
【nodejs原理&原始碼賞析(4)】深度剖析cluster模組原始碼與node.js多程序(上)
目錄
- 一. 概述
- 二. 執行緒與程序
- 三. cluster模組原始碼解析
- 3.1 起步
- 3.2 入口
- 3.3 主程序模組master.js
- 3.4 子程序模組child.js
- 四. 小結

示例程式碼託管在:http://www.github.com/dashnowords/blogs
部落格園地址:《大史住在大前端》原創博文目錄
華為雲社群地址:【你要的前端打怪升級指南】
一. 概述
cluster
node.js中用於實現和管理多程序的模組。常規的node.js應用程式是單執行緒單程序的,這也意味著它很難充分利用伺服器多核CPU的效能,而cluster模組就是為了解決這個 問題的,它使得node.js程式可以以多個例項並存的方式執行在不同的程序中,以求更大地榨取伺服器的效能。node.js在官方示例程式碼中使用worker例項來表示主程序fork出的子程序,使得前端開發者在學習過程中非常容易和瀏覽器環境中的worker實現的多執行緒混淆。為了容易區分,我們和node官方文件使用一致的名稱,用叢集中的master和worker來區分主程序和工作程序,用worker_threads來描述工作執行緒。node.js的主從模型中,master主程序相當於一個包工頭,主管監聽埠,而slave程序被用於實際的任務執行,當任務請求到達後,它會根據某種方式將連線迴圈分發給worker程序來處理。理論上,如果根據當前各個worker程序的負載狀況或者相關資訊來挑選工作程序,效率應該比直接迴圈發放要更高,但node.js文件中宣告這種方式由於受到作業系統排程機制的影響,會使得分發變得不穩定,所以會將"迴圈法"作為預設的分發策略。
關於cluster模組的用法和API細節,可以直接參考官方文件《Node.js中文網V10.15.3/cluster》。
二. 執行緒與程序
想要儘可能利用伺服器效能,首先需要了解“執行緒”(thread)和“程序”(process)這兩個概念。
計算機是由CPU來執行計算任務的,如果你只有一個CPU,那麼這臺機器上所有的任務都將由它來執行。它既可以按照串聯執行的原則一個接一個執行任務,也可以依據並聯原則同步執行多個任務,多個任務同步執行時,CPU會快速在多個執行緒之間進行切換,切換執行緒的同時要切換對應任務的上下文,這就會造成額外的CPU資源消耗,所以當執行緒數量非常多時,執行緒切換本身就會浪費大量的CPU資源。如果在執行一個任務的同時,CPU和記憶體都還有充足的剩餘,就可以通過某種方式讓它們去執行其他任務。
你可以將“執行緒”看作是一種輕量級的“程序”。
如果你在作業系統中開啟工作管理員,在程序標籤下就可以看到如下圖的示例:
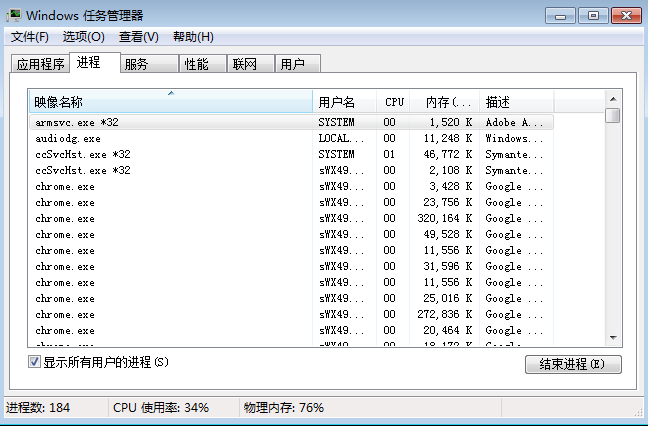
我們可以看到每一個程式至少開闢一個新的程序(你可能瞬間就明白了chrome效率高的原因,我什麼都沒說),它是一種粒度更大的資源隔離單元,程序之間使用不同的記憶體區域,無法直接共享資料,只能通過跨程序通訊機制來通訊,而且由於要使用新的記憶體區域,它的建立銷燬和切換相對而言都更耗時,它的好處就是程序之間是互相隔離的,互不影響,所以你可以一邊聽音樂一邊玩遊戲,而不會因為音樂軟體裡突然放了一首輕音樂,結果你遊戲裡的角色攻擊力減半了。
再來看一下效能這個標籤:
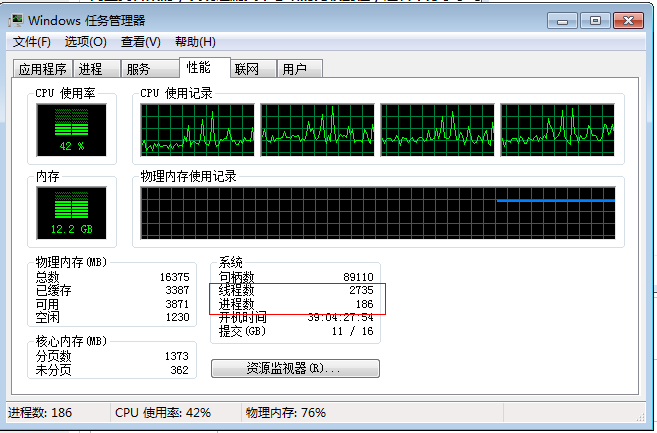
可以看到執行緒數是遠大於程序數的。“執行緒”通常用來在單個“程序”中提高CPU的利用率,它是一種粒度更細的資源排程單位,它更容易建立和銷燬,在同一個程序內的執行緒共享分配給這個程序的記憶體,所以也就實現了共享資料,多執行緒的程式設計要更加複雜,由於共享資料,如果執行緒之間傳遞指標然後操作同一資料來源,就必須考慮“原子操作”和“鎖”的問題,否則很容易就亂套了,如果傳遞資料的拷貝,又會造成記憶體浪費,另外執行緒異常不會被隔離,而會導致整個程序異常。
執行緒和程序的相關知識涉及到底層作業系統的內容,筆者涉獵有限,先分享這麼多(會的都告訴你了,還要我怎樣)。
三. cluster模組原始碼解析
原始碼中個別方法比較長,建議使用帶有程式碼摺疊的工具來看。
3.1 起步
cluster模組的用法看起來並不複雜,官方給出的示例是這樣的:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`主程序 ${process.pid} 正在執行`);
// 衍生工作程序。
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作程序 ${worker.process.pid} 已退出`);
});
} else {
// 工作程序可以共享任何 TCP 連線。
// 在本例子中,共享的是 HTTP 伺服器。
http.createServer((req, res) => {
res.writeHead(200);
res.end('你好世界\n');
}).listen(8000);
console.log(`工作程序 ${process.pid} 已啟動`);
}3.2 入口
cluster模組的入口在/lib/cluster.js,這裡的程式碼很簡單:
'use strict';
const childOrMaster = 'NODE_UNIQUE_ID' in process.env ? 'child' : 'master';
module.exports = require(`internal/cluster/${childOrMaster}`);可以看到,如果程序物件的環境變數中有NODE_UNIQUE_ID這個變數,就透傳internal/cluster/child.js模組的輸出,否則就透傳internal/cluster/master.js模組的輸出。這是node的主程序在進行子程序管理時的標識,後面的程式碼中可以看到當呼叫cluster.fork( )生成一個子程序時會以一個自增ID的形式生成這個環境變數。
3.3 主程序模組master.js
首先執行node程式的肯定是主執行緒,那麼我們從master.js這個模組開始,先用工具摺疊一下程式碼瀏覽一下:
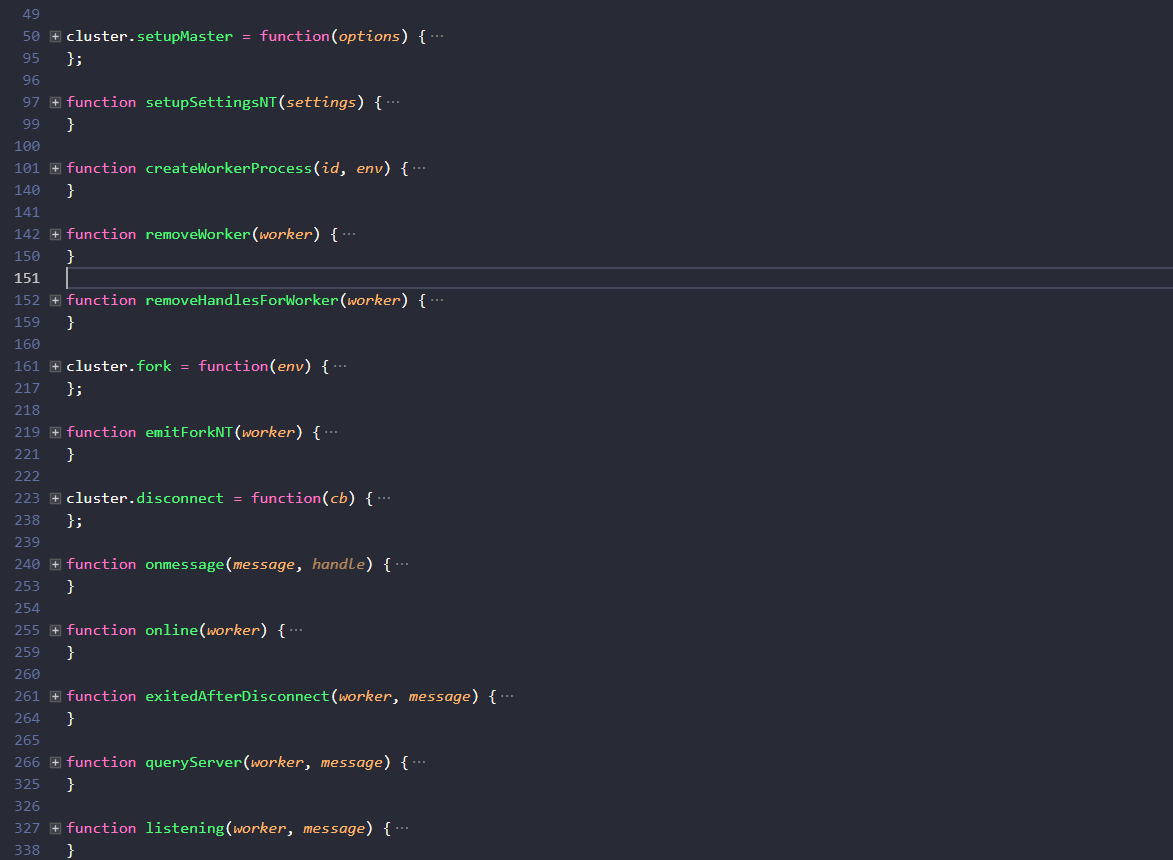
可以看到除了模組屬性外,cluster模組對外暴露的方法只有下面3個,其他的都是用來完成內部功能的:
setupMaster(options )-修改fork時預設設定fork( )-生成子程序disconnect( )- 斷開和所有子程序的連線
我們按照官方示例的邏輯路線來閱讀程式碼cluster.fork( )方法定義在161-217行,一樣是用摺疊工具來看全貌:
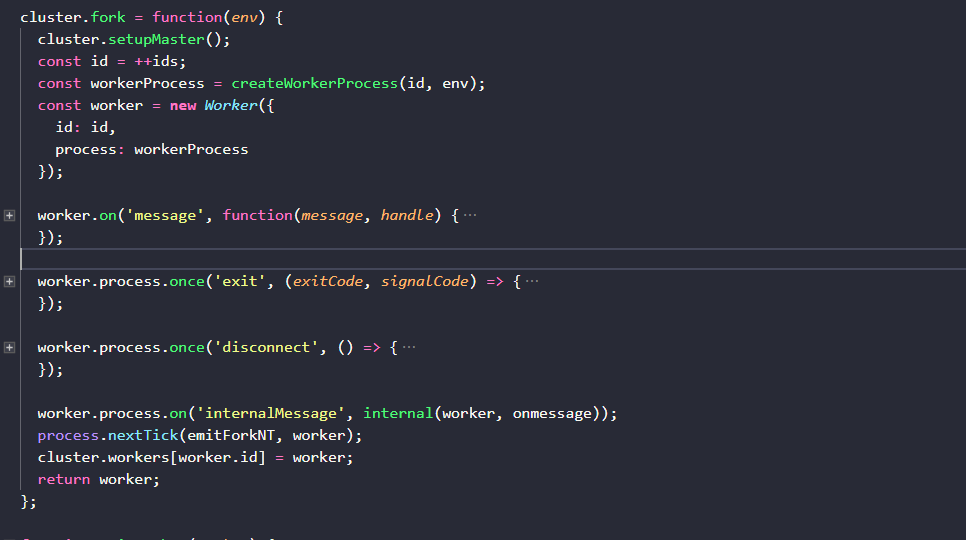
可以看到cluster.fork( )執行時做了如下幾件事情:
1.設定主執行緒引數
2.傳入一個自增引數id(就是前文提到的NODE_UNIQUE_ID)和環境資訊env來生成一個worker執行緒的process物件
3.將id和新的process物件傳入Worker構造器生成新的worker程序例項
4.在子程序的process物件上添加了一些事件監聽
5.在cluster.workers中以id為鍵新增對子程序的引用
6.返回子程序worker例項接著看第一步setupMaster( ),在原始碼中50-95行,著重看81-95行:
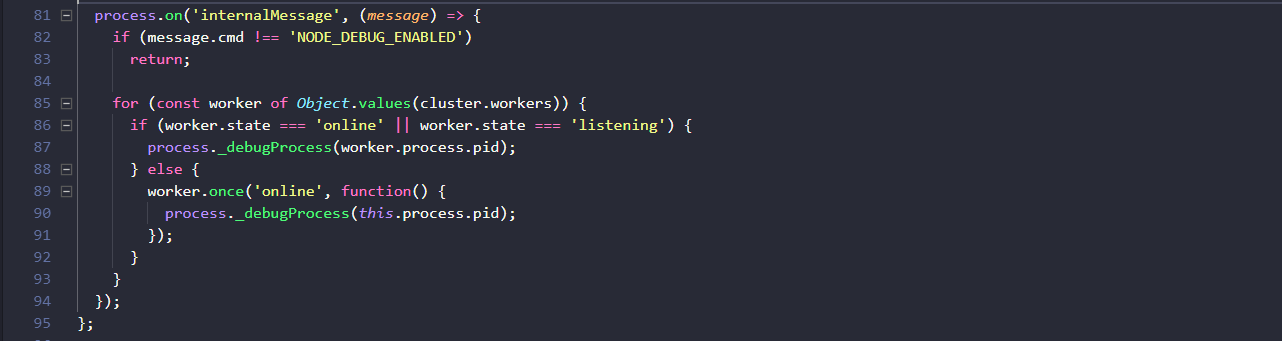
留意一下主執行緒在程序層面監聽的internalMessage事件非常關鍵,主程序監聽到這個事件後,首先判斷訊息物件的cmd屬性是否為NODE_DEBUGE_ENABLED,並以此為條件判斷後續語句是否執行,後續的邏輯是遍歷每一個worker程序例項,如果子程序的狀態是online或listening就將子程序pid作為引數呼叫主程序的_debugProcess( )方法,否則改為在worker程序例項首次上線時呼叫。
process._debugProcess的定義在src/node_process_methods.cc裡,看名字推測大致的意思就是為了啟用對子程序的除錯功能。這是一個過載方法,在windows和linux下有不同的實現。linux下的程式碼較短,基本可以看懂(不秀一下怎麼對得住自己看1周的C++):
#ifdef __POSIX__
static void DebugProcess(const FunctionCallbackInfo<Value>& args) {
//這裡的常量引數是通過地址引用的worker.process.pid
Environment* env = Environment::GetCurrent(args);
//用pid做引數獲取當前啟用的環境變數,這一步應該是在獲取上下文
if (args.Length() != 1) {//不合法呼叫時報錯,沒什麼可說的
return env->ThrowError("Invalid number of arguments.");
}
CHECK(args[0]->IsNumber());//檢測引數
pid_t pid = args[0].As<Integer>()->Value();
int r = kill(pid, SIGUSR1);//傳送SIGUSR1訊號,終止了這個子程序
if (r != 0) {//exit code為0時是正常退出,子程序未能正常中止時報錯
return env->ThrowErrnoException(errno, "kill");
}
}win32平臺中對應的程式碼比較長,看不懂。總結一下這裡就是,在沒有收到cmd屬性等於NODE_DEBUG_ENABLED的內部訊息之前,什麼都不做,如果收到這個訊息,就終止所有的子程序,或者通過事件在子程序第一次處於online狀態就終止它。
按照執行順序接下來是101-140行的createWorkerProcess(id,env)方法,看名字就知道是生成子程序process物件的,前半部分合並和處理環境引數,然後判斷執行引數中是否包含啟用--inspect功能的引數並進行一些處理,最後傳入一堆引數呼叫了fork方法,這個方法就是child_process.fork( ),它就是用來生成子程序的,返回值就是子程序例項,你可以先簡單瀏覽一下API【官方文件child_process.fork功能】,或者知道這裡生成了子程序就好。
回到cluster.fork方法繼續執行,下一步使用新生成的子程序process物件和唯一id作為引數傳入Worker建構函式,生成worker例項,Worker的定義就在當前資料夾的worker.js中,它首先繼承了EventEmitter的訊息的釋出訂閱能力,然後把子程序的process物件掛在在自己的process屬性上,接著為子程序新增error和 message事件的監聽,最後暴露了一些更語義化的針對程序例項的管理方法(更詳細的分析可以參考本系列前一篇博文)。生成了worker程序例項後,添加了對於message事件的響應,並在子程序process物件上監聽程序的exit,disconnect,internalMessage事件,最後將worker例項和自己的id以鍵值對的形式新增到cluster.workers中記錄,並通過return返回給外界,至此master模組的初始化流程就告一段落,先mark一下,後面還會講這裡。
3.4 子程序模組child.js
子程序模組是從master.js呼叫child_process時啟動的,它和主程序是並行執行的。老規矩,程式碼摺疊看一下:
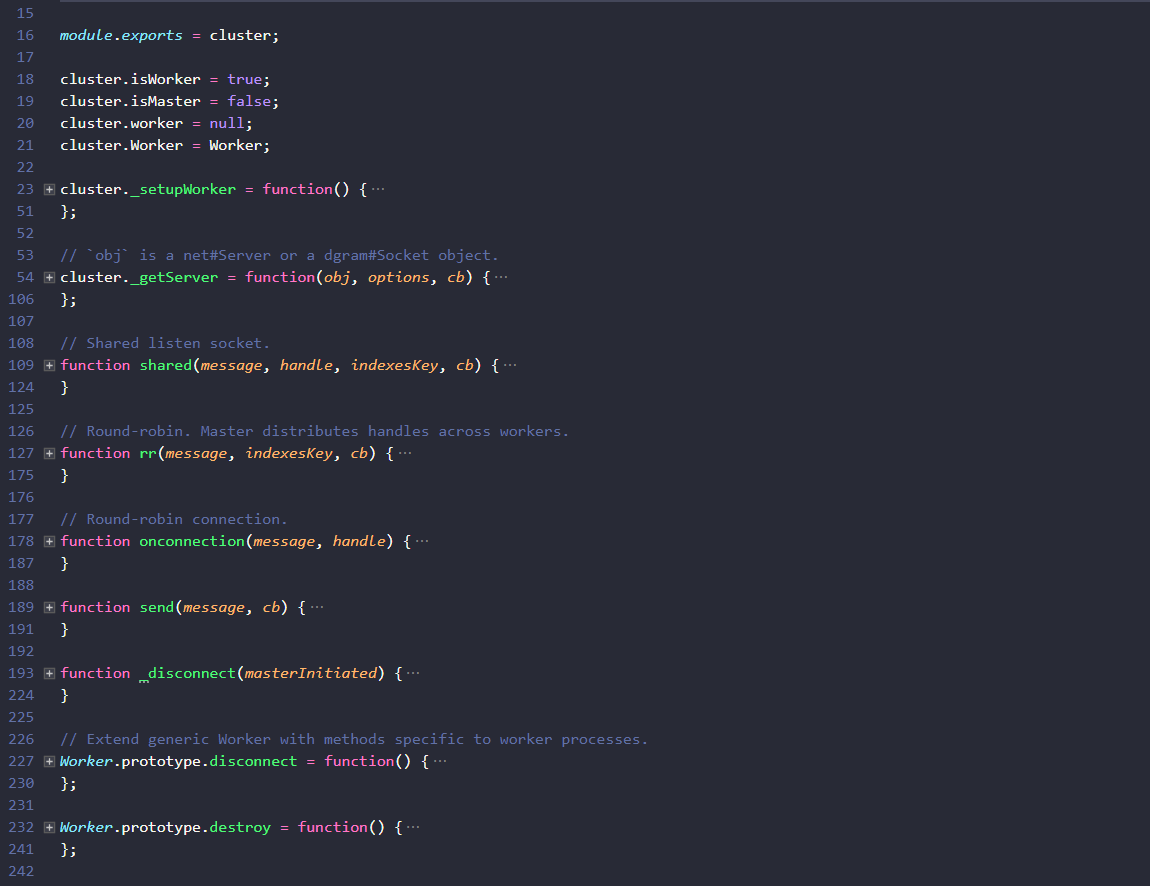
看出什麼了嗎?child.js的程式碼裡只有引用和定義,_setupWorker是在nodejs工作程序初始化時執行的,它在自己的獨立程序中初始化了一個程序管理例項,並執行了下述邏輯:
1.例項化程序管理物件worker
2.全域性新增`disconnect`事件響應
3.全域性新增`internalMessage`事件響應,主要是分發`act:newconn`和`act:disconnect`事件
4.用send方法傳送`online`事件,通知主執行緒自己已上線。注意,這個process物件就是IPC(Inter Process Communication,也稱為跨程序通訊)能夠實現的關鍵,很明顯它繼承了EventEmitter的訊息收發能力,在子程序內部進行訊息收發不存在任何問題,還記得master.js中fork方法嗎?這個process就是呼叫child_process啟動子程序時返回給主程序的那個process物件,當你在主程序中獲取它後,就可以共享worker程序的訊息能力,從而在資源隔離的條件下實現master和worker程序的跨程序通訊。_getServer( )方法是在建立server例項時呼叫的,等到驅動事件資訊到達child.js時再看,可以留意一下最後兩個新增在Worker原型方法上的方法,它們只在子程序中有效。
四. 小結
至此,你已經看到node是如何通過cluster模組實現多例項並初始化跨程序通訊了。但是跨程序通訊的底層實現以及伺服器的建立,以及如何在程序間協調網路請求的處理,還依賴於net和http的一些內容,只好等研究完了再繼續,硬剛反正我是吃不消