件id,body為插入資料的內容,其中ES支援的資料僅為JSON型別,ignore=409忽略異常。執行結果如下:

批量插入資料:上面案例我們插入一條資訊,查詢顯示一系列引數包括索引、文件型別、文件ID唯一標識,版本號等。其中資源中包含資料資訊,如果我們想插入多條資訊可以參考以下程式碼:
# 批量插入資料
def AddDatas():
es = Elasticsearch()
datas = [{
'name': '美國留給伊拉克的是個爛攤子',
'addr': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm'
},{
"name":"python",
"addr":'四川省'
}]
for i,data in enumerate(datas):
es.create(index="my_index",doc_type="test_type",
id=i,ignore=[400,409],body=data)
# 查詢結果
result = es.get(index="my_index",doc_type="test_type",id=0)
print('\n批量插入資料完成:\n',result['_source'])
我們將資料放在datas列表中,如果我們資料在一個json檔案中儲存,也可以通過讀取文字資訊並儲存在datas中,之後對其進行插入即可。這裡面檔案ID我採用列舉的序號,也可以採用隨機數或者指定格式。完成所有插入之後我們選擇第一條id=0的資訊查詢,此處查詢與上文不同,我們只看文章內容可以採用result['_source']方法,結果如下:

更新資料:如果我們插入資料資訊有問題,我們想去修正。可以採用update方法,這裡面與我們接觸的MySQL,MongoDB等SQL語句差不多。唯一注意的是我們更新資料時候採用{"doc":{"name":"python1","addr":"深圳1"}}字典模式,尤其是doc標識不能忘記,程式碼實現如下:
# 3 更新資料
def UpdateDatas():
es = Elasticsearch()
es.update(index="my_index",doc_type="test_type",
id=11,ignore=[400,409],body={"doc":{"name":"python1","addr":"深圳1"}})
# 更新結果
result = es.get(index="my_index",doc_type="test_type",id=11)
print('\n資料id=11更新完成:\t',result['_source']['name'])
這裡我們假如只想查詢更新後資訊的name欄位,可以採用source後面加['name']方法,為什麼這麼設定呢?請參看插入資料執行結果分析。

刪除資料:這裡面比較簡單,我們指定文件的索引、文件型別和文件ID即可。
# 刪除資料
def DeleteDatas():
es = Elasticsearch()
result = es.delete(index='my_index',doc_type='test_type',id=11)
print('\n資料id=11刪除完成:\t')
條件查詢資料:我們通過插入資料構建一個簡單我資料資訊,如果我們想獲取索引中的所有文件可以採用{"query":{"match_all":{}}}條件查詢,這裡面指定關注的是使用的search方法,上文查詢資料採用get方法,其實兩者都是可以作為查詢使用的。程式碼如下:
# 條件查詢
def ParaSearch():
es = Elasticsearch()
query1 = es.search(index="my_index", body={"query":{"match_all":{}}})
print('\n查詢所有文件\n',query1)
query2 = es.search(index="my_index", body={"query":{"term":{'name':'python'}}})
print('\n查詢名字Python的文件:\n',query2['hits']['hits'][0])
我們獲取索引所有文件的資訊

獲取文件中name為Python的資訊

4 技術交流共享QQ群
【機器學習和自然語言QQ群:436303759】:
機器學習和自然語言(QQ群號:436303759)是一個研究深度學習、機器學習、自然語言處理、資料探勘、影象處理、目標檢測、資料科學等AI相關領域的技術群。其宗旨是純粹的AI技術圈子、綠色的交流環境。本群禁止有違背法律法規和道德的言談舉止。群成員備註格式:城市-自命名。微信訂閱號:datathinks