
自動化日誌收集及分析在支付寶 App 內的演進
摘要: 作者:曲仁軍(驍然),螞蟻金服技術專家。本文將聚焦支付寶在移動端如何構建日誌自動化採集和分析能力,從而通過“資料採集、計算、分析、決策”完成針對業務效能的監控與使用者行為分析。
背景
結合《螞蟻金服面對億級併發場景的元件體系設計》,我們能夠通盤瞭解支付寶移動端基礎元件體系的構建之路和背後的思考,本文基於服務端組建體系的大背景下,著重探討“自動化日誌手機與分析”在支付寶 App 內的演進之路。
支付寶移動端技術服務框架
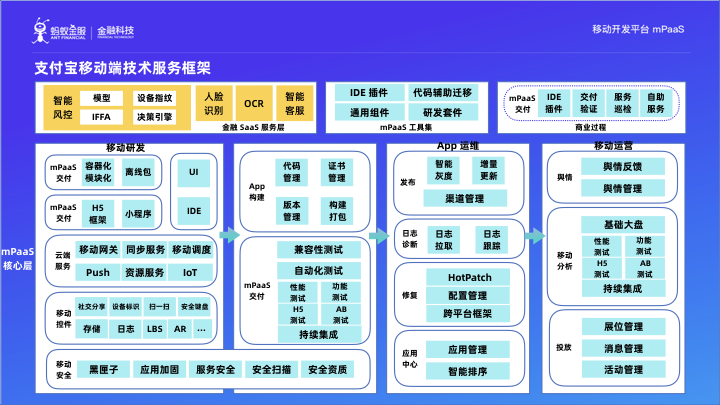
這是整個支付寶移動端無線基礎團隊的技術架構圖,同時螞蟻金服體系內的其他業務 口碑、網商銀行、香港支付寶、天弘基金等) 通過移動開發平臺 mPaaS進行程式碼開發、打包、灰度釋出、上線、問題修復、運營、分析。因此,mPaaS 源自於支付寶移動端的核心技術架構,並在 App 全生命週期的每個環節提供特定的能力支援。接下來,我們將著重分享“日誌診斷
支付寶移動端技術服務框架:資料分析框架
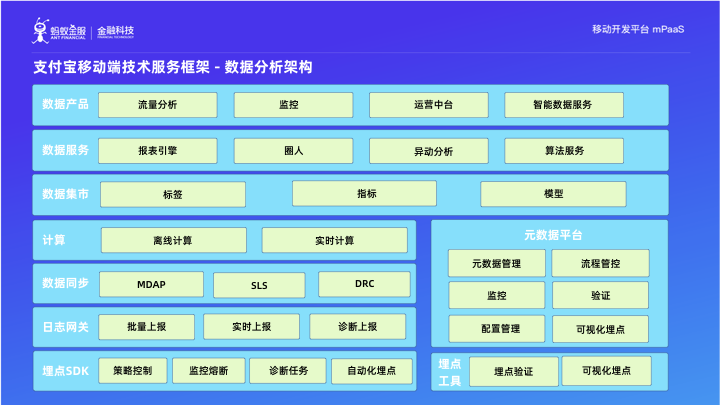
如圖所示,即資料分析能力的技術架構圖,其中“資料同步”、“埋點SDK”、“日誌閘道器”是移動端專屬的能力,其餘部分是所有的資料分析平臺都必須具備的資料結構。
1. 日誌採集
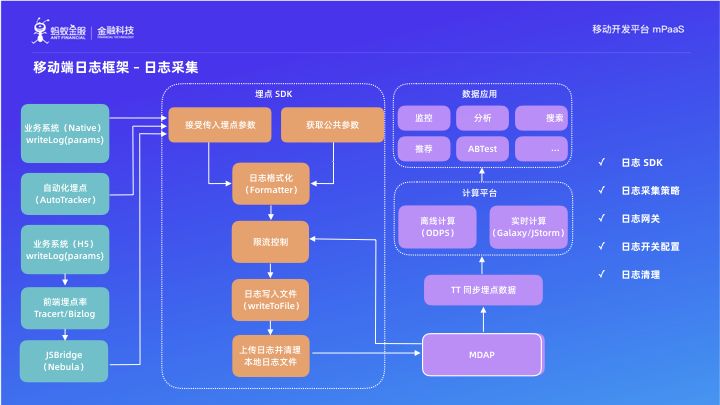
接下來我們重點分析支付寶移動端的日誌採集框架,首先第一部分是“日誌 SDK”,日誌 SDK 會向業務層提供一個埋點介面,使用起來就和 Java 裡面的 logger.info 的感覺一樣:業務層只需要把想記錄的資訊傳遞給日誌 SDK。日誌 SDK 會在拿到業務日誌後,去系統內部獲取相關的系統級別的上下文資訊,比如機型、作業系統版本、App 版本、手機解析度、使用者ID (如果使用者登入了)、裝置ID、上一個頁面、當前頁面等,接著把這些資訊與業務日誌內容整合成一個埋點,然後記錄到裝置的硬碟上。對,只是記錄到硬碟上,並沒有上報到服務端。
日誌 SDK 會在合適的時機,去和日誌閘道器互動,判斷獲取什麼樣的日誌、什麼級別的日誌可以上報。如果可以上報,是以什麼頻率上報、在什麼網路條件下上報。因此通過日誌 SDK 與日誌閘道器的交付,我們可以來實現日誌的策略式降級。日誌的策略式降級這點對於支付寶特別重要,因為目前支付寶的體量,日常的日誌上報量為約 30W 條日誌/s;而在大促的時候,日誌量會是日常的幾十倍! 所以,如果大促期間不採用任何的日誌降級策略的話,我們的頻寬會被日誌打包,支付寶的正常業務功能就不可用了。
由此,我們可以總結,在大促高併發場景下,我們需要只保留關鍵日誌的上傳,其餘日誌統統降級。即使是日常業務處理,我們也只允許日誌在 WIFI 條件下上報,防止發生流量相關的投訴。
埋點閘道器除了提供日誌上報的策略開關能力之外,就是接收客戶端的日誌。它在接受到客戶端日誌之後,會對日誌內容進行校驗,發現無效的日誌會丟棄掉。而對有效合法的埋點,會根據客戶端上報的公網 IP 地址,反解出城市級別的地址位置資訊並新增到埋點中,然後將埋點存放在它自己的硬碟上。
2. 埋點分類

經過多年的實踐,支付寶把日誌埋點分為了四類。
(1)行為埋點:用於監控業務行為,即業務層傳遞的日誌埋點屬於行為埋點,行為埋點屬於“手動埋點”,需要業務層開發同學自己開發。不過也不是全部的業務行為都需要業務方手動開發,有一些具備非常通用性的業務事件,支付寶把它們的埋點記錄放到了框架層,如報活事件、登入事件。因此,行為埋點也可以叫做 "半自動埋點"。
(2)自動化埋點:屬於“全自動化埋點”,用於記錄一些通用的頁面級別、元件級別的行為,比如頁面開啟、頁面關閉、頁面耗時、元件點選等。
(3)效能埋點:屬於“全自動化埋點”,用於記錄 App 的電量使用情況、流量使用、記憶體使用、啟動速度等。
(4)異常埋點:屬於“全自動化埋點”,嚴格上講,也算是效能埋點的一種。但是它記錄的是最關鍵的最直接影響使用者的效能指標,比如 App 的閃退情況、卡死、卡頓情況等。這類埋點,就屬於即時大促期間也不能降級的埋點!
圖中的程式碼示例即為一條行為埋點樣例,大家可以看到,埋點實際上就是一條 CSV 文字。我們可以看到裡面有日誌閘道器新增進行的地址位置資訊內容,也有日誌 SDK 給新增的客戶端裝置資訊。
3. 日誌處理模型
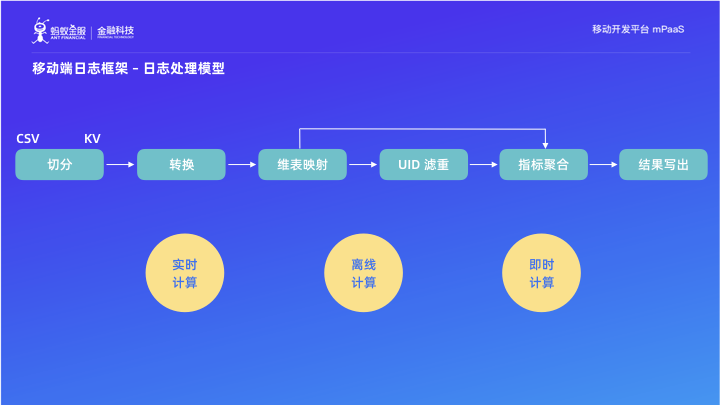
下面我們來整體瞭解支付寶內部日誌處理的通用流程:
(1)日誌切分
我們已經瞭解到,埋點實際上即為一段 CSV 文字。而所謂日誌切分呢,即將 CSV 格式的文字轉成 KV,通俗點說就是記憶體裡面的 HASHMAP。這個切分的過程,可以直接根據逗號進行切換,當然也還有很多其他的辦法。
(2)日誌切換
日誌埋點中的內容,並不是直接可以拿來進行分析的。比如客戶端啟動時間,相關資料是按照毫秒級別的顆粒度進行上報,但實際應用上我們只需要把資料分析到某個特定區間內的個數,所以在處理之前一般會做一個具體啟動時間到截止時間範圍編碼的對映。除了這種轉換之外,還會有一些白名單、黑名單之類的過濾轉換。
(3)維表影射
因為客戶端並不能拿到業務方需要分析的所有資料維度,如使用者的性別、職業等內容,因此在真實分析之前,我們可以通過維表對映,將日誌埋點中的使用者 ID 對映成業務層面的具體屬性來進行後續的分析。
(4)UID 的濾重
UID 濾重的指標有兩種:一種是 PV 指標,一種是 UV 指標。
UV 指標在做具體的計算之前,要做一步 UID 去重。所謂 UID 去重就是指檢查這個 ID 在一定時間範圍內有沒有出現過,如果出現過,那麼這條記錄就必須丟棄了。UV 是有時間週期的概念的,比如日 UV、小時 UV、分鐘 UV、月 UV 等。
(5)指標聚合
在完成了上述的所有過程後,終於要進行指標的計算了。計算的方式包括求和、平均值、最大值、最小值、95 百分位。
(6)結果寫出
就是指把計算的指標的結果輸出到各種儲存或者通過介面傳送給 mPaaS 的客戶。目前我們的計算方式有三大類,實時計算、即時計算和離線計算。下面我會介紹這三種計算方式。
- 實時計算

實時計算模式:接收到日誌後,模型立即開始進行計算,資料結果將在N分鐘(N<=2)內產出,延遲非常的低。
推薦用作實時計算的技術選型包括:1) Flink 2) Spark 3) Storm (阿里做的 JStorm) 4) akka;其中 akka 適合用作業務邏輯較輕的實時監控和報警;關鍵的業務大盤、日誌翻譯回放這些都用 Flink 做比較好。
簡單總結如下:
實時計算的優勢是產出結果速度快、資源消耗少、靈活度中等;
實時計算的劣勢是學習曲線相對陡峭、維護成本較高、配置複雜度高。
- 離線計算

離線計算模式:接收到日誌後,直接儲存下來,不做任何處理。待日誌量積攢一段時間後,模型可進行一次性處理多日或者多月的日誌資料。
推薦用作實時計算的技術選型包括: 1) Flink 2) Spark 3) Hive 4) Hadoop;大家看到了 FLINKSPARK 也出現在了實時模型的推薦技術選擇中。這兩個技術呢,分別從不同的起點出發,達到了相同的終點。
Flink 一開始是隻做實時計算的,後來他開始提供批量離線計算能力;Spark 則正好相反。我們目前呢,還是充分利用每個技術棧的最大優勢,離線還是選擇 Spark,而不是 Flink。在這裡多說兩句,之前有一個經典架構是 “Lambda”模型,是指實時計算的結果要在離線裡面再算一遍,這是因為之前總會出現實時計算丟資料、計算不準的情況,所以實時計算出來的結果只是用來觀察一個趨勢,再等第二天用離線的結果做補充,從而確保業務方能夠看到準確的資料。但是在谷歌的 data-flow 計算模型的論文出來之後,目前市面上的實時計算引擎都具備了 "exactly-once" 的計算能力,換句話說,實時計算不會再出現丟資料以及計算不準的問題了。目前雖然還有“Lambda”模型,即資料會流向實時計算、離線計算兩個引擎,但是離線不再是為實時計算做補充,而是為了充分利用它的效能,計算多日、多月的指標。
簡單總結如下:
離線計算的優勢是 計算效能高、學習難度低;
離線計算的劣勢是 消耗資源大、延遲高、靈活度偏低。
- 即時計算

即時計算模式:接收到日誌後,只做簡單的預處理,比如日誌切分,之後就直接入庫。在需要展示介面的時候,根據使用者配置的過濾和聚合規則即時進行資料處理。
推薦用作即時計算的的技術選型包括: Clickhouse (來自俄羅斯 yandex)、Apache Druid (來自 MetaMarket)、 Pinot (來自 :LinkedIn)。支付寶內部將即時計算模型應用到下鑽分析、漏斗分析這些場景中,有時候也直接把它當做 OLAP 資料庫使用。
簡單總結如下:
即時計算的優勢是超高靈活度、任務維度UV聚合、無限下鑽能力、交付式的查詢延遲(15s內)、學習成本低;
即時計算的劣勢是資源消耗巨大、延遲中等無法用於做實時監控與報警、維度成本高,結構複雜。
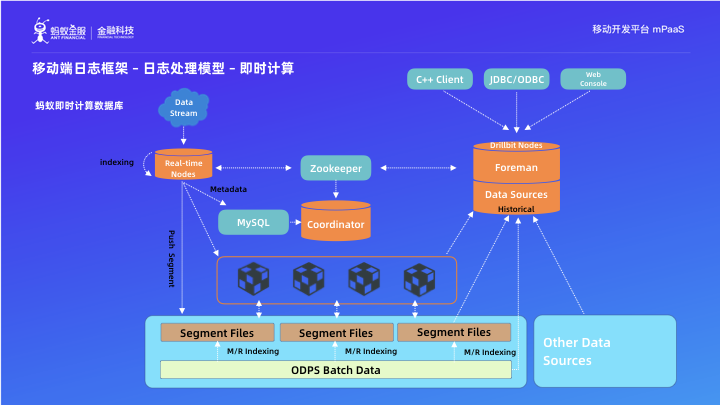
這是目前支付寶內部的一個即時計算框架的技術架構圖。從圖中可以看出來目前即時計算的技術架構包括用來接收資料寫入的實時日誌節點(Read-time Nodes)、用於儲存歷史資料的深度儲存(HDFS、AFS、OSS 等多種型別)、用來對歷史資料(一天以前的資料)提供查詢分析能力的歷史節點(historical)。這個計算框架完全的支援 MySQL 協議,使用者可以直接用 MySQL 客戶端對其進行操作。還有一個重要特性是,他可以對任意的外部資料聯合進行分析。
- 日誌處理模型
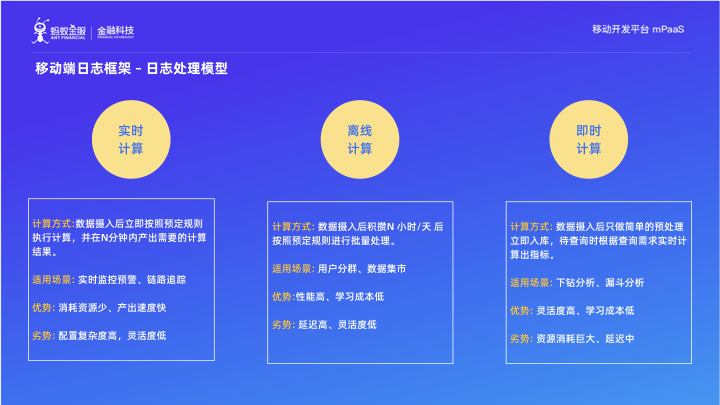
我們再總結一下三種計算模式:
實時計算模型:資料攝入後立即按照預定規則執行計算,並在N分鐘內產出需要的計算結果。
適用場景: 實時監控預警、鏈路追蹤
優勢: 消耗資源少、產出速度快
劣勢: 配置複雜度高,靈活度低
離線計算模型:資料攝入後積攢N 小時/天 後按照預定規則進行批量處理。
適用場景: 使用者分群、資料集市
優勢:效能高、學習成本低
劣勢: 延遲高、靈活度低
即時計算模型:資料攝入後只做簡單的預處理立即入庫,待查詢時根據查詢需求實時計算出指標。
適用場景: 下鑽分析、漏斗分析
優勢: 靈活度高、學習成本低
劣勢: 資源消耗巨大、延遲中
希望大家能夠根據我們的推薦選擇適合的技術棧。
- 動態埋點
說完了我們目前的埋點型別、埋點計算模型,下面來說一下我們目前在內部使用的下一代埋點框架,動態埋點。

我們先針對以上四個問題進行思路串聯,每個問題我也給出了相應的思路和解決辦法。那麼,這些答案是針對以上問題的最優解或者唯一解嗎?很顯然不是,因為這些解法都會帶來開發量。而對於客戶端來說,新的開發量就要釋出版本,同時開發新的埋點,也可能會導致 App 內部的埋點臃腫不堪。

什麼是動態埋點呢?有三個核心概念1) 埋點集、2) 動態埋點上報規則、3) 指標計算動態配置。
有了以上三項能力和配置,我們便可以根據現有的埋點集來配置某個鏈路的監控埋點,並依據這個複雜埋點來定義具體的指標的計算規則,從而做到不用增加開發量,同樣可以快速監控新的指標的效果。不僅如此,我們還能夠讓埋點變成一種通用的資源,讓大家更好地去使用它,而不是無謂地增加埋點,使得程式碼變得更臃腫。

讓我們一起看一下動態埋點框架的一些 UI 交付圖。

相應的,我們再對焦看一下支付寶埋點相關的應用服務:實時日誌拉取。其中,它的主要技術框架包括了 mPaaS 裡面的 MPS (訊息推送)、MSS(資料同步)、以及日誌閘道器。這是因為螞蟻系 App 會與 MPS (安卓系統)、MSS (蘋果系統) 保持長連線,在需要實時拉取日誌的時候,使用者可以在 mPaaS 的控制檯上面通過這兩個渠道下發指令,然後客戶端就會把加密的明細日誌全部上報到日誌閘道器。
這是實時日誌拉取的介面操作展示圖。
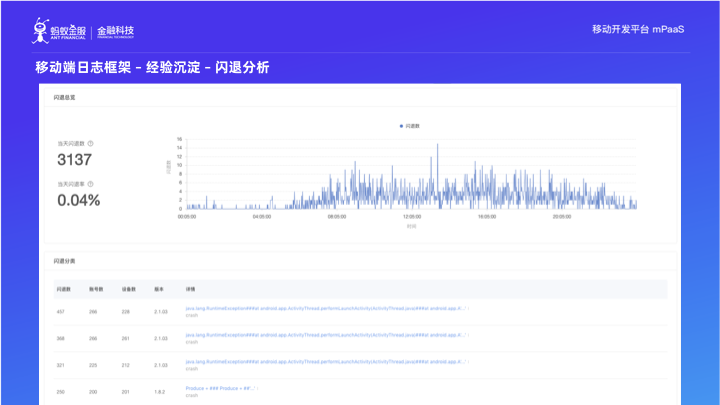
針對於非常重要的效能指標: 閃退、卡頓、卡死, mPaaS 根據多年經驗準備了對應的大盤。如圖所示,上半部分是每分鐘的閃退數,下面是我們根據閃退分類演算法梳理出來的各個閃退分類情況,針對每個分類大盤裡我們還能看到具體的裝置分佈情況。

最後,讓我們從邏輯結構上再梳理一下 mPaaS 的服務端結構。mPaaS 包含五個核心元件:
1) MGS(閘道器服務):將客戶端的請求轉發到業務伺服器.
2) MDS(釋出服務):為客戶端提供多種資源的多種灰度策略釋出能力。
3) MPS & MSS(訊息推送和資料同步服務):以長連線為基礎,來提供資料下發能力。
4) MAS,(分析服務):也是今天講解的重點,以日誌埋點為基礎的分析能力。
如果大家對 mPaaS 的移動分析服務感興趣,歡迎點選文件地址 瞭解更多詳情。
往期閱讀
原文連結
本文為雲棲社群原創內容,未經