
05、_redis replication的完整流執行程和原理的再次深入剖析
1、複製的完整流程
(1)slave node啟動,僅僅儲存master node的資訊,包括master node的host和ip,但是複製流程沒開始
master host和ip是從哪兒來的,redis.conf裡面的slaveof配置的
(2)slave node內部有個定時任務,每秒檢查是否有新的master node要連線和複製,如果發現,就跟master node建立socket網路連線
(3)slave node傳送ping命令給master node
(4)口令認證,如果master設定了requirepass,那麼salve node必須傳送masterauth的口令過去進行認證
(5)master node第一次執行全量複製,將所有資料發給slave node
(6)master node後續持續將寫命令,非同步複製給slave node
2、資料同步相關的核心機制
指的就是第一次slave連線msater的時候,執行的全量複製,那個過程裡面你的一些細節的機制
(1)master和slave都會維護一個offset
master會在自身不斷累加offset,slave也會在自身不斷累加offset
slave每秒都會上報自己的offset給master,同時master也會儲存每個slave的offset
這個倒不是說特定就用在全量複製的,主要是master和slave都要知道各自的資料的offset,才能知道互相之間的資料不一致的情況
(2)backlog
master node有一個backlog,預設是1MB大小
master node給slave node複製資料時,也會將資料在backlog中同步寫一份
backlog主要是用來做全量複製中斷候的增量複製的
(3)
master run id
info server,可以看到master run id
如果根據host+ip定位master node,是不靠譜的,如果master node重啟或者資料出現了變化,那麼slave node應該根據不同的run id區分,run id不同就做全量複製
如果需要不更改run id重啟redis,可以使用redis-cli debug reload命令
(4)psync
從節點使用psync從master node進行復制,psync runid offset
master node會根據自身的情況返回響應資訊,可能是FULLRESYNC runid offset觸發全量複製,可能是CONTINUE觸發增量複製
3、全量複製
(1)master執行bgsave,在本地生成一份rdb快照檔案
(2)master node將rdb快照檔案傳送給salve node,如果rdb複製時間超過60秒(repl-timeout),那麼slave node就會認為複製失敗,可以適當調節大這個引數
(3)對於千兆網絡卡的機器,一般每秒傳輸100MB,6G檔案,很可能超過60s
(4)master node在生成rdb時,會將所有新的寫命令快取在記憶體中,在salve node儲存了rdb之後,再將新的寫命令複製給salve node
(5)client-output-buffer-limit slave 256MB 64MB 60,如果在複製期間,記憶體緩衝區持續消耗超過64MB,或者一次性超過256MB,那麼停止複製,複製失敗
(6)slave node接收到rdb之後,清空自己的舊資料,然後重新載入rdb到自己的記憶體中,同時基於舊的資料版本對外提供服務
(7)如果slave node開啟了AOF,那麼會立即執行BGREWRITEAOF,重寫AOF
rdb生成、rdb通過網路拷貝、slave舊資料的清理、slave aof rewrite,很耗費時間
如果複製的資料量在4G~6G之間,那麼很可能全量複製時間消耗到1分半到2分鐘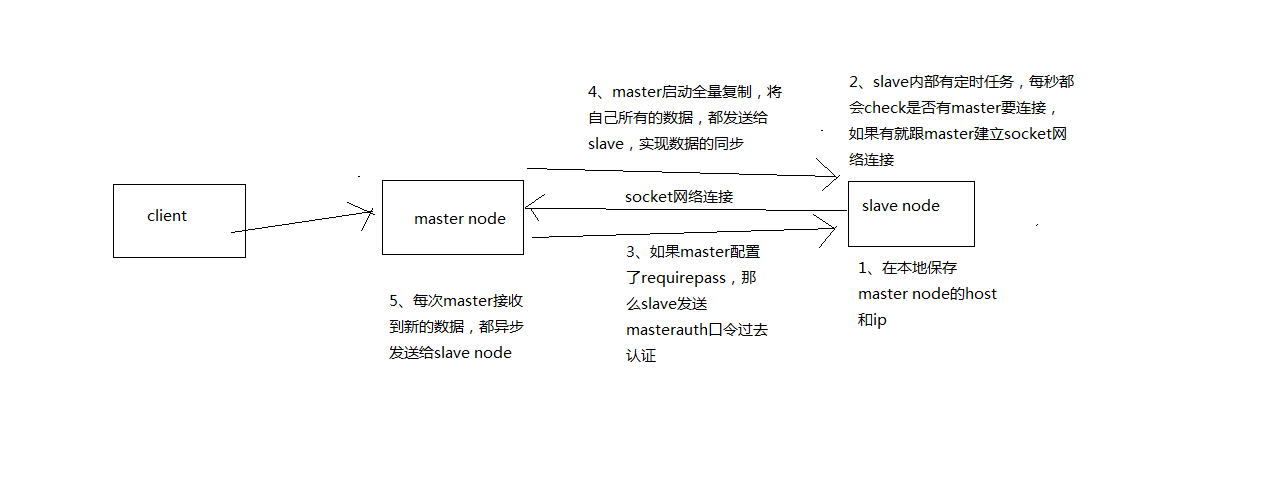
4、增量複製
(1)如果全量複製過程中,master-slave網路連線斷掉,那麼salve重新連線master時,會觸發增量複製
(2)master直接從自己的backlog中獲取部分丟失的資料,傳送給slave node,預設backlog就是1MB
(3)msater就是根據slave傳送的psync中的offset來從backlog中獲取資料的
5、heartbeat
主從節點互相都會發送heartbeat資訊
master預設每隔10秒傳送一次heartbeat,salve node每隔1秒傳送一個heartbeat
6、非同步複製
master每次接收到寫命令之後,現在內部寫入資料,然後非同步傳送給