
Mysql內連線、左連線會出現笛卡爾積的理解
先簡單解釋一下笛卡爾積。
現在,我們有兩個集合A和B。
A = {0,1} B = {2,3,4}
集合 A×B 和 B×A的結果集就可以分別表示為以下這種形式:
A×B = {(0,2),(1,2),(0,3),(1,3),(0,4),(1,4)};
B×A = {(2,0),(2,1),(3,0),(3,1),(4,0),(4,1)};
以上A×B和B×A的結果就可以叫做兩個集合相乘的‘笛卡爾積’。
從以上的資料分析我們可以得出以下兩點結論:
1,兩個集合相乘,不滿足交換率,既 A×B ≠ B×A;
2,A集合和B集合相乘,包含了集合A中元素和集合B中元素相結合的所有的可能性。既兩個集合相乘得到的新集合的元素個數是 A集合的元素個數 × B集合的元素個數;
MySQL的多表查詢(笛卡爾積原理)
- 先確定資料要用到哪些表。
- 將多個表先通過笛卡爾積變成一個表。
- 然後去除不符合邏輯的資料(根據兩個表的關係去掉)。
- 最後當做是一個虛擬表一樣來加上條件即可。
資料庫表連線資料行匹配時所遵循的演算法就是以上提到的笛卡爾積,表與表之間的連線可以看成是在做乘法運算。
比如現在資料庫中有兩張表,student表和 student_subject表,如下所示:
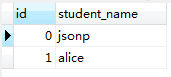
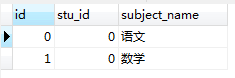
我們執行以下的sql語句,只是純粹的進行表連線。
SELECT * from student JOIN student_subject; SELECT * from student_subject JOIN student;
看一下執行結果:
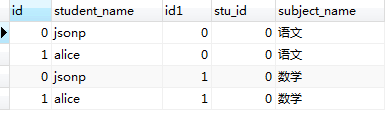
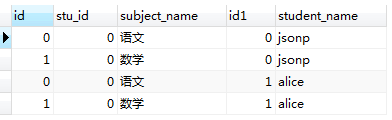
表1.0 表1.1
從執行結果上來看,結果符合我們以上提出的兩點結論(紅線標註部分);
以第一條sql語句為例我們來看一下他的執行流程,
1,from語句把student表 和 student_subject表從資料庫檔案載入到記憶體中。
2,join語句相當於對兩張表做了乘法運算,把student表中的每一行記錄按照順序和student_subject表中記錄依次匹配。
3,匹配完成後,我們得到了一張有 (student中記錄數 × student_subject表中記錄數)條的臨時表。 在記憶體中形成的臨時表如表1.0所示。我們又把記憶體中表1.0所示的表稱為‘笛卡爾積表’。
針對以上的理論,我們提出一個問題,難道表連線的時候都要先形成一張笛卡爾積表嗎,如果兩張表的資料量都比較大的話,那樣就會佔用很大的記憶體空間這顯然是不合理的。所以,我們在進行表連線查詢的時候一般都會使用JOIN xxx ON xxx的語法,ON語句的執行是在JOIN語句之前的,也就是說兩張表資料行之間進行匹配的時候,會先判斷資料行是否符合ON語句後面的條件,再決定是否JOIN。
因此,有一個顯而易見的SQL優化的方案是,當兩張表的資料量比較大,又需要連線查詢時,應該使用 FROM table1 JOIN table2 ON xxx的語法,避免使用 FROM table1,table2 WHERE xxx 的語法,因為後者會在記憶體中先生成一張資料量比較大的笛卡爾積表,增加了記憶體的開銷。
下面引出Mysql的左右連線和內連線的笛卡爾積...
一個同事跟我討論左連線查詢,是不是笛卡爾積。我第一反應,左連線肯定不是笛卡爾積啊,左連線是以左表為準,左表有m條記錄,則結果集是m條記錄(哈哈,如果是你,你是不是也是這樣的反映),同事聽了,說內連線會是笛卡爾積。在資料庫裡試驗了一下,發現,事實比想象中要複雜。
首先說下結論:連結查詢,如果on條件是非唯一欄位,會出現笛卡爾積(區域性笛卡爾積);如果on條件是表的唯一欄位,則不會出現笛卡爾積。
下面是具體的試驗:
文中會有兩張表,user表和job表,表資料如下,其中user為5條記錄,job為4條記錄
USER:  job:
job: 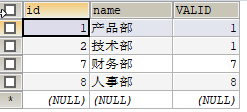
1.交叉連線
如果A表有m(5)條記錄,m1條符合on條件,B表有n(4)條記錄,有n1條符合on條件,無條件交叉連線的結果為: m*n=5*4=20
SELECT * FROM `user` CROSS JOIN job; 這種等同於(交叉查詢等於不加on的內連線)
SELECT * FROM `user` , job;sql執行結果:總共20條記錄
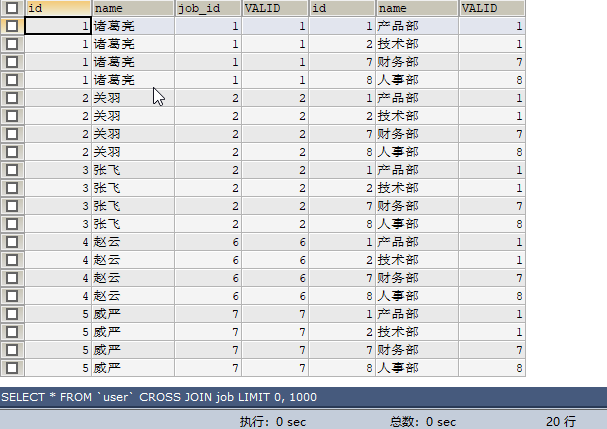
結論:交叉連線,會產生笛卡爾積。
2.內連線(可以當做左連線的特殊情況,只保留符合主表中on條件的記錄)
(1)內連線唯一欄位
如果A表有m(5)條記錄,m1(4)條符合on條件,B表有n(4)條記錄,有n1(3)條符合on條件,內連線唯一欄位結果為:m1=4
1,2,2,6,7 和 1,2,7,8對比,以user表為主表,因為主表中有4條符合條件的記錄(1,2,2,7),而job表有3條符合條件的記錄(1,2,7),取兩者中的最大的,所以為4條
SELECT * FROM `user` u JOIN job j ON u.JOB_ID=j.ID;sql執行結果為:4條記錄
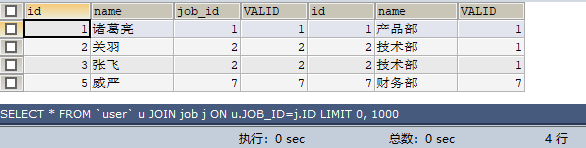
結論:假如,內連線查詢,on條件是A表或者B表的唯一欄位,則結果集是兩表的交集,不是笛卡爾積。
(2)內連線非唯一欄位
如果A表有m(5)條記錄,m1(2)條符合on條件,B表有n(4)條記錄,有n1(3)條符合on條件,則結果集是m1*n1=5*4=20
1,2,2,6,7 和 1,1,7,8對比,以user表為主表,因為主表中有2條符合條件的記錄(1,7),而job表有3條符合條件的記錄(1,1,7),取兩者中的最大的,所以為3條
SELECT * FROM `user` u JOIN job j ON u.valid=j.valid;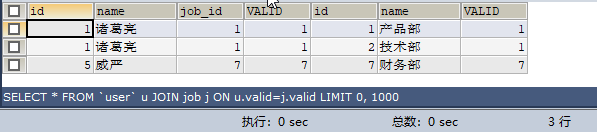
結論:假如,on條件是表中非唯一欄位,則結果集是兩表匹配到的結果集的笛卡爾積(區域性笛卡爾積) 。
3.外連線
(1)左連線
a.左連線唯一欄位
假如A表有m(5)條記錄,B表有n(4)條記錄,則結果集是m=5
1,2,2,6,7 和 1,2,7,8對比,以user表為主表,因為主表中有4條符合條件的記錄(1,2,2,7),而job表有3條符合條件的記錄(1,2,7),取兩者中的最大的,所以取4條,然後再加上user表中沒有在job表中找到對應關係的記錄(即對應的job表都為null,5-4=1),所以最終結果為4+1=5條
SELECT * FROM USER u LEFT JOIN job j ON u.JOB_ID=j.id;SQL查詢結果:5條記錄
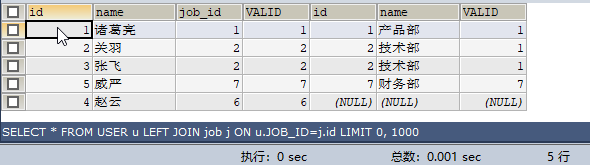
結論:on條件是唯一欄位,則結果集是左表記錄的數量。
b.左連線非唯一欄位
1,2,2,6,7 和 1,1,7,8對比,以user表為主表,因為主表中有2條符合條件的記錄(1,7),而job表有3條符合條件的記錄(1,1,7),取兩者中的最大的,所以取3條,然後在加上user表在job表中沒有匹配的記錄(即對應的job表都為null,為5-2=3),所以最終結果為3+3=6條
SELECT * FROM `user` u LEFT JOIN job j ON u.VALID=j.VALID;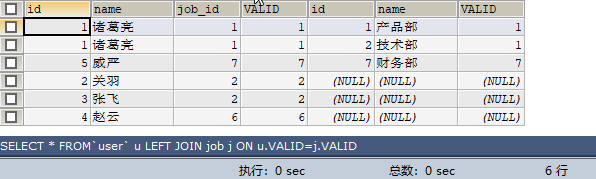
結論:左連線非唯一欄位,是區域性笛卡爾積。
c.當on 條件為假時的內連線:
SELECT * FROM `user` u LEFT JOIN job j ON 0;sql查詢結果:5條
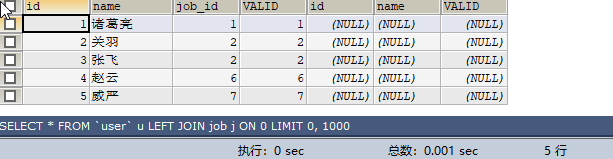
結論:當on條件為假的時候,即user在job表中一條符合記錄的都沒有,那麼即為:user表中的所有記錄條數,所以為5條,job表中的值都為null
(2)右連線
同左連線,這裡就不贅述了
全外連線
mysql不支援
總結:
1.全匹配:
無論哪種查詢,首先計算出on匹配記錄(FROM user INNER JOIN job ON ...或者使用 FROM user,job where...),匹配記錄的查詢結果為:若A表有m條記錄,符合on查詢條件的為m1條,B表有n條記錄,符合on條件的為n1條,那麼匹配記錄為MAX(m1,n1);
2.左連線:
結果集為:MAX(m1,n1)+(m-m1);
如果m1 > n1,則不會產生笛卡爾積,因為無論不匹配的記錄(m-m1),還是匹配的記錄MAX(m1,n1),都是從左表中取記錄,所以不會出現重複的記錄;反之,如果m1 < n1,則可能會產生笛卡爾積,因為MAX(m1,n1)是從右表中取的,所以要看實際情況,不確定一定會有笛卡爾積,但是可能會有
3.有連線
結果集為:MAX(m1,n1)+(n-n1);
如果m1 < n1,則不會產生笛卡爾積,因為無論不匹配的記錄(n-n1),還是匹配的記錄MAX(m1,n1),都是從右表中取記錄,所以不會出現重複的記錄;反之,如果m1 > n1,則可能會產生笛卡爾積,因為MAX(m1,n1)是從左表中取的,所以要看實際情況,不確定一定會有笛卡爾積,但是可能會有