
【python】爬蟲爬取美麗小姐姐圖片美女桌布
阿新 • • 發佈:2019-06-02
爬蟲爬取蜂鳥裡的高清桌布
想要自動下載某個網站的高清桌布,不能一個個點選下載,所以用爬蟲實現自動下載。改程式碼只針對特定網站,不同網站需要特別分析。

一、分析網站
https://photo.fengniao.com/

隨便點選一張,發現可以上一頁,下一頁的翻頁,所以可以獲取改圖之後,獲得下一張圖片地址,無線迴圈,下載桌布。本次為了多功能實現,用到了beautifulsoup和re正則表示式兩種搜尋方式。

上圖中需要的資訊,從上到下:改圖下載地址,圖片名字,下一張圖片地址。
二、獲取網頁
| 1 2 3 4 5 6 7 8 |
def getHtmlurl(url): # 獲取網址
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding return r.text
except:
return ""
|
三、下載圖片和獲取下一個圖片地址
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
def getpic(html): # 獲取圖片地址並下載,再返回下一張圖片地址
soup = BeautifulSoup(html, 'html.parser')
#all_img = soup.find('div', class_='imgBig').find_all('img')
all_img = soup.find('a', class_='downPic')
img_url = all_img['href']
reg = r'<h3 class="title overOneTxt">(.*?)</h3>'# r'<a\sclass=".*?"\starget=".*?"\shref=".*?">(.*)</a>' # 正則表示式
reg_ques = re.compile(reg) # 編譯一下正則表示式,執行的更快
image_name = reg_ques.findall(html) # 匹配正則表示式
urlNextHtml = soup.find('a', class_='right btn')
urlNext = urlHead+urlNextHtml['href']
print('正在下載:' + img_url)
root = 'D:/pic/'
path = root + image_name[0] + '.jpg'
try: # 建立或判斷路徑圖片是否存在並下載
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(img_url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("圖片下載成功")
else:
print("檔案已存在")
except:
print("爬取失敗")
return urlNext
|
四、結果
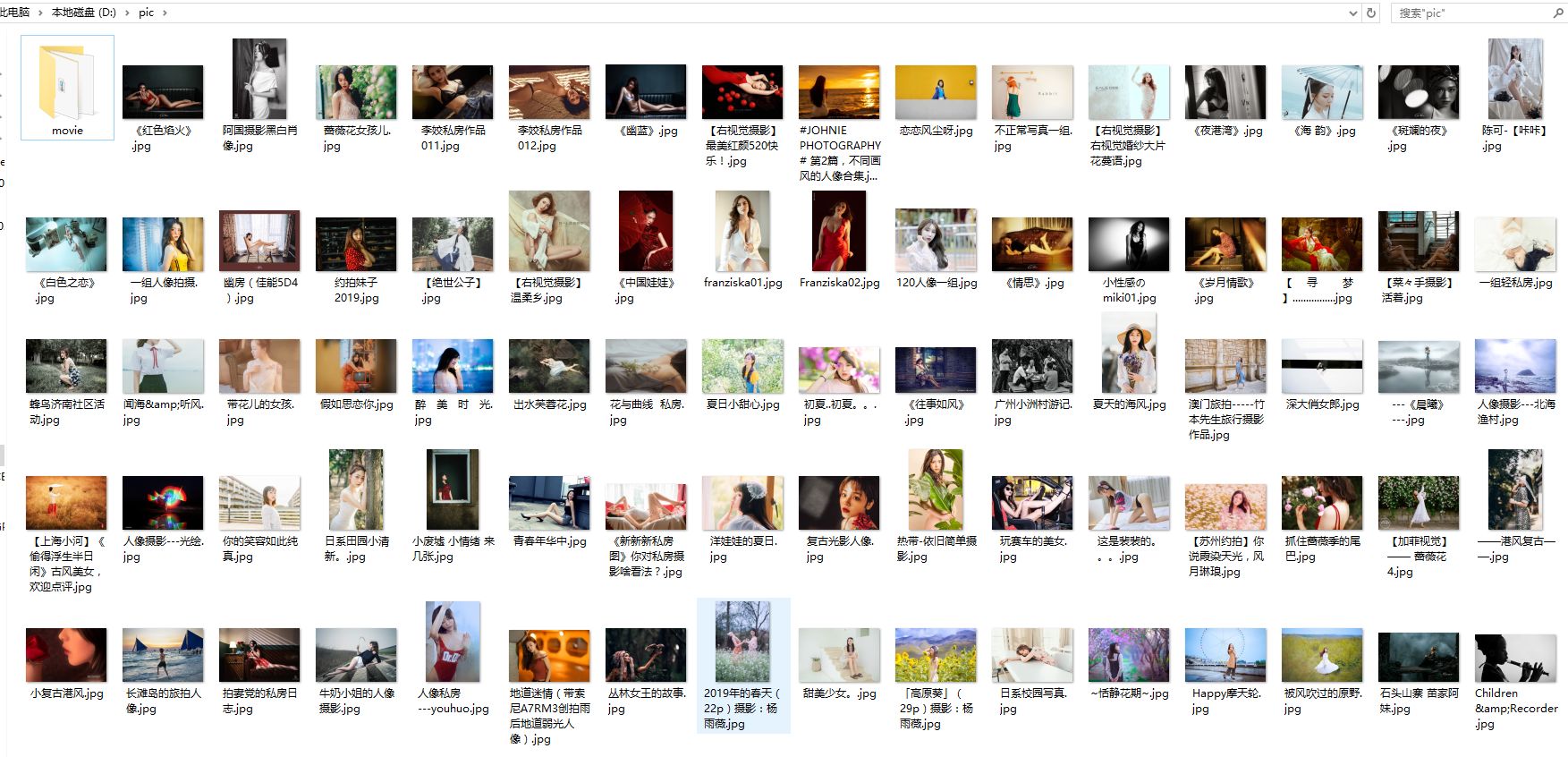
當然,我們也可以下載別的網頁上圖片,如下圖,這就不放大了。

五、原始碼
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
from bs4 import BeautifulSoup
import requests
import os
import re
urlHead = 'https://photo.fengniao.com/'
url = 'https://photo.fengniao.com/pic_43591143.html'
def getHtmlurl(url): # 獲取網址
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getpic(html): # 獲取圖片地址並下載,再返回下一張圖片地址
soup = BeautifulSoup(html, 'html.parser')
#all_img = soup.find('div', class_='imgBig').find_all('img')
all_img = soup.find('a', class_='downPic')
img_url = all_img['href']
reg = r'<h3 class="title overOneTxt">(.*?)</h3>'# r'<a\sclass=".*?"\starget=".*?"\shref=".*?">(.*)</a>' # 正則表示式
reg_ques = re.compile(reg) # 編譯一下正則表示式,執行的更快
image_name = reg_ques.findall(html) # 匹配正則表示式
urlNextHtml = soup.find('a', class_='right btn')
urlNext = urlHead+urlNextHtml['href']
print('正在下載:' + img_url)
root = 'D:/pic/'
path = root + image_name[0] + '.jpg'
try: # 建立或判斷路徑圖片是否存在並下載
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(img_url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("圖片下載成功")
else:
print("檔案已存在")
except:
print("爬取失敗")
return urlNext
def main():
html=(getHtmlurl(url))
print(html)
return getpic(html)
if __name__ == '__main__':
for i in range(1,100):
url=main()
|
下一篇應該是,爬某網站的小視訊。
有問題,聯絡微信:GD562