
LinkedList 基本示例及原始碼解析
目錄
- 一、JavaDoc 簡介
- 二、LinkedList 繼承介面和實現類介紹
- 三、LinkedList 基本方法介紹
- 四、LinkedList 基本方法使用
- 五、LinkedList 內部結構以及基本元素宣告
- 六、LinkedList 具體原始碼分析
一、JavaDoc 簡介
- LinkedList雙向連結串列,實現了List的 雙向佇列介面,實現了所有list可選擇性操作,允許儲存任何元素(包括null值)
- 所有的操作都可以表現為雙向性的,遍歷的時候會從首部到尾部進行遍歷,直到找到最近的元素位置
- 注意這個實現不是執行緒安全的, 如果多個執行緒併發訪問連結串列,並且至少其中的一個執行緒修改了連結串列的結構,那麼這個連結串列必須進行外部加鎖。(結構化的操作指的是任何新增或者刪除至少一個元素的操作,僅僅對已有元素的值進行修改不是結構化的操作)。
- List list = Collections.synchronizedList(new LinkedList(…)),可以用這種連結串列做同步訪問,但是最好在建立的時間就這樣做,避免意外的非同步對連結串列的訪問
- 迭代器返回的iterators 和 listIterator方法會造成fail-fast機制:如果連結串列在生成迭代器之後被結構化的修改了,除了使用iterator獨有的remove方法外,都會丟擲併發修改的異常。因此,在面對併發修改的時候,這個迭代器能夠快速失敗,從而避免非確定性的問題
二、LinkedList 繼承介面和實現類介紹
java.util.LinkedList 繼承了 AbstractSequentialList 並實現了List , Deque , Cloneable 介面,以及Serializable 介面
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}類之間的繼承體系如下:
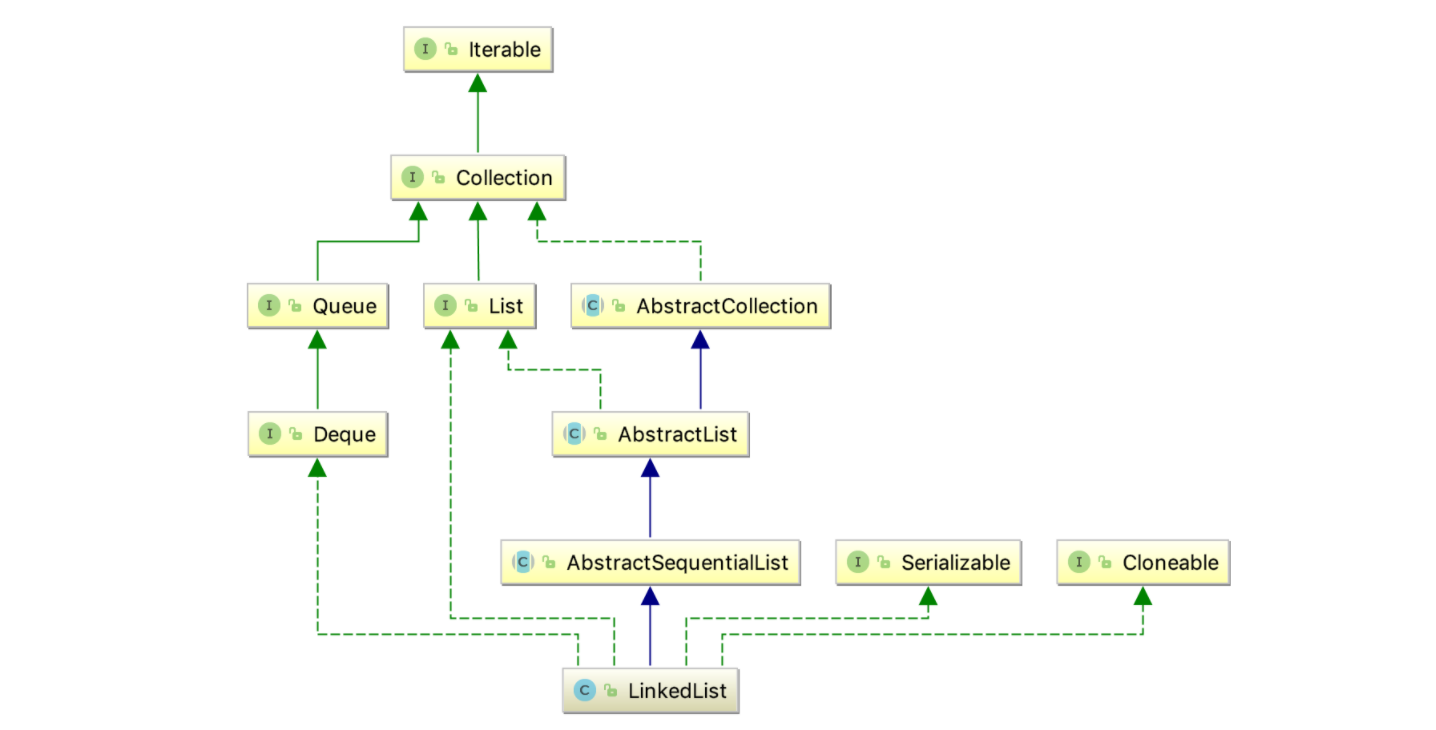
下面就對繼承樹中的部分節點進行大致介紹:
AbstractSequentialList 介紹:
這個介面是List一系列子類介面的核心介面,以求最大限度的減少實現此介面的工作量,由順序訪問資料儲存(例如連結連結串列)支援。對於隨機訪問的資料(像是陣列),AbstractList 應該優先被使用這個介面可以說是與AbstractList類相反的,它實現了隨機訪問方法,提供了get(int index),set(int index,E element), add(int index,E element) and remove(int index)方法對於程式設計師來說:
要實現一個列表,程式設計師只需要擴充套件這個類並且提供listIterator 和 size方法即可。
對於不可修改的列表來說, 程式設計師需要實現列表迭代器的 hasNext(), next(), hasPrevious(),
previous 和 index 方法
AbstractList 介紹:
這個介面也是List繼承類層次的核心介面,以求最大限度的減少實現此介面的工作量,由順序訪問
資料儲存(例如連結連結串列)支援。對於順序訪問的資料(像是連結串列),AbstractSequentialList 應該優先被使用,
如果需要實現不可修改的list,程式設計師需要擴充套件這個類,list需要實現get(int) 方法和List.size()方法
如果需要實現可修改的list,程式設計師必須額外重寫set(int,Object) set(int,E)方法(否則會丟擲
UnsupportedOperationException的異常),如果list是可變大小的,程式設計師必須額外重寫add(int,Object) , add(int, E) and remove(int) 方法
AbstractCollection 介紹:
這個介面是Collection介面的一個核心實現,儘量減少實現此介面所需的工作量
為了實現不可修改的collection,程式設計師應該繼承這個類並提供呢iterator和size 方法
為了實現可修改的collection,程式團需要額外重寫類的add方法,iterator方法返回的Iterator迭代器也必須實現remove方法
三、LinkedList 基本方法介紹
上面看完了LinkedList 的繼承體系之後,來看看LinkedList的基本方法說明
新增
add():
----> 1. add(E e) : 直接在'末尾'處新增元素
----> 2. add(int index,E element) : 在'指定索引處添'加元素
----> 3. addAll(Collections<? extends E> c) : 在'末尾'處新增一個collection集合
----> 4. addAll(int index,Collections<? extends E> c):在'指定位置'新增一個collection集合
----> 5. addFirst(E e): 在'頭部'新增指定元素
----> 6. addLast(E e): 在'尾部'新增指定元素
offer():
----> 1. offer(E e): 在連結串列'末尾'新增元素
----> 2. offerFirst(E e): 在'連結串列頭'新增指定元素
----> 3. offerLast(E e): 在'連結串列尾'新增指定元素
push(E e): 在'頭部'壓入元素
移除
poll():
----> 1. poll(): 訪問並移除'首部'元素
----> 2. pollFirst(): 訪問並移除'首部'元素
----> 3. pollLast(): 訪問並移除'尾部'元素
pop(): 從列表代表的堆疊中彈出元素,從'頭部'彈出
remove():
----> 1. remove(): 移除並返回'首部'元素
----> 2. remove(int index) : 移除'指定索引'處的元素
----> 3. remove(Object o): 移除指定元素
----> 4. removeFirst(): 移除並返回'第一個'元素
----> 5. removeFirstOccurrence(Object o): 從頭到尾遍歷,移除'第一次'出現的元素
----> 6. removeLast(): 移除並返回'最後一個'元素
----> 7. removeLastOccurrence(Object o): 從頭到尾遍歷,移除'最後一次'出現的元素
clear(): 清空所有元素
訪問
peek():
----> 1. peek(): 只訪問,不移除'首部'元素
----> 2. peekFirst(): 只訪問,不移除'首部'元素,如果連結串列不包含任何元素,則返回null
----> 3. peekLast(): 只訪問,不移除'尾部'元素,如果連結串列不包含任何元素,返回null
element(): 只訪問,不移除'頭部'元素
get():
----> 1. get(int index): 返回'指定索引'處的元素
----> 2. getFirst(): 返回'第一個'元素
----> 3. getLast(): 返回'最後一個'元素
indexOf(Object o): 檢索某個元素'第一次'出現所在的位置
LastIndexOf(Object o): 檢索某個元素'最後一次'出現的位置
其他
clone() : 返回一個連結串列的拷貝,返回值為Object 型別
contains(Object o): 判斷連結串列是否包含某個元素
descendingIterator(): 返回一個迭代器,裡面的元素是倒敘返回的
listIterator(int index) : 在指定索引處建立一個'雙向遍歷迭代器'
set(int index, E element): 替換某個位置處的元素
size() : 返回連結串列的長度
spliterator(): 建立一個後期繫結並快速失敗的元素
toArray(): 將連結串列轉變為陣列返回
四、LinkedList 基本方法使用
學以致用,熟悉了上面基本方法之後,來簡單做一個demo測試一下上面的方法:
/**
* 此方法描述
* LinedList 集合的基本使用
*/
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("111");
list.add("222");
list.add("333");
list.add(1,"123");
// 分別在頭部和尾部新增元素
list.addFirst("top");
list.addLast("bottom");
System.out.println(list);
// 陣列克隆
Object listClone = list.clone();
System.out.println(listClone);
// 建立一個首尾互換的迭代器
Iterator<String> it = list.descendingIterator();
while (it.hasNext()){
System.out.print(it.next() + " ");
}
System.out.println();
list.clear();
System.out.println("list.contains('111') ? " + list.contains("111"));
Collection<String> collec = Arrays.asList("123","213","321");
list.addAll(collec);
System.out.println(list);
System.out.println("list.element = " + list.element());
System.out.println("list.get(2) = " + list.get(2));
System.out.println("list.getFirst() = " + list.getFirst());
System.out.println("list.getLast() = " + list.getLast());
// 檢索指定元素出現的位置
System.out.println("list.indexOf(213) = " + list.indexOf("213"));
list.add("123");
System.out.println("list.lastIndexOf(123) = " + list.lastIndexOf("123"));
// 在首部和尾部新增元素
list.offerFirst("first");
list.offerLast("999");
System.out.println("list = " + list);
list.offer("last");
// 只訪問,不移除指定元素
System.out.println("list.peek() = " + list.peek());
System.out.println("list.peekFirst() = " + list.peekFirst());
System.out.println("list.peekLast() = " + list.peekLast());
// 訪問並移除元素
System.out.println("list.poll() = " + list.poll());
System.out.println("list.pollFirst() = " + list.pollFirst());
System.out.println("list.pollLast() = " + list.pollLast());
System.out.println("list = " + list);
// 從首部彈出元素
list.pop();
// 壓入元素
list.push("123");
System.out.println("list.size() = " + list.size());
System.out.println("list = " + list);
// remove操作
System.out.println(list.remove());
System.out.println(list.remove(1));
System.out.println(list.remove("999"));
System.out.println(list.removeFirst());
System.out.println("list = " + list);
list.addAll(collec);
list.addFirst("123");
list.addLast("123");
System.out.println("list = " + list);
list.removeFirstOccurrence("123");
list.removeLastOccurrence("123");
list.removeLast();
System.out.println("list = " + list);
list.addFirst("top");
list.addLast("bottom");
list.set(2,"321");
System.out.println("list = " + list);
System.out.println("--------------------------");
// 建立一個list的雙向連結串列
ListIterator<String> listIterator = list.listIterator();
while(listIterator.hasNext()){
// 移到list的末端
System.out.println(listIterator.next());
}
System.out.println("--------------------------");
while (listIterator.hasPrevious()){
// 移到list的首端
System.out.println(listIterator.previous());
}
}
}Console:
-------1------- [top, 111, 123, 222, 333, bottom]
-------2-------[top, 111, 123, 222, 333, bottom]
bottom 333 222 123 111 top
list.contains('111') ? false
[123, 213, 321]
list.element = 123
list.get(2) = 321
list.getFirst() = 123
list.getLast() = 321
list.indexOf(213) = 1
list.lastIndexOf(123) = 3
-------4------- [first, 123, 213, 321, 123, 999]
list.peek() = first
list.peekFirst() = first
list.peekLast() = last
list.poll() = first
list.pollFirst() = 123
list.pollLast() = last
-------5------- [213, 321, 123, 999]
list.size() = 4
-------6------- [123, 321, 123, 999]
123
123
true
321
-------7------- []
-------8------- [123, 123, 213, 321, 123]
list = [123, 213]
-------9------- [top, 123, 321, bottom]
--------------------------
top
123
321
bottom
--------------------------
bottom
321
123
top五、LinkedList 內部結構以及基本元素宣告
- LinkedList內部結構是一個雙向連結串列,具體示意圖如下
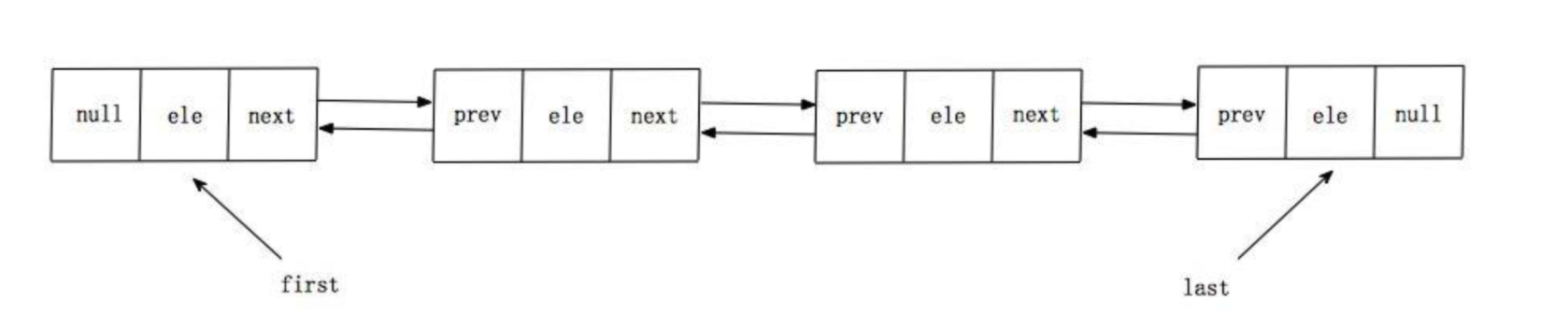
每一個連結串列都是一個Node節點,由三個元素組成
private static class Node<E> {
// Node節點的元素
E item;
// 指向下一個元素
Node<E> next;
// 指向上一個元素
Node<E> prev;
// 節點建構函式
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}first 節點也是頭節點, last節點也是尾節點
- LinkedList 中有三個元素,分別是
transient int size = 0; // 連結串列的容量
transient Node<E> first; // 指向第一個節點
transient Node<E> last; // 指向最後一個節點- LinkedList 有兩個建構函式,一個是空建構函式,不新增任何元素,一種是建立的時候就接收一個Collection集合。
/**
* 空建構函式
*/
public LinkedList() {}
/**
* 建立一個包含指定元素的建構函式
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}六、LinkedList 具體原始碼分析
前言: 此原始碼是作者根據上面的程式碼示例一步一步跟進去的,如果有哪些疑問或者講的不正確的地方,請與作者聯絡。
新增
新增的具體流程示意圖:
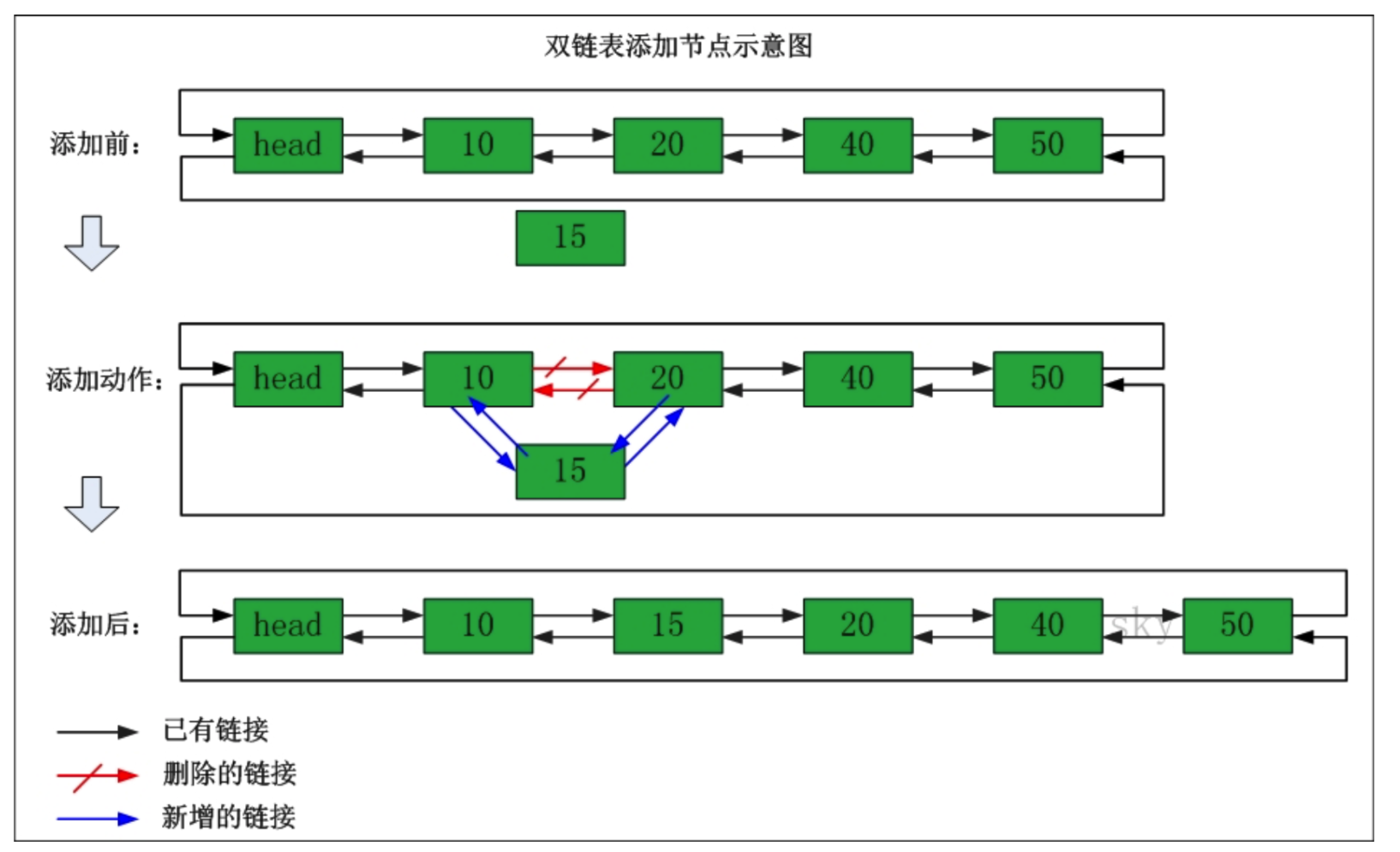
包括方法有:
add(E e)
add(int index, E element)
addAll(Collection<? extends E> c)
addAll(int index, Collection<? extends E> c)
addFirst(E e)
addLast(E e)
offer(E e)
offerFirst(E e)
offerLast(E e)
下面對這些方法逐個分析其原始碼:
add(E e) :
// 新增指定元素至list末尾
public boolean add(E e) {
linkLast(e);
return true;
}
// 真正新增節點的操作
void linkLast(E e) {
final Node<E> l = last;
// 生成一個Node節點
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
// 如果l = null,代表的是第一個節點,所以這個節點即是頭節點
// 又是尾節點
if (l == null)
first = newNode;
else
// 如果不是的話,那麼就讓該節點的next 指向新的節點
l.next = newNode;
size++;
modCount++;
}
- 比如第一次新增的是111,此時連結串列中還沒有節點,所以此時的尾節點last 為null, 生成新的節點,所以 此時的尾節點也就是111,所以這個 111 也是頭節點,再進行擴容,修改次數對應增加
- 第二次新增的是 222, 此時連結串列中已經有了一個節點,新新增的節點會新增到尾部,剛剛新增的111 就當作頭節點來使用,222被新增到111的節點後面。
add(int index,E e) :
/**
*在指定位置插入指定的元素
*/
public void add(int index, E element) {
// 下標檢查
checkPositionIndex(index);
if (index == size)
// 如果需要插入的位置和連結串列的長度相同,就在連結串列的最後新增
linkLast(element);
else
// 否則就連結在此位置的前面
linkBefore(element, node(index));
}
// 越界檢查
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 判斷引數是否是有效位置(對於迭代或者新增操作來說)
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
// linkLast 上面已經介紹過
// 查詢索引所在的節點
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 在非空節點插入元素
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// succ 即是插入位置的節點
// 查詢該位置處的前面一個節點
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
- 例如在位置為1處新增值為123 的元素,首先對下標進行越界檢查,判斷這個位置是否等於連結串列的長度,如果與連結串列長度相同,就往最後插入,如果不同的話,就在索引的前面插入。
- 下標為1 處並不等於索引的長度,所以在索引前面插入,首先對查詢 1 這個位置的節點是哪個,並獲取這個節點的前面一個節點,在判斷這個位置的前一個節點是否為null,如果是null,那麼這個此處位置的元素就被當作頭節點,如果不是的話,頭節點的next 節點就指向123
addFirst(E e) :
// 在頭節點插入元素
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
// 先找到first 節點
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
// f 為null,也就代表著沒有頭節點
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}例如要新增top 元素至連結串列的首部,需要先找到first節點,如果first節點為null,也就說明沒有頭節點,如果不為null,則頭節點的prev節點是新插入的節點。
addLast(E e) :
public void addLast(E e) {
linkLast(e);
}
// 連結末尾處的節點
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
方法邏輯與在頭節點插入基本相同
addAll(Collections<? extends E> c) :
/**
* 在連結串列中批量新增資料
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 越界檢查
checkPositionIndex(index);
// 把集合轉換為陣列
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
// 直接在末尾新增,所以index = size
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
// 遍歷每個陣列
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
// 先對應生成節點,再進行節點的連結
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}Collection<String> collec = Arrays.asList("123","213","321"); list.addAll(collec);
- 例如要插入一個Collection為123,213,321 的集合,沒有指定插入元素的位置,預設是向連結串列的尾部進行連結,首先會進行陣列越界檢查,然後會把集合轉換為陣列,在判斷陣列的大小是否為0,為0返回,不為0,繼續下面操作
- 因為是直接向鏈尾插入,所以index = size,然後遍歷每個陣列,首先生成對應的節點,在對節點進行連結,因為succ 是null,此時last 節點 = pred,這個時候的pred節點就是遍歷陣列完成後的最後一個節點
- 然後再擴容陣列,增加修改次數
addAll(Collections<? extends E> c) : 這個方法的原始碼同上
offer也是對元素進行新增操作,原始碼和add方法相同
offerFirst(E e)和addFirst(E e) 原始碼相同
offerLast(E e)和addLast(E e) 原始碼相同)
push(E e) 和addFirst(E e) 原始碼相同
取出元素
包括方法有:
- peek()
- peekFirst()
- peekLast()
- element()
- get(int index)
- getFirst()
- getLast()
- indexOf(Object o)
- lastIndexOf(Object o)
peek()
/**
* 只是訪問,但是不移除連結串列的頭元素
*/
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
peek() 原始碼比較簡單,直接找到連結串列的第一個節點,判斷是否為null,如果為null,返回null,否則返回鏈首的元素
peekFirst() : 原始碼和peek() 相同
peekLast():
/**
* 訪問,但是不移除連結串列中的最後一個元素
* 或者返回null如果連結串列是空連結串列
*/
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}原始碼也比較好理解
element() :
/**
* 只是訪問,但是不移除連結串列的第一個元素
*/
public E element() {
return getFirst();
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}與peek()相同的地方都是訪問連結串列的第一個元素,不同是element元素在連結串列為null的時候會報空指標異常
****get(int index) :
/*
* 返回連結串列中指定位置的元素
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 返回指定索引下的元素的非空節點
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}get(int index)原始碼也是比較好理解,首先對下標進行越界檢查,沒有越界的話直接找到索引位置對應的node節點,進行返回
getFirst() :原始碼和element()相同
getLast(): 直接找到最後一個元素進行返回,和getFist幾乎相同
indexOf(Object o) :
/*
* 返回第一次出現指定元素的位置,或者-1如果不包含指定元素。
*/
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}兩種情況:
- 如果需要檢索的元素是null,對元素連結串列進行遍歷,返回x的元素為空的位置
- 如果需要檢索的元素不是null,對元素的連結串列遍歷,直到找到相同的元素,返回元素下標
lastIndexOf(Object o) :
/*
* 返回最後一次出現指定元素的位置,或者-1如果不包含指定元素。
*/
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}從IndexOf(Object o)原始碼反向理解
刪除
刪除節點的示意圖如下:
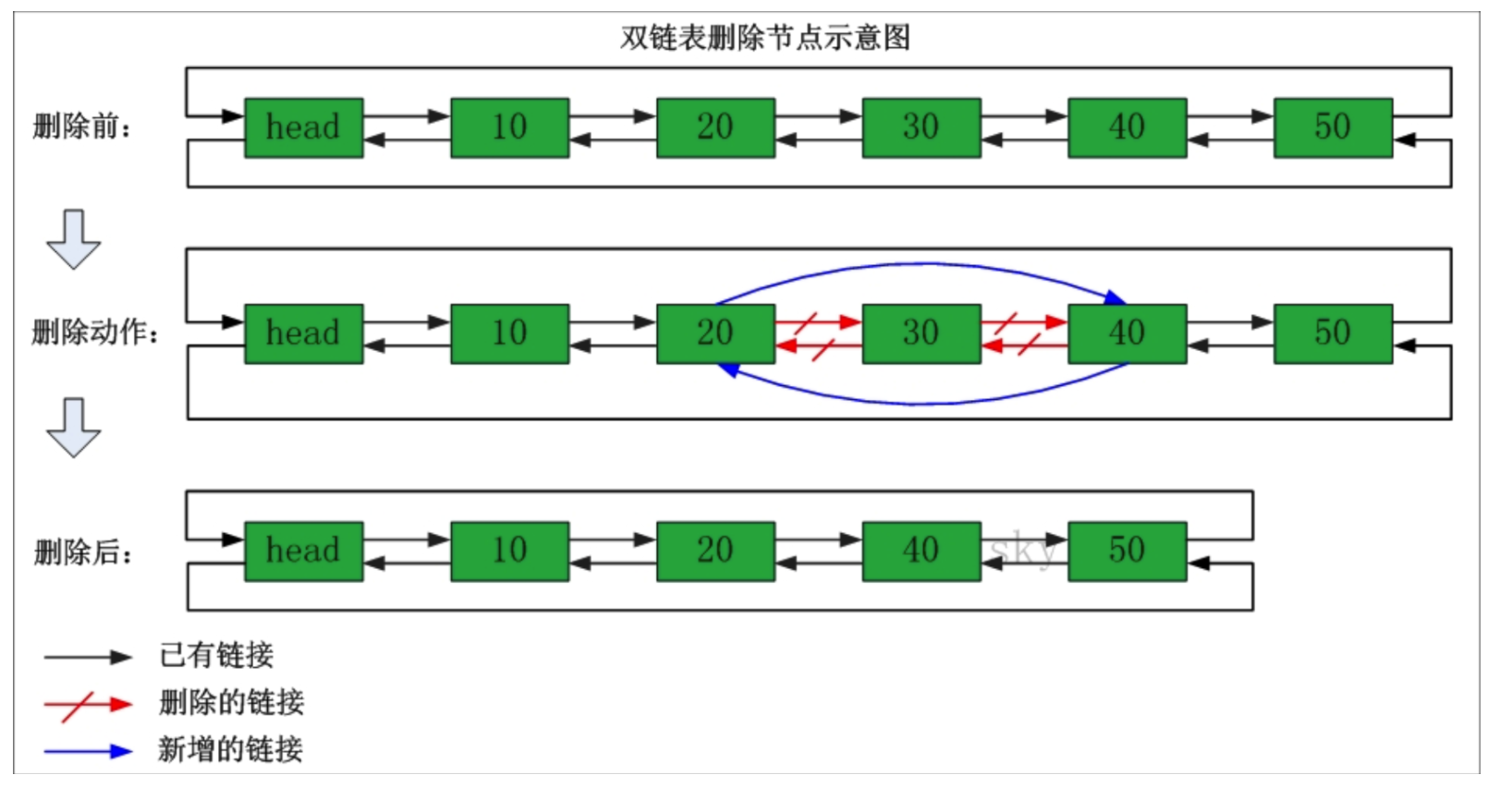
包括的方法有:
- poll()
- pollFirst()
- pollLast()
- pop()
- remove()
- remove(int index)
- remove(Object o)
- removeFirst()
- removeFirstOccurrence(Object o)
- removeLast()
- removeLastOccurrence(Object o)
- clear()
poll() :
/*
* 訪問並移除連結串列中指定元素
*/
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
// 斷開第一個非空節點
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}poll()方法也比較簡單直接,首先通過Node方法找到第一個連結串列頭,然後把連結串列的元素和連結串列頭指向的next元素置空,再把next節點的元素變為頭節點的元素
pollFirst() : 與poll() 原始碼相同
pollLast(): 與poll() 原始碼很相似,不再解釋
pop()
/*
* 彈出連結串列的指定元素,換句話說,移除並返回連結串列中第一個元素
*/
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// unlinkFirst 原始碼上面