
面試官:要不簡單聊一下你對MySQL索引的理解?
MySQL索引?這玩意兒還能簡單聊?明顯是在挖坑,幸好老夫早有準備,切聽我一一道來。
一、索引是什麼?
索引是幫助MySQL高效獲取資料的資料結構。
二、索能幹什麼?
索引非常關鍵,尤其是當表中的資料量越來越大時,索引對於效能的影響愈發重要。 索引能夠輕易將查詢效能提高好幾個數量級,總的來說就是可以明顯的提高查詢效率。
三、索引的分類?
1、從儲存結構上來劃分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。這裡所描述的是索引儲存時儲存的形式,
2、從應用層次來分:普通索引,唯一索引,複合索引
3、根據中資料的物理順序與鍵值的邏輯(索引)順序關係:聚集索引,非聚集索引。
平時講的索引型別一般是指在應用層次的劃分。
就像手機分類:安卓手機,IOS手機 與 華為手機,蘋果手機,OPPO手機一樣。
普通索引:即一個索引只包含單個列,一個表可以有多個單列索引
唯一索引:索引列的值必須唯一,但允許有空值
複合索引:多列值組成一個索引,專門用於組合搜尋,其效率大於索引合併
聚簇索引(聚集索引):並不是一種單獨的索引型別,而是一種資料儲存方式。具體細節取決於不同的實現,InnoDB的聚簇索引其實就是在同一個結構中儲存了B-Tree索引(技術上來說是B+Tree)和資料行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
四、索引的底層實現
mysql預設儲存引擎innodb只顯式支援B-Tree( 從技術上來說是B+Tree)索引,對於頻繁訪問的表,innodb會透明建立自適應hash索引,即在B樹索引基礎上建立hash索引,可以顯著提高查詢效率,對於客戶端是透明的,不可控制的,隱式的。
不談儲存引擎,只討論實現(抽象)
Hash索引
基於雜湊表實現,只有精確匹配索引所有列的查詢才有效,對於每一行資料,儲存引擎都會對所有的索引列計算一個雜湊碼(hash code),並且Hash索引將所有的雜湊碼儲存在索引中,同時在索引表中儲存指向每個資料行的指標。
B-Tree索引(MySQL使用B+Tree)
B-Tree能加快資料的訪問速度,因為儲存引擎不再需要進行全表掃描來獲取資料,資料分佈在各個節點之中。
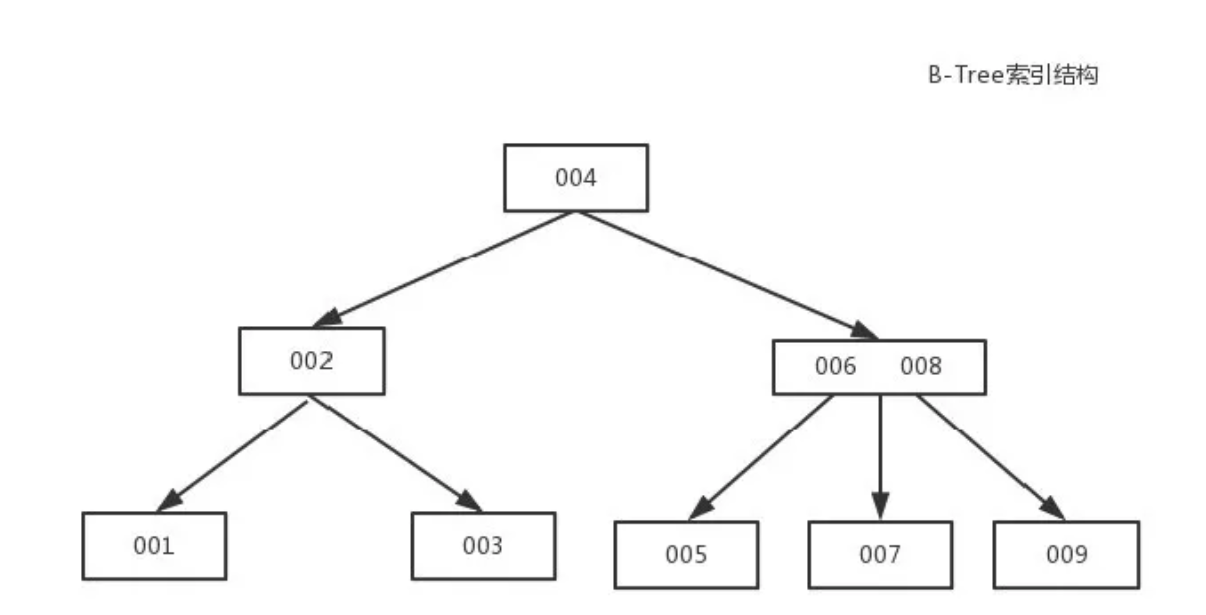
B+Tree索引
是B-Tree的改進版本,同時也是資料庫索引索引所採用的儲存結構。資料都在葉子節點上,並且增加了順序訪問指標,每個葉子節點都指向相鄰的葉子節點的地址。相比B-Tree來說,進行範圍查詢時只需要查詢兩個節點,進行遍歷即可。而B-Tree需要獲取所有節點,相比之下B+Tree效率更高。

結合儲存引擎來討論(一般預設使用B+Tree)
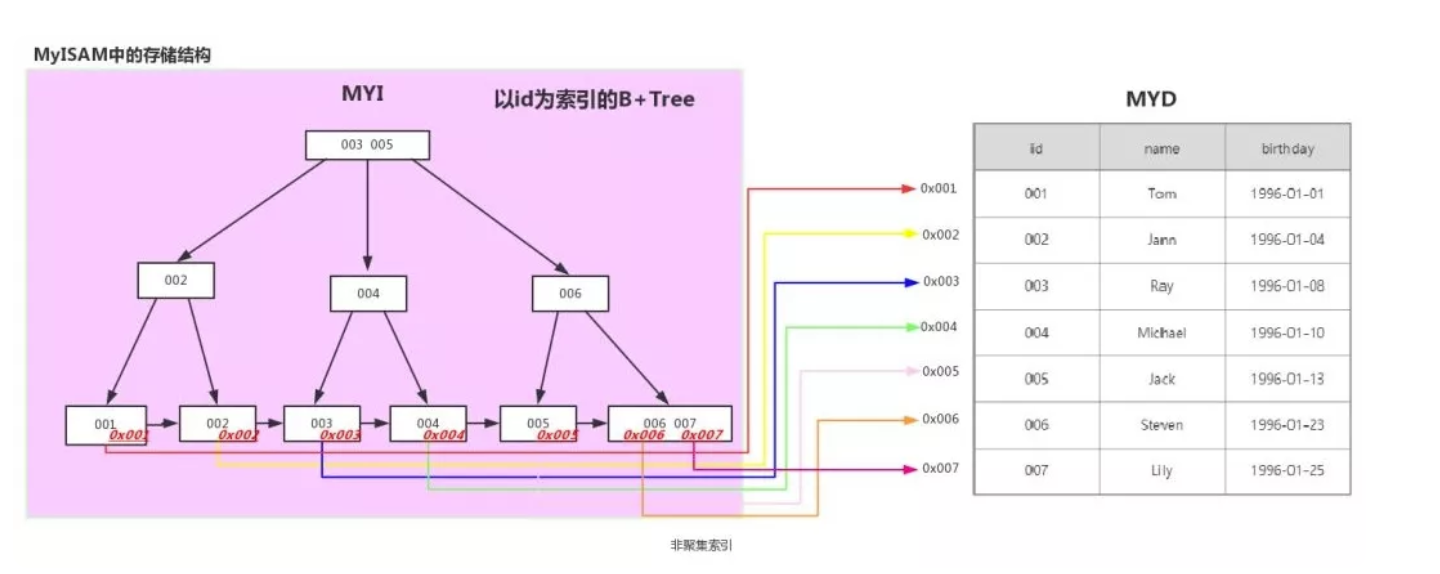
案例:假設有一張學生表,id為主鍵
| id | name | birthday |
|---|---|---|
| 1 | Tom | 1996-01-01 |
| 2 | Jann | 1996-01-04 |
| 3 | Ray | 1996-01-08 |
| 4 | Michael | 1996-01-10 |
| 5 | Jack | 1996-01-13 |
| 6 | Steven | 1996-01-23 |
| 7 | Lily | 1996-01-25 |
在MyISAM引擎中的實現(二級索引也是這樣實現的)
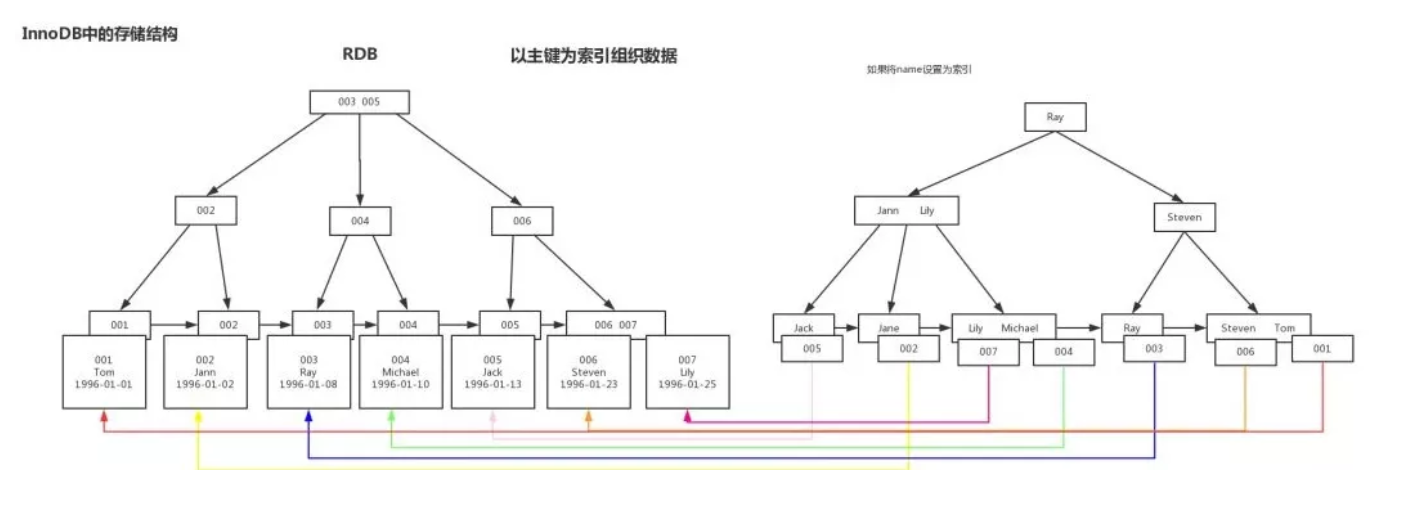
在InnoDB中的實現

五、為什麼索引結構預設使用B+Tree,而不是Hash,二叉樹,紅黑樹?
B-tree:因為B樹不管葉子節點還是非葉子節點,都會儲存資料,這樣導致在非葉子節點中能儲存的指標數量變少(有些資料也稱為扇出),指標少的情況下要儲存大量資料,只能增加樹的高度,導致IO操作變多,查詢效能變低;
Hash:雖然可以快速定位,但是沒有順序,IO複雜度高。
二叉樹:樹的高度不均勻,不能自平衡,查詢效率跟資料有關(樹的高度),並且IO代價高。
紅黑樹:樹的高度隨著資料量增加而增加,IO代價高。
六、為什麼官方建議使用自增長主鍵作為索引?
結合B+Tree的特點,自增主鍵是連續的,在插入過程中儘量減少頁分裂,即使要進行頁分裂,也只會分裂很少一部分。並且能減少資料的移動,每次插入都是插入到最後。總之就是減少分裂和移動的頻率。
插入連續的資料:
插入非連續的資料
七、簡單總結下
1、MySQL使用B+Tree作為索引資料結構。
2、B+Tree在新增資料時,會根據索引指定列的值對舊的B+Tree做調整。
4、從物理儲存結構上說,B-Tree和B+Tree都以頁(4K)來劃分節點的大小,但是由於B+Tree中中間節點不儲存資料,因此B+Tree能夠在同樣大小的節點中,儲存更多的key,提高查詢效率。
5、影響MySQL查詢效能的主要還是磁碟IO次數,大部分是磁頭移動到指定磁軌的時間花費。
6、MyISAM儲存引擎下索引和資料儲存是分離的,InnoDB索引和資料儲存在一起。
7、InnoDB儲存引擎下索引的實現,(輔助索引)全部是依賴於主索引建立的(輔助索引中葉子結點儲存的並不是資料的地址,還是主索引的值,因此,所有依賴於輔助索引的都是先根據輔助索引查到主索引,再根據主索引查資料的地址)。
8、由於InnoDB索引的特性,因此如果主索引不是自增的(id作主鍵),那麼每次插入新的資料,都很可能對B+Tree的主索引進行重整,影響效能。因此,儘量以自增id作為