
Java獲取檔案編碼
阿新 • • 發佈:2019-06-01
在不告知檔案編碼的情況下,通過一定的手段去探測檔案的編碼,幾乎沒有任何一種方法是絕對正確的。只有成功率大小的問題。一下列出幾個常用的識別檔案編碼的方法。
常見的編碼檔案的開頭來識別檔案編碼:
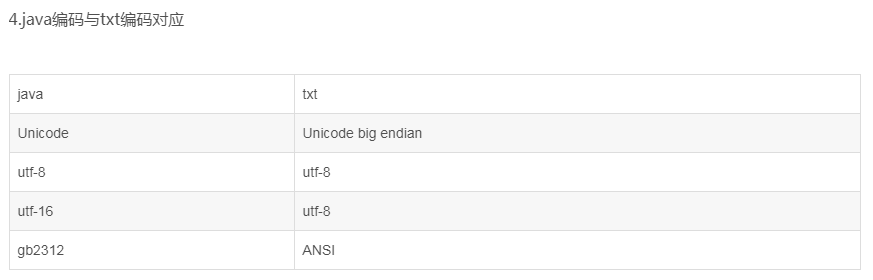
ANSI: 無格式定義
Unicode: 前兩個位元組為FFFE Unicode文件以0xFFFE開頭
Unicode big endian: 前兩位元組為FEFF
UTF-8: 前兩位元組為EFBB UTF-8以0xEFBBBF開頭
1、通過檔案的前三個位元組來判斷
public static String codeString(String fileName) throws Exception { BufferedInputStream bin = new BufferedInputStream(new FileInputStream(fileName)); int p = (bin.read() << 8) + bin.read(); bin.close(); String code = null; switch (p) { case 0xefbb: code = "UTF-8"; break; case 0xfffe: code = "Unicode"; break; case 0xfeff: code = "UTF-16BE"; break; default: code = "GBK"; } return code; }
2、判斷前三個位元組出錯率還是蠻大的,還可以進一步讀取檔案的欄位,進行特殊編碼字元的判斷來確定檔案編碼
/** * 判斷文字檔案的字符集,檔案開頭三個位元組表明編碼格式。 * <a href="http://blog.163.com/wf_shunqiziran/blog/static/176307209201258102217810/">參考的部落格地址</a> * * @param path * @return * @throws Exception * @throws Exception */ public static String charset(String path) { String charset = "GBK"; byte[] first3Bytes = new byte[3]; try { boolean checked = false; BufferedInputStream bis = new BufferedInputStream(new FileInputStream(path)); bis.mark(0); // 讀者注: bis.mark(0);修改為 bis.mark(100);我用過這段程式碼,需要修改上面標出的地方。 // Wagsn注:不過暫時使用正常,遂不改之 int read = bis.read(first3Bytes, 0, 3); if (read == -1) { bis.close(); return charset; // 檔案編碼為 ANSI } else if (first3Bytes[0] == (byte) 0xFF && first3Bytes[1] == (byte) 0xFE) { charset = "UTF-16LE"; // 檔案編碼為 Unicode checked = true; } else if (first3Bytes[0] == (byte) 0xFE && first3Bytes[1] == (byte) 0xFF) { charset = "UTF-16BE"; // 檔案編碼為 Unicode big endian checked = true; } else if (first3Bytes[0] == (byte) 0xEF && first3Bytes[1] == (byte) 0xBB && first3Bytes[2] == (byte) 0xBF) { charset = "UTF-8"; // 檔案編碼為 UTF-8 checked = true; } bis.reset(); if (!checked) { while ((read = bis.read()) != -1) { if (read >= 0xF0) break; if (0x80 <= read && read <= 0xBF) // 單獨出現BF以下的,也算是GBK break; if (0xC0 <= read && read <= 0xDF) { read = bis.read(); if (0x80 <= read && read <= 0xBF) // 雙位元組 (0xC0 - 0xDF) // (0x80 - 0xBF),也可能在GB編碼內 continue; else break; } else if (0xE0 <= read && read <= 0xEF) { // 也有可能出錯,但是機率較小 read = bis.read(); if (0x80 <= read && read <= 0xBF) { read = bis.read(); if (0x80 <= read && read <= 0xBF) { charset = "UTF-8"; break; } else break; } else break; } } } bis.close(); } catch (Exception e) { e.printStackTrace(); } System.out.println("--檔案-> [" + path + "] 採用的字符集為: [" + charset + "]"); return charset; }
3、通過工具庫cpdetector來獲取檔案編碼
/**
* <div>
* 利用第三方開源包cpdetector獲取檔案編碼格式.<br/>
* --1、cpDetector內建了一些常用的探測實現類,這些探測實現類的例項可以通過add方法加進來,
* 如:ParsingDetector、 JChardetFacade、ASCIIDetector、UnicodeDetector. <br/>
* --2、detector按照“誰最先返回非空的探測結果,就以該結果為準”的原則. <br/>
* --3、cpDetector是基於統計學原理的,不保證完全正確.<br/>
* </div>
* @param filePath
* @return 返回檔案編碼型別:GBK、UTF-8、UTF-16BE、ISO_8859_1
* @throws Exception
*/
public static String getFileCharset(String filePath) throws Exception {
CodepageDetectorProxy detector = CodepageDetectorProxy.getInstance();
/*ParsingDetector可用於檢查HTML、XML等檔案或字元流的編碼,
* 構造方法中的引數用於指示是否顯示探測過程的詳細資訊,為false不顯示。
*/
detector.add(new ParsingDetector(false));
/*JChardetFacade封裝了由Mozilla組織提供的JChardet,它可以完成大多數檔案的編碼測定。
* 所以,一般有了這個探測器就可滿足大多數專案的要求,如果你還不放心,可以再多加幾個探測器,
* 比如下面的ASCIIDetector、UnicodeDetector等。
*/
detector.add(JChardetFacade.getInstance());
detector.add(ASCIIDetector.getInstance());
detector.add(UnicodeDetector.getInstance());
Charset charset = null;
File file = new File(filePath);
try {
//charset = detector.detectCodepage(file.toURI().toURL());
InputStream is = new BufferedInputStream(new FileInputStream(filePath));
charset = detector.detectCodepage(is, 8);
} catch (Exception e) {
e.printStackTrace();
throw e;
}
String charsetName = "GBK";
if (charset != null) {
if (charset.name().equals("US-ASCII")) {
charsetName = "ISO_8859_1";
} else if (charset.name().startsWith("UTF")) {
charsetName = charset.name();// 例如:UTF-8,UTF-16BE.
}
}
return charsetName;
}