
Redis 基礎特性講解
1.Redis基礎雜項小節
1.是什麼
Redis: Remote Dictionary Server(遠端字典伺服器)
是一個高效能的(key/value) 分散式記憶體資料庫,是當前熱門的NoSql資料庫之一
2.能幹嘛
- 記憶體儲存和持久化
- 模擬類似於HttpSession這種需要設定過期時間的功能
- 釋出、訂閱訊息系統 (橫向對比MQ,有一定差距,畢竟不是專門做訊息系統的中介軟體)
- 定時器、計數器
3.去哪下
redis官網
redis中文網
4.Redis啟動後基礎知識講解
- 單機版預設16個數據庫,叢集環境該配置不生效,只有一個數據庫,預設Select 0;
- Dbsize 檢視當前資料庫的key的數量
- Flushdb 清空當前庫
- Flushall 通殺全部庫
- 埠號預設是6379
- 單程序,單執行緒

2.Redis資料型別
1.常用的五大資料型別
(1). String
String是redis最基本的型別,可以理解成與Memcached一模一樣的型別,一個key對應一個value。
String型別是二進位制安全的。String型別的值最大能儲存512MB

(2). Hash
Redis hash 是一個鍵值(key->value)對集合。
Redis hash 是一個string 型別的 field 和 value的對映表 , hash 特別適合用於儲存物件

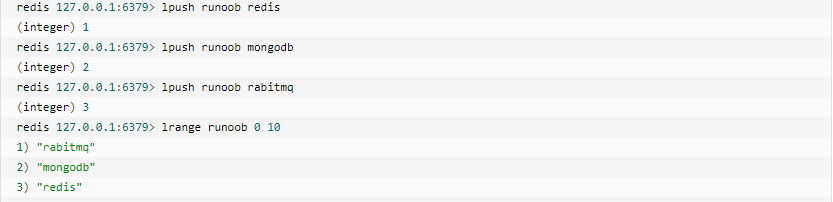
(3). List
Redis列表是簡單的字串列表,按照插入順序排序。你可以新增一個元素到列表的頭部(左邊)或者尾部(右邊)。
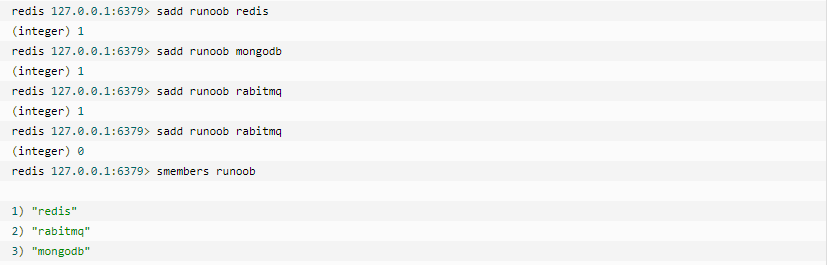
(4).Set
Redis的Set是string型別的無序集合。它是通過雜湊表來實現的。所以新增,刪除,查詢的複雜度都是O(1)
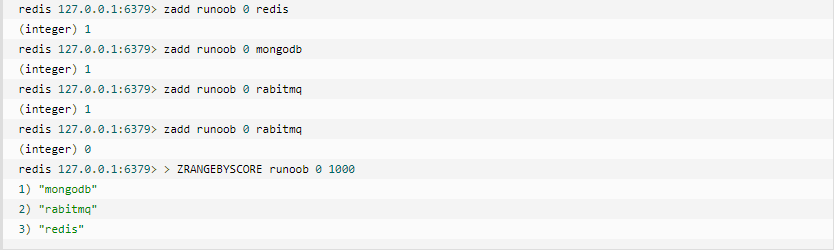
(5).Zset
Redis Zset和Set 一樣也是string型別元素的集合,且不允許重複的成員。
不同的是每個元素都會關聯一個double型別的分數。redis正是通過分數來為集合中的成員進行從小到大排序的。Zset的成員是唯一的,但分數(score)卻可以重複。
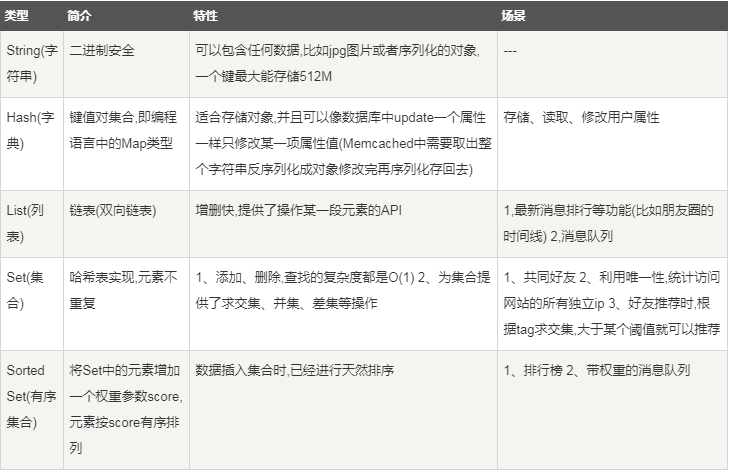
小結
各個資料型別應用場景:
2.高階‘玩家’才知道的其他資料型別
(1).Bitmap
Redis從2.2.0版本開始新增了setbit,getbit,bitcount等幾個bitmap相關命令。雖然是新命令,但是並沒有新增新的資料型別,因為setbit等命令只不過是在set上的擴充套件。在bitmap上可執行AND,OR,XOR以及其它位操作。
(2).HyperLogLog
HyperLogLog 可以接受多個元素作為輸入,並給出輸入元素的基數估算值:
- 基數:集合中不同元素的數量。比如 {'apple', 'banana', 'cherry', 'banana', 'apple'} 的基數就是 3 。
- 估算值:演算法給出的基數並不是精確的,可能會比實際稍微多一些或者稍微少一些,但會控制在合
理的範圍之內。
HyperLogLog 的優點是,即使輸入元素的數量或者體積非常非常大,計算基數所需的空間總是固定的、並且是很小的。
每個 HyperLogLog 鍵只需要花費 12 KB 記憶體,就可以計算接近 2^64 個不同元素的基
數。但是,因為 HyperLogLog 只會根據輸入元素來計算基數,而不會儲存輸入元素本身,所以
HyperLogLog 不能像集合那樣,返回輸入的各個元素。
使用HyperLogLog進行資料統計時,需要考慮三要素:
- 是否需要很少的記憶體去解決問題
- 是否能容忍一定誤差
- 是否需要單挑資料
首先,hyperloglog有一定的錯誤率,在使用hyperloglog進行資料統計的過程中,hyperloglog給出的資料不一定是對的
按照維基百科的說法,使用hyperloglog處理10億條資料,佔用1.5Kb記憶體時,錯誤率為2%其次,沒法從hyperloglog中取出單條資料,這很容易理解,使用16KB的記憶體儲存100萬條資料,此時還想把100萬條資料取出來,顯然是不可能的
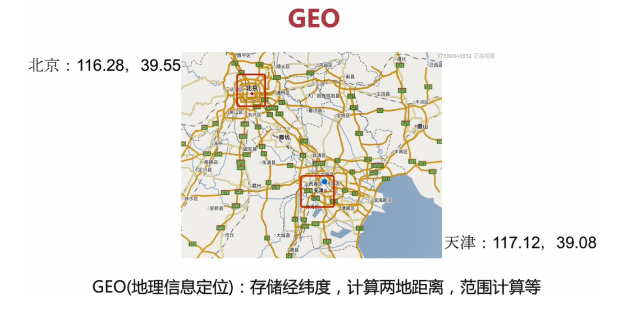
(3).GEO
GEO即地址資訊定位
可以用來儲存經緯度,計算兩地距離,範圍計算等
(4).PipeLine
流水線功能,允許客戶端可以一次傳送多條命令,而不等待上一條命令執行的結果,主要的核心就是降低了多命令互動時網路通訊的時間。
3.Redis的持久化
1. RDB (Redis DataBase)
(1) 是什麼
在指定的時間間隔內將記憶體中的資料集快照寫入磁碟,它恢復時是將快照檔案直接讀到記憶體裡
Redis會單獨建立(fork)一個子程序來進行持久化,會將資料寫入到一個臨時檔案,待持久化過程都結束了,再用這個臨時檔案替換上次持久化好的檔案。整個過程中,主程序是不進行IO操作的,確保了極高的效能。
如果需要進行大規模資料的恢復,且對於資料恢復的完整性不是非常敏感,那麼RDB方式要比AOF方式更加的高效。RDB的缺點是最後一次持久化後的資料可能丟失。
(2) 配置位置 (redis.conf)

RDB 儲存的是 dump.rdb 檔案
(3) 觸發與恢復
觸發:配置、save/bgsave命令、flushall命令
- 配置檔案預設的快照配置
- 手動執行 save 或者 bgsave 命令
- 執行flushall 命令,也會產生dump.rdb檔案,但裡面是空的,無意義
SAVE: save時只管儲存,其他不管,全部阻塞
BGSAVE: redis會在後臺非同步進行快照操作,快照同時可以響應客戶端請求
恢復:將備份檔案 (dump.rdb) 移動到 redis 安裝目錄並啟動服務即可
2. AOF
(1) 是什麼
以日誌的形式來記錄到每個寫操作,將Redis執行過的所有寫指令記錄下來
(2) 配置位置
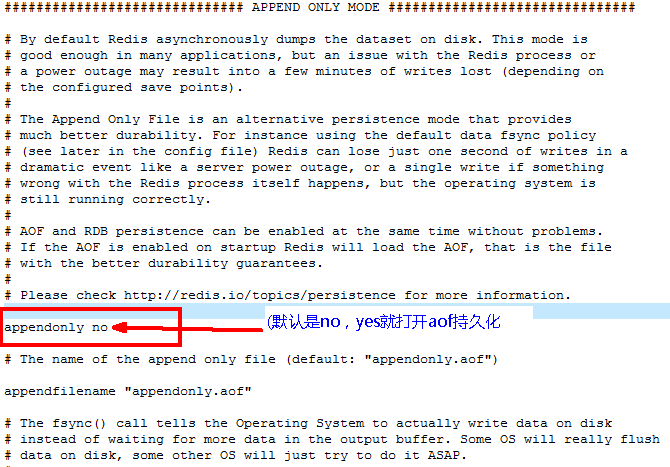
AOF儲存的是 appendonly.aof檔案
(3). AOF啟動/修復/恢復 以及 Rewrite
正常恢復:
啟動: 設定YES,修改預設的 appendonly no,改為yes
將有資料的 aof 檔案複製一份儲存到對應目錄 (config get dir)
恢復:重啟redis然後重新載入
異常恢復:
啟動:設定YES,修改預設的 appendonly no,改為yes
備份被寫壞的AOF檔案
修復:Redis-check-aof --fix 進行修復
恢復:重啟redis然後重新載入
Rewrite:
是什麼: AOF採用檔案追加的方式,檔案會越來越大為避免出現此種情況,新增了重寫機制,當AOF檔案的大小超過設定的閥值時,Redis就會啟動AOF檔案的內容壓縮,只保留可以恢復資料的最小指令集,可以使用命令bgrewriteaof
重寫機制: AOF檔案持續增長而過大時,會fork出一條新程序來將檔案重寫 (也就是先寫臨時檔案最後再rename),遍歷新程序的記憶體中的資料,每條記錄有一條的Set語句。重寫aof檔案的操作,並沒有讀取舊的aof檔案,而是將整個記憶體中的資料庫內容用命令的方式,重寫了一個新的aof檔案,這點和快照類似
觸發機制: Redis會記錄上次重寫時的AOF大小,預設配置是當AOF檔案大小是上次rewrite後大小的一倍且檔案大於64M時觸發
每修改同步:appendfsync always 同步持久化 每次發生資料變更會被立即記錄到磁碟 效能較差
每秒同步:appendfsync everysec 非同步操作,每秒記錄 如果一秒內宕機,有資料丟失
不同步:appendfsync no 從不同步
3.總結
RDB 持久化方式能夠在指定的時間間隔能對你的資料進行快照儲存
AOF持久化方式記錄每次對伺服器寫的操作,當體積過大時會觸發重寫機制
只做快取:當然也可以不使用任何持久化方式
同時開啟兩種持久化的方式:
在這種情況下,當redis重啟的時候會優先載入AOF檔案來恢復原始的資料,因為在通常情況下AOF檔案儲存的資料集要比RDB檔案儲存的資料集要完整.
RDB的資料不實時,同時使用兩者時伺服器重啟也只會找AOF檔案。那要不要只使用AOF呢?作者建議不要,因為RDB更適合用於備份資料庫(AOF在不斷變化不好備份),快速重啟,而且不會有AOF可能潛在的bug,留著作為一個萬一的手段。