
鬥魚 API 閘道器演進之路
2019 年 5 月 11 日,OpenResty 社群聯合又拍雲,舉辦 OpenResty × Open Talk 全國巡迴沙龍武漢站,鬥魚資深工程師張壯壯在活動上做了《 鬥魚 API 閘道器演進之路 》的分享。
OpenResty x Open Talk 全國巡迴沙龍是由 OpenResty 社群、又拍雲發起,邀請業內資深的 OpenResty 技術專家,分享 OpenResty 實戰經驗,增進 OpenResty 使用者的交流與學習,推動 OpenResty 開源專案的發展。活動已先後在深圳、北京、武漢舉辦,後續還將陸續在上海、廣州、杭州等城市巡迴舉辦。

張壯壯,鬥魚資料平臺部資深工程師,負責打點、API 閘道器及後端服務架構建設。
以下是分享全文:
大家下午好,先簡單做下自我介紹,我是來自鬥魚的張壯壯,曾就職於拉勾網和滴滴出行,2017 年 3 月加入鬥魚,主要負責 API 閘道器和資料採集等工作。
今天給大家帶來鬥魚 API 閘道器的一些細節,在分享之前,先感謝剛才的邵海楊老師,因為我們的 API 閘道器基於 Slardar 二次開發的,剛才海楊老師已經詳細介紹了 Slardar 的基礎原理,所以這塊內容我不再重複介紹,直接介紹鬥魚在此基礎上做的更細節的工作。
今天我主要從三個方面來分享:
- 鬥魚使用 API 閘道器的背景
- 閘道器的架構&功能
- 鬥魚 API 閘道器遠期規劃
為什麼是 API 閘道器?
為什麼是 API 閘道器?這要從微服務化遇到的兩個問題說起,第一,怎樣保證服務的無宕機更新部署;第二,怎樣保證服務的自動擴容及故障恢復。這兩個問題,又拍雲已經有了解決方案:只需要在服務之上做服務路由,讓路由支援服務的無宕機更新部署,保證服務的擴容及故障恢復,我們也是按照這個思路來實現的。
但是隻有這個不能解決所有問題,比如服務的效能監控、系統的資源排程等問題,還需要其他基礎設施來支撐。所以 Docker 和 Kubernetes 進入了我們的視野。由於本次活動主題是 OpenResty,對容器技術選型就不做展開了。服務上容器,在更新和遷移中 IP 和 Port 是變化的、不確定的,這是必須要解決的問題。
服務路由
服務路由要支援服務註冊、服務發現和負載均衡。經過多方調研,我們發現又拍雲開源的動態負載均衡元件 Slardar 非常適合業務場景,主要解決了容器環境服務 IP 和 Port 均變化的問題。
- 服務註冊是服務需要主動上報服務相關資訊,最重要的是 IP 和埠;
- 服務發現是把服務註冊的資訊集中起來,最好能持久化;
- 為了避免單點故障,服務會啟動多個例項,因此還需要做負載均衡。
服務發現有很多開源的工具可以用,比如 Consul、etcd 和 Apache Zookeeper。由於我們選型是 K8S,所以服務發現選擇 etcd。
負載均衡,基本上就是三個:LVS、HAProxy 和 Nginx。
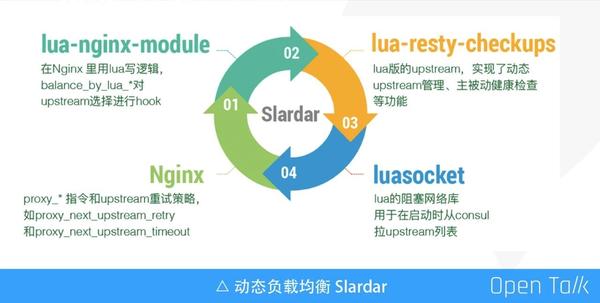
接下來我們簡單瞭解下 Slardar,它由四個部分組成:
- 第一部分是官方的 Nginx,沒有任何改動;
- 第二部分是 Nginx Lua 模組,核心是 Lua 版本的負載均衡演算法+ balance_by_lua
- 第三部分是 lua-resty-checkups,它是把 Nginx upstream 模組常用的功能單獨抽出來,用 lua 重新實現了一遍;
- 第四部分是 luacocket,用於載入配置資訊。
Slardar 在啟動過程中先拉取服務配置,拉取完配置就可以對外進行服務了。如果我們的服務因為擴容或者異常宕機又起了一個新的例項,此時 IP和 Port 都會變化,需要把服務 IP 和 Port 等資訊註冊到 Slardar 和 Consul。邏輯清晰,結構簡單,這是選擇 Slardar 的原因,不過想要真正應用,僅僅有動態負載均衡遠遠不夠,還需要解決以下的問題:
- 服務如何在啟動後自動上報資訊到 Consul;
- Slardar 如何解決自身單點問題;
- 怎樣應對 Consul 叢集故障、或者網路故障;
- 沒有視覺化管理;
- 灰度測試、AB 測試、流量複製等等功能的實現(考慮未來使用場景)。
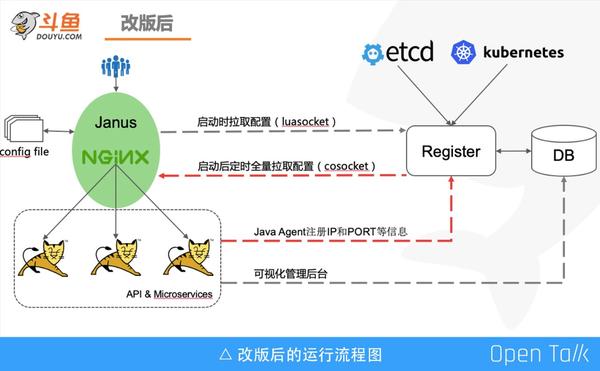
我們拿到了 Slardar 進行了大刀闊斧地調整:
- 取消 Consul,實現註冊中心,並持久化配置到資料庫;
- 開發 Java agent,實現 Java 服務自動上報;
- 對接 Kubernetes API,實現非 Java 服務自動上報;
- 提供視覺化管理後臺;
- 配置定時落盤,當網路故障時作為託底;
- 定時全量拉取配置,增加叢集(機房)概念,可一鍵切換流量;
- 支援叢集部署,應對單點問題;
- upstrem 列表 key 由 Host 改為 Host+URI(字首);
- 引入外掛模式,新增了很多功能,如灰度測試、AB測試、流量複製、服務限流等。
鬥魚 API 閘道器的架構&功能
下面介紹鬥魚的 API 閘道器的部署架構,以及內部功能細節。
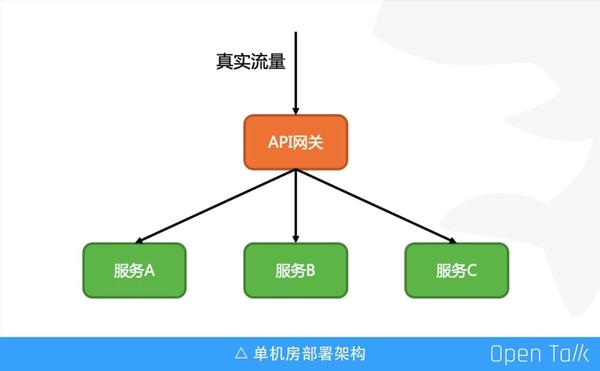
抽象來看,服務接入 API 閘道器的架構非常清晰,和原生 Nginx 架構一樣,所有流量必須經過 API 閘道器後,才能訪問到真實的後端。經服務端處理,並將響應返回給 API 閘道器之後,再交給客戶端。這是單機房的部署架構。實際上使用 Nginx 作為入口閘道器,API 閘道器作為內網閘道器,Nginx 負責處理複雜的 location 邏輯、SSL 認證等,API 閘道器負責抽象後臺服務間通用功能。
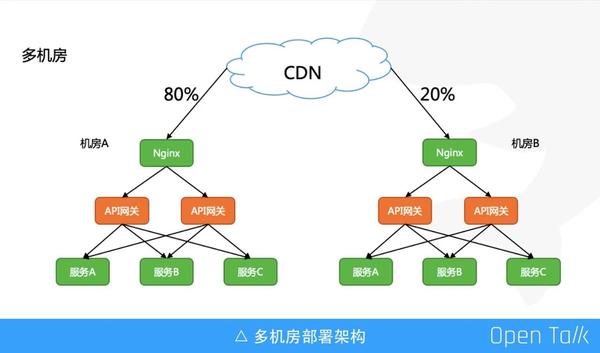
這是多機房部署架構,上游使用 CDN 來做流量分配,方便機房故障時進行一鍵流量切換。
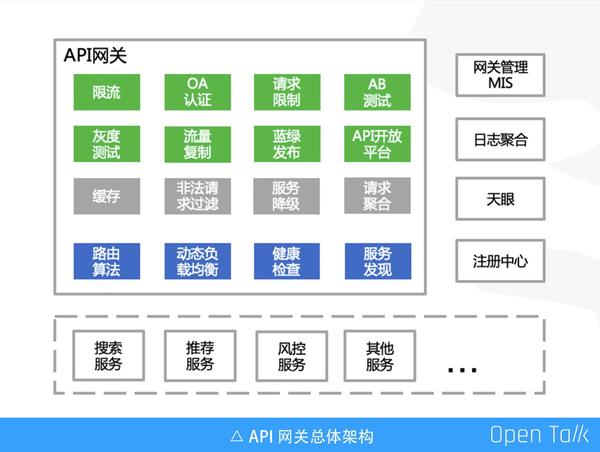
這張圖很好的展示了鬥魚 API 閘道器生態體系。
上圖左側是 API 閘道器的內部功能,綠色部分是已實現的功能,包括限流、OA 認證、請求限制、AB 測試、灰度測試、流量複製、藍綠髮布、API 開放平臺等。灰色部分是即將實現的功能,藍色部分是 Slardar 原生的功能,當然我們也做了大量的優化工作,比如:路由演算法支援動態的權重更新。
上圖右側 API 閘道器的支撐服務,其中閘道器管理 MIS 系統是視覺化管理後臺。日誌聚合提供了接入服務的效能圖表,比如狀態碼 4XX,5XX 統計,以及請求不同水位線耗時分佈,俗稱 P90,P99。天眼是 Java agent,負責實現服務對接下面的註冊中心、實現服務優雅停機。
上圖下側是 API 閘道器代理的服務,如搜尋、推薦、風控、流量分發等等。

以上整個羅列了我們已經實現且線上使用的重要功能。因為時間關係,後面我會挑選其中三個功能詳細介紹實現原理。
OA 認證:為了解決後端服務各自對接 OA 認證繁瑣,比較典型的是內部使用的開源系統,如Kibana、zabbix、Dubbo Admin 等,這些開源元件我們不可能投入人力去二次開發,但是需要接 OA,還需要進行一些 ACL 許可權控制。
QPS 限流:用的是非常簡單的計數器模式,是單機版的,限流是為了保證鬥魚的核心服務,比如視訊拉流,還有剛才提到的推薦、搜尋免受洪峰攻擊。
服務兜底:這個功能想必大家非常瞭解,它能保證上游的資料服務永不消失,它與 QPS 限流其實是結合在一起的,觸發限流的請求會直接返回兜底資料,這可以保證在極端情況下,我們的後端服務不會被瞬時流量打垮,同時保證友好的使用者體驗。典型的場景就是 S 級主播的首秀,例如 3 月份PDD 的首播就給我們帶來了非常大的流量衝擊,通過 QPS 限流保證了我們的核心服務不受影響。
流量複製:在不影響使用者正常請求的前提下,將原始請求複製一份或者多份,供開發人員線上對服務進行功能測試、效能測試和壓力測試。功能上支援自身複製及跨域名複製,流量的放大和縮小。
AB測試、灰度測試和藍綠髮布,可以歸為一類,均是維護多套 upstream 列表,通過某種策略,將不同的請求代理到不同 upstream 。
簽名認證:對外暴露的介面,需要一套簽名演算法,避免服務直接裸露在外,所以這裡面做了一個功能抽象。
服務高可用
我們保證服務高可用其實就是要處理兩個場景:第一個場景是它的更新部署;第二個場景就是執行期間故障。
我們從服務更新部署和服務下線來看考慮第一個場景。
更新部署
想要避免服務更新部署導致請求異常,其實滿足兩個條件即可:
- 第一保證註冊到註冊中心的服務都是已經可以對外提供服務的
- 第二下線之前,先從反向代理列表中剔除
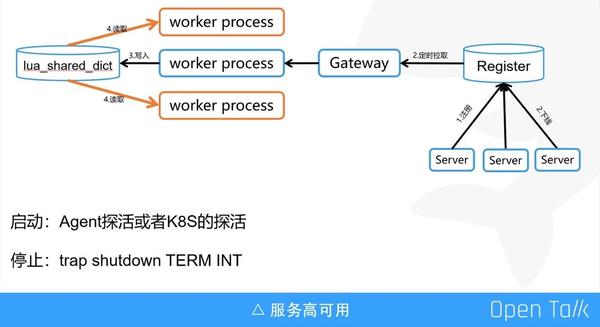
第一個是保證服務註冊到註冊中心的例項,一定是可以對外服務的狀態,即某些服務一定要在啟動完成後才能加入到中心。另一個場景是一些服務需要熱載入,啟動完了後不能立即對外進行服務,這時服務有一個預熱的過程,一定是預熱完了後才能註冊到註冊中心。
第二個是下線時通過 trap 命令,在接收到程式結束(terminate)和程式終止(interrupt)時執行 shutdown 函式,這裡 shutdown 函式會先通知註冊中心下線改例項,然後 hang 住 5-10 秒,等待下線事件更新到閘道器。
這裡特別說明一下服務更新流程,因為 API 閘道器是基於 Nginx 的,所以控制單個 worker 程序全量從註冊中心拉取 upstream 配置資訊,並寫入 lua_shared_dict,其他的 worker 定時同步lua_shared_dict 配置資訊到本地快取。為了反向代理的高效能,閘道器是從本地快取獲取 upstream 資訊,而不是從 lua_shared_dict 。
執行期
接下來我們看執行期故障怎麼處理。
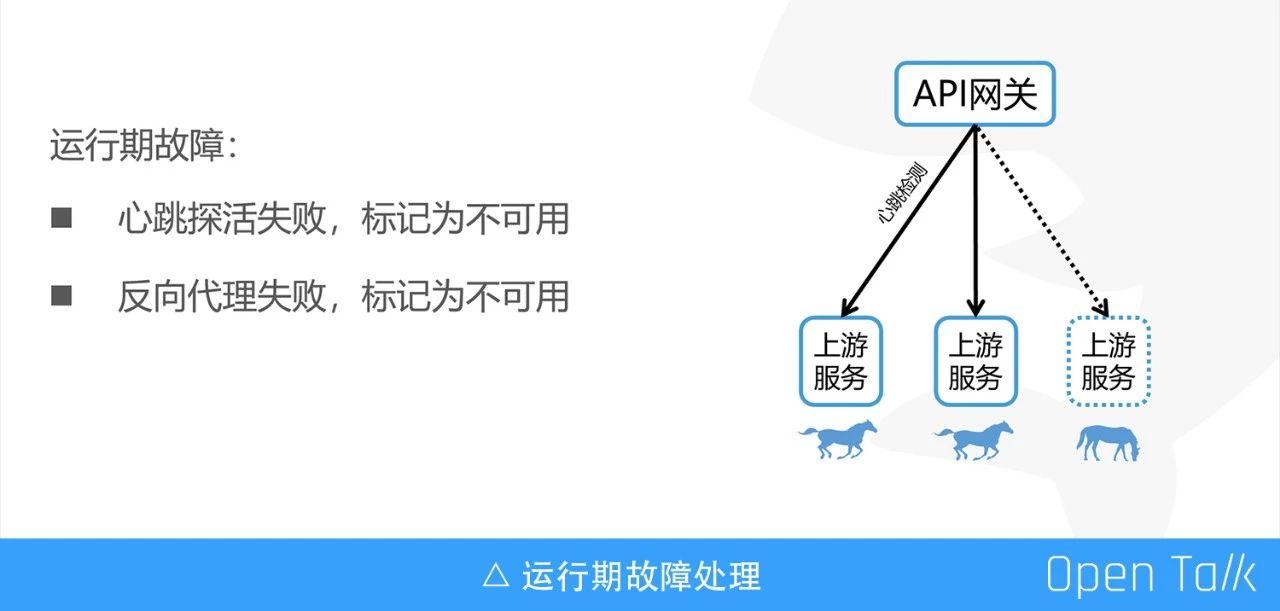
我們是這樣做的:心跳探活+狀態回溯,我們知道只有心跳探活是不能完全保證服務的高可用的,於是加上了“狀態回溯”。
另外說一句:“狀態回溯”是我自己想的,不知道用的對不對,即一次請求過來,如果反向代理失敗,就將該服務標記為不可用。
加上之前啟動和停止的操作,就保證了在任何情況下,正常的釋出或者某臺例項異常故障不會出現服務不可用的瞬間。這裡就解決了之前提到的保證服務的無宕機更新部署和保證服務的自動擴容和故障恢復這兩個問題。
AB 測試
AB 測試我們只是做了一個通用的功能。我們的 AB 測試是基於 Nginx rewrite 命令,主要使用場景有:
- 需測試的 ABCD…策略(或演算法,或模型,或服務)會長期且同時存在於生產環境;
- 不想同時維護多套程式碼分支;
- 客戶端無需改造。
目前閘道器對外提供 AB Test 功能是面向 HTTP 服務的,其實現原理是:後臺服務提供一個預設介面,同時提供多種需要線上驗證的其他介面,請求到達API閘道器,根據命中規則,重定向至對應的介面。其中,源 URI 作為對外暴露的介面,保持固定不變。
AB 測試規則支援白名單、尾數、輪詢策略——一致性雜湊等等。當然,業界還是另外一種實現方式,比如馬蜂窩根據策略訪問不同的 upstream 列表。
服務兜底
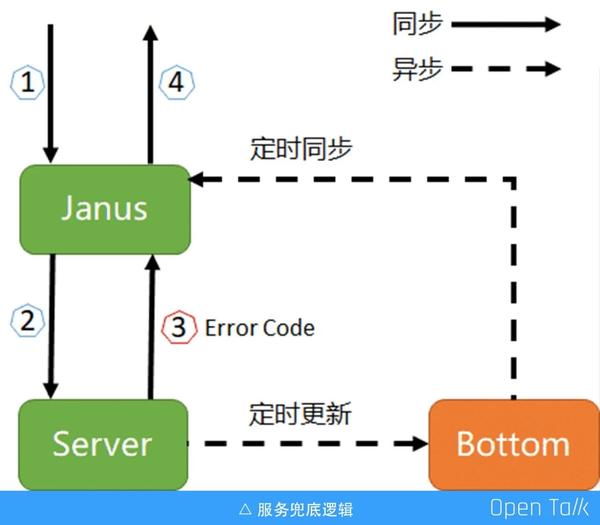
請求到達閘道器之後,會反向代理給後端,如果是錯誤狀態碼,比如 500、502、503,我們直接拿到兜底資料,返回給客戶端就可以了。由於 OpenResty 的限制,無法在 header_filter_by_lua* 和 body_filter_by_lua 中使用發起非阻塞的 HTTP 請求或者其他依賴 TCP 的協議(如 Redis)去查詢兜底資料(原因請點選https://github.com/openresty/lua-Nginx-module),有過 OpenResty 或者 Nginx 模組開發經驗的同學應該都知道:阻塞 API 的使用將會大大的降低 Nginx 的效能。
業界是怎麼處理這個問題的?我見到的有基於 OpenResty 實現的兜底功能,均是使用ngx.location.capture 來主動發起請求給上游服務,而非使用 Nginx 原生的命令 proxy_pass 來實現反向代理。ngx.location.capture 的返回結果包含了響應狀態碼,如果狀態碼屬於 Error Code,則去查詢兜底資料,並返回給 C 端使用者。
--子查詢代理完成請求
local res = ngx.location.capture('/backend' .. request_uri, {
method = method,
always_forward_body = true
})
if 504 == res.status then
return bottom_value
end使用 ngx.location.capture 替換 proxy_pass 的問題在於,HTTP 協議的應用場景非常廣泛,Nginx 實現反向代理時已經做了大量的適配和場景覆蓋,使用 ngx.location.capture 相當於重新 Nginx 的反向代理模組,需要考慮諸如:檔案上傳下載、靜態資源和動態資源、是否傳遞 Cookie 等等場景。任何一個應用場景的遺漏都將是一個線上 BUG。
我們要做服務兜底的時候,閘道器已經上線了一年多,這個時候如果想要重寫,無異於火中取栗。比較幸運的是,在檢視 Nignx 官方文件的時候,發現原生命令 error_page。
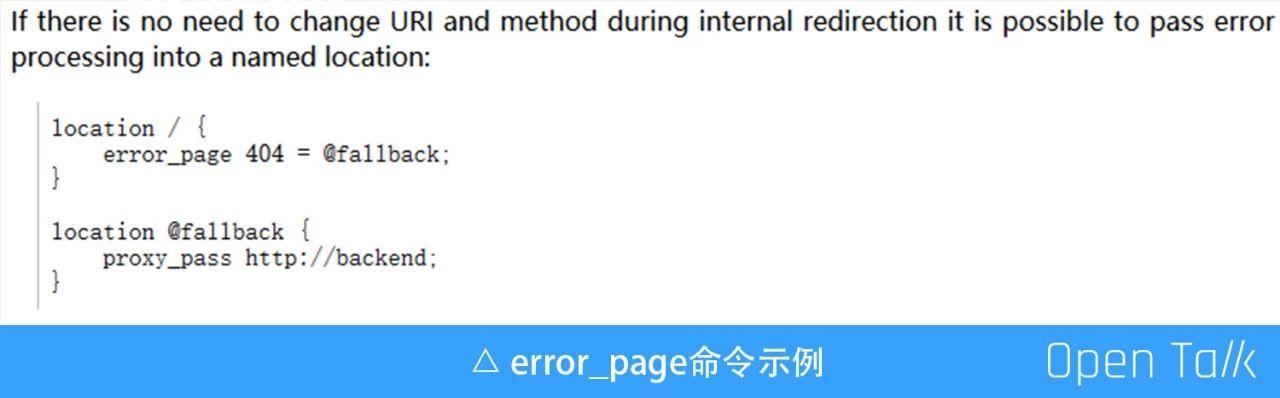
示例中請求 location / 如果上游服務返回 404,則會內部重定向至 @fallback,而 @fallback 介面中可以發起二次 HTTP 請求,例如獲取兜底資料,並且是可以使用非阻塞類庫的。最後實現的核心程式碼如下:
location / {
proxy_pass http://backend;
error_page 500 502 503 504 =200 @janus_bottom;
}
location @janus_bottom {
content_by_lua '
local bottom = require "bottom";
--非阻塞獲取兜底資料,並返回給client
bottom.bottom();
';
}總結一下鬥魚的 API 閘道器,就是執行在所有的 HTTP 服務上,提供通用、可抽象的服務治理功能。
鬥魚 API 閘道器的遠期規劃
2018 年我參加了杭州的 OpenResty 大會,當時受到了很大的啟發。
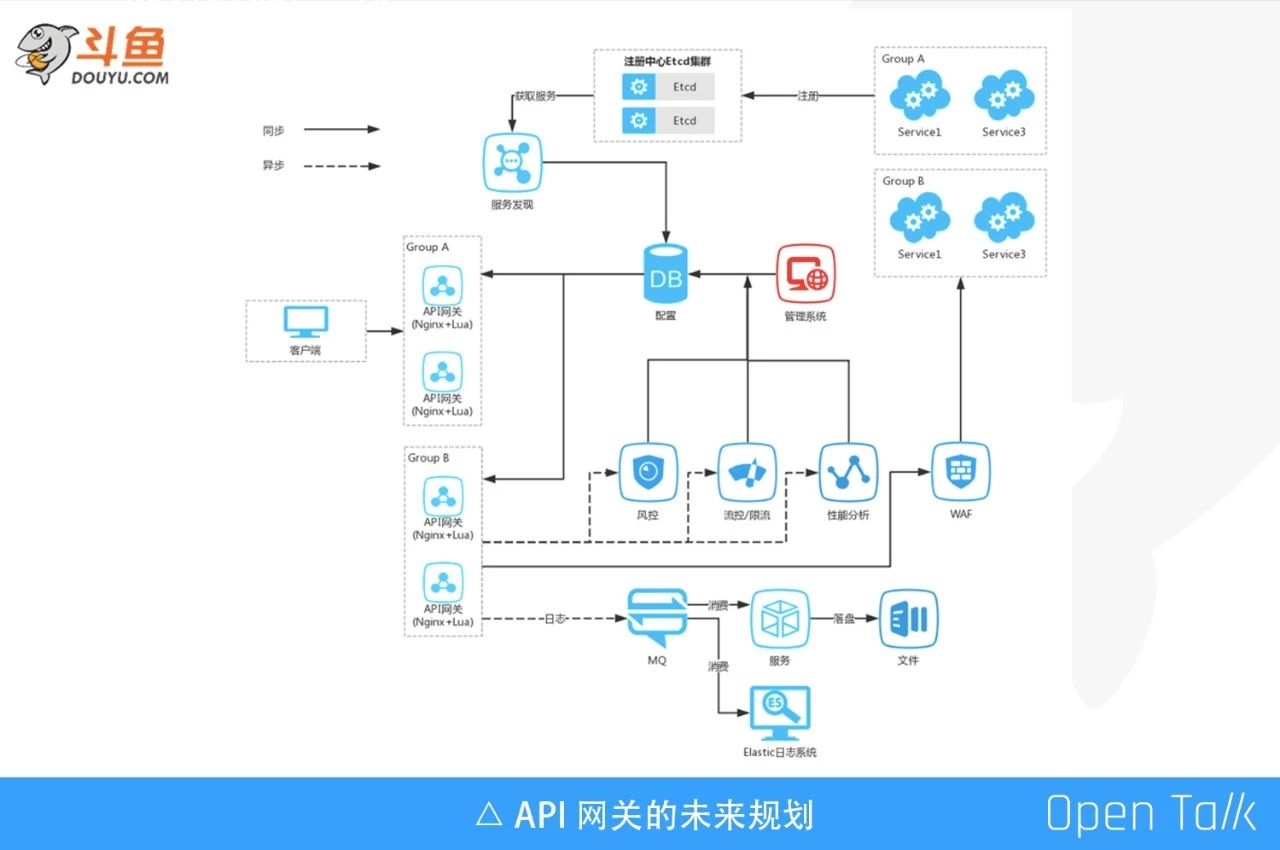
現在 API 閘道器已經全面應用到鬥魚整個後端架構,我們對其做了一些規劃。首先閘道器是分叢集的,由於請求量非常大,磁碟的效能不高,反而會反向影響 API 閘道器吞吐效能。因此我們做了很多優化,比如上 SSD,精簡日誌等,這些功能都已經上線了,日誌精簡完後大概是原來體量的 2/3,效果非常明顯,當然 SSD 才是“銀彈”。
我們後期的一個想法是將閘道器日誌直接寫入 MQ,後續用專門的服務消費 MQ,把日誌落地到本地磁碟。另外一個想法是從 MQ 裡面直接消費到 ES 裡面,做一些其他的分析。
然後,就是將請求分同步和非同步兩條線路。客戶端請求到達 API 閘道器,閘道器會經過如限流,服務兜底,AB測試,灰度測試等功能,這些功能都是在同步的邏輯線路中。顯然,同步邏輯功能越多,勢必會影響客戶端請求 HTTP 的時延。所以我們在 API 閘道器這一塊,將請求日誌放到 MQ,由一些模組直接消費這個 MQ,比如經過風控、流量控制、限流分析,產生一些 API 閘道器可以使用的配置,寫入到 DB 裡。閘道器通過拉取 DB 的配置,對後續的請求做一些限制。我們現在的同步鏈路已經比較完善,下一步重點是非同步鏈路,而且我相信非同步鏈路應該是整個 API 閘道器體系中更加龐大的生態鏈。
觀看視訊和 ppt 下載,請點選:
鬥魚 API 閘道器演進之路 - 又拍雲