
達摩院首席資料庫科學家李飛飛:雲原生新戰場,我們如何把握先機?
阿里妹導讀:雲端計算大潮來襲,傳統資料庫市場正面臨重新洗牌的情境,包括雲資料庫在內的一批新生力量崛起,動搖了傳統資料庫的壟斷地位,而由雲廠商主導的雲原生資料庫則將這種“改變”推向了高潮。
雲時代的資料庫將面臨怎樣的變革?雲原生資料庫有哪些獨特優勢?在 DTCC 2019大會上,阿里巴巴副總裁 李飛飛博士就《下一代雲原生資料庫技術與趨勢》進行了精彩分享。

李飛飛(花名:飛刀),阿里巴巴集團副總裁,高階研究員,達摩院首席資料庫科學家,阿里雲智慧事業群資料庫產品事業部負責人,ACM 傑出科學家。
大勢所趨:雲資料庫市場份額增速迅猛
如下圖所示的是 Gartner 關於全球資料庫市場份額的報告,該報告指出目前全球資料庫市場份額大約為400億美金,其中,中國資料庫市場份額佔比為3.7%,大約為14億美金。
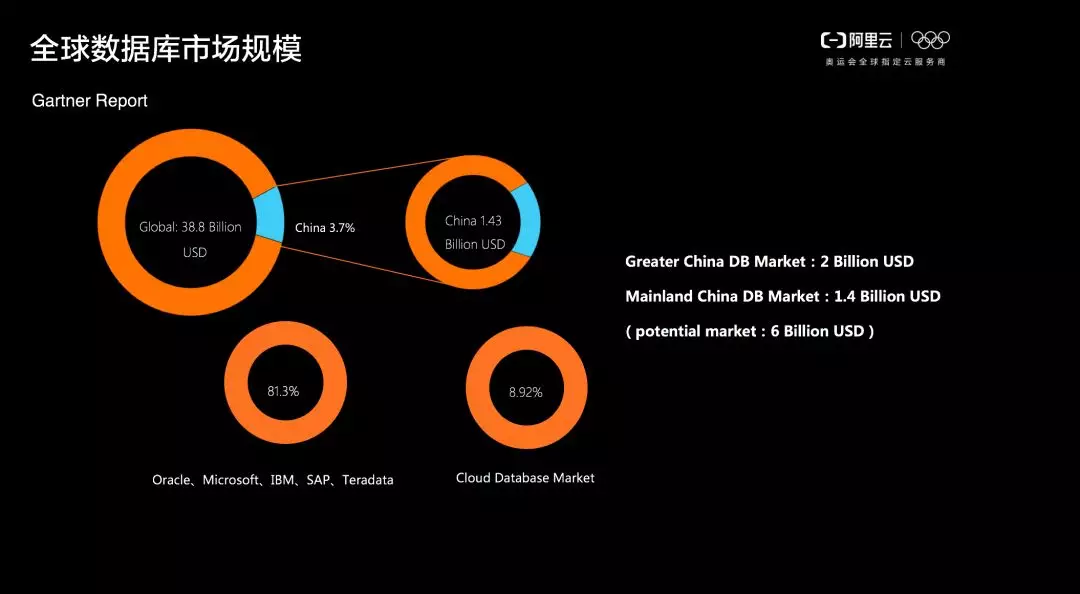
具體到資料庫市場分佈,傳統五大資料庫廠商 Oracle、Microsoft、IBM、SAP、Teradata 佔比達到了80%,雲資料庫的份額佔比接近10%,並且雲資料庫市場份額佔比每年也在快速增長,因此, Oracle、MongoDB 等也在大力佈局其在雲資料庫市場的競爭態勢。
根據 DB-Engines 資料庫市場分析顯示,資料庫系統正朝著多樣化、多元化的方向發展,從傳統的 TP 關係型資料庫發展到今天的多源異構的資料庫形態。目前,處於主流位置的還是大家耳熟能詳的資料庫系統,比如商業資料庫 Oracle、SQL Server以及開源的 MySQL、PostgreSQL 等。而一些比較新的資料庫系統,比如MongoDB、Redis 則開闢了一個新的賽道。資料庫 License 的傳統銷售方式在逐漸走下坡路,而開源以及雲上資料庫 License 的流行程度卻在不斷提升。
資料庫:雲上應用關鍵的一環
正如 AWS 創始人 Jeff Bezos 所說:“The real battle will be in databases”。因為雲最早是從 IaaS 做起來的,從虛擬機器、儲存、網路,到現在如火如荼的語音識別、計算機視覺以及機器人等智慧化應用,都是基於 IaaS 的,而資料庫就是連線 IaaS 與智慧化應用 SaaS 最為關鍵的一環。從資料產生、儲存到消費的各個環節,資料庫都至關重要。
資料庫主要包括四大板塊,即 OLTP、OLAP、NoSQL 以及資料庫服務和管理類工具,也是雲資料庫廠商發力的四個方向。對於 OLTP 而言,技術發展已經歷經了40年,而如今大家還在做的一件事情就是“加10元和減10元”,也就是所謂的事務處理。當資料量變得越來越大和讀寫衝突的原因,對資料進行線上實時分析的需求衍生出了 OLAP。由於需要 Scale out,而資料強一致性不能夠得到保證,就有了NoSQL 。而最近又出現了一個新名詞—— NewSQL,這是因為 NoSQL 也有所不足,故將傳統 OLTP 的 ACID 保證與 NoSQL 的 Scale out 能力進行了整合,變成了NewSQL。
資料庫系統架構演進:All depends on what is shared
縱觀資料庫40年來的發展歷史,從最早的關係型資料庫時期,衍生出了 SQL、OLTP 等技術;到資料量急劇增長,需要避免讀寫衝突,通過 ETL、資料倉庫以及 Data Cube 等技術實現了 OLAP;再到今天,面對異構多源的資料結構,從圖到時序、時空到向量等,也就誕生了 NoSQL、NewSQL 等資料庫,同時也出現了一些新的技術,比如 Multi-Model 和 HTAP 等。
資料庫系統最為主流的架構是 Shared Memory:共享處理器核心,共享記憶體並且具有共享的本地磁碟,這樣的單機架構屬於非常主流的架構,傳統的資料庫廠商基本採用的也是這樣的架構。
而隨著網際網路企業的大規模發展,如 Google、Amazon 以及阿里巴巴,大家發現原來的單機架構有很多限制,其可擴充套件性以及吞吐量無法滿足業務發展需求,於是就衍生出了 Shared Disk/Storage 架構,即共享儲存架構。也就是說資料庫底層可能是分散式儲存,通過利用 RDMA 這樣的快速網路讓上層的資料庫核心看起來像是在使用本地的磁碟,但實際上是分散式儲存。上面可以有多個獨立計算節點,一般是一寫多讀,但是也可以做多寫多讀,這就是共享儲存架構,其中比較典型的代表就是阿里雲的 POLARDB 資料庫。
另外一種架構是 Shared Nothing 。共享儲存雖然有諸多優點,解決了很多問題,但是 RDMA 網路也存在很多的限制,比如其跨越 Switch 甚至是跨 AZ 和 Region 的時候效能都會有所損失。分散式的共享儲存達到一定的節點數量之後,效能會出現一定的損耗,所以不能保證訪問遠端資料和訪問本地資料的效能完全相同,所以共享儲存的架構當擴充套件到十幾個節點之後就達到了 scale out 擴充套件的上限了。此時,如果應用需要繼續擴充套件怎麼辦呢?那就需要實現分散式架構了,比較典型的就是 Google Spanner,其利用原子鐘技術能夠實現跨資料中心的資料一致性和事務一致性。而在阿里雲,基於 POLARDB 實現的分散式版本 POLARDB-X 採用的也是 Shared Nothing 架構。
這裡需要注意的一點就是:Shared Nothing 和 Shared Storage 可以結合。可以在上層做 Shared Nothing,而對於下層的 Shard 分片採用 Shared Storage 架構。這樣混合架構的好處在於能夠減輕分出太多 Shard 的痛點問題,減少分散式事務distributed commit的 概率,因為 distributed commit 的代價非常昂貴。
總結三種架構設計,如果在 Shared Storage 架構上做到多寫多讀而不是一寫多讀,實際上也就實現了 SharedEverything 。將 Shared nothing 和 Sharedstorage 架構進行結合的 hybrid 架構應該是後續資料庫系統發展方向的一個重要突破點。
雲原生資料庫核心四要素
上面從架構方面分析了雲時代的主流資料庫架構。從技術上來講,除了架構上的不同,雲原生時代還有一些不同點。
多模(Multi-model)
其一是多模(Multi-model),多模主要有兩種,即北向和南向。南向表示儲存結構是多種多樣的,資料結構可以是結構化的也可以是非結構化的,可以是圖、向量、文件等,但對於使用者只提供一個 SQL 的查詢介面或者 SQL-Like 的介面,這部分業界比較典型的就是各種各樣的資料湖服務。而北向的多模就是儲存只有一種,一般是通過 KV 儲存資料形態來支援結構化、半結構化以及非結構化資料,但希望能夠提供不同的查詢介面,比如 SPARQL、SQL、GQL 等。業界典型的代表是微軟 Azure 的CosmosDB。
資料庫智慧化+自動化管控平臺
資料庫的自治化也是非常重要的發展方向,從資料庫的核心以及管控平臺兩個角度都有很多技術點可以做。在資料庫自治化部分,阿里巴巴認為,需要做到自感知、自決策、自恢復以及自優化。自優化比較簡單,就是在核心中利用機器學習的方法來進行優化。而自感知、自決策、自恢復更多的是針對管控平臺的,比如如何保證例項的巡檢,當出現問題後如何能夠自動快速修復或者自動切換等。
新硬體: 軟硬體一體化設計
雲原生資料庫的第三大核心點是軟硬體一體化設計。資料庫首先是一個系統,而系統就需要能夠安全高效地使用有限的硬體資源。所以資料庫系統的設計和發展一定是和硬體效能和發展緊密相關的,我們不能夠面對硬體的變化而堅持舊有資料庫設計不改變,比如 NVM 出來之後就可能對傳統的資料庫設計有一些衝擊。而新硬體所帶來的變化也是資料庫系統設計需要考慮的。
RDMA、NVM 以及 GPU/FPGA 等新硬體或者架構的出現,對於資料庫的設計都會提供新的思路。
高可用
高可用是雲原生最基本的要求之一,上雲的使用者勢必不希望業務出現中斷。高可用最簡單的解決方案就是冗餘,可以做 Table 級別的冗餘,也可以做 Partition 級別的冗餘。無論是使用哪一種,基本上都是三副本,甚至更多的時候需要做四副本或者五副本,比如金融級別的高可用可能需要做兩地三中心或者兩地四中心。
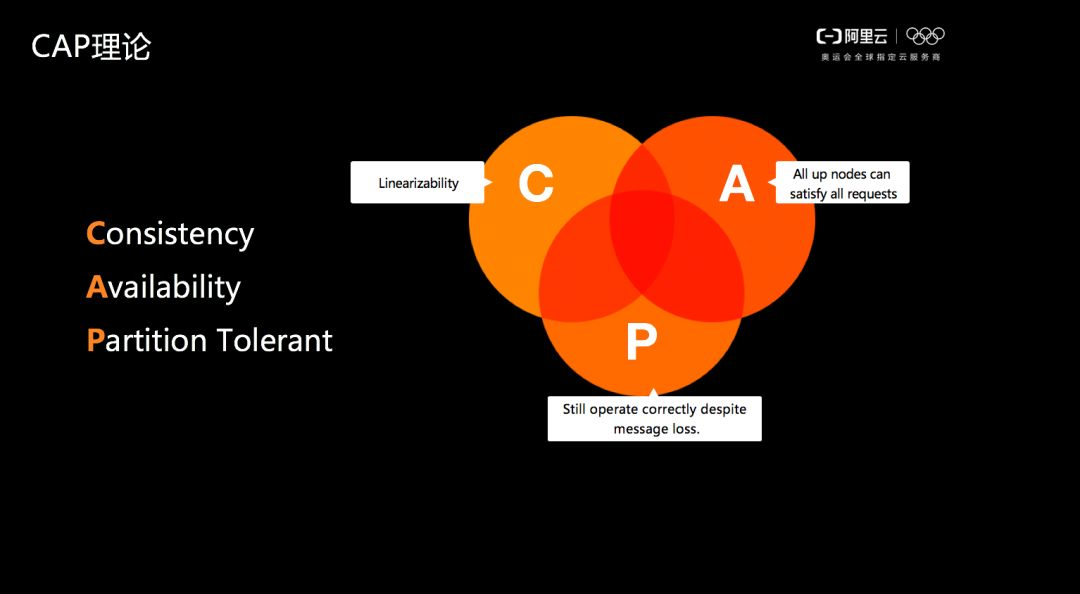
對於高可用的多副本而言,如何保證副本之間的資料一致性?在資料庫裡面有一個經典的CAP理論,其理論結果是在 Consistency、Availability 和 Partition Tolerant 三者之間只能選擇兩個。現在大家的一般選擇都是 C+P,同時對於 A 而言,通過三副本技術和分散式一致性協議,使得 A 達到6個9或者7個9,這樣基本上就做到了100%的 CAP。
雲原生資料庫 POLARDB:極致彈性+相容性 為海量資料和海量併發而生
前面介紹了資料庫市場背景和雲原生資料庫的基本要素,接下來我將結合阿里雲 POLARDB 以及 AnalyticDB 兩款資料庫系統,分享以上技術的具體落地情況。POLARDB 是阿里雲的雲原生資料庫,目前已有非常深厚的技術積累。我們在VLDB 2018,SIGMOD 2019等國際學術會議上發表了相關論文,主要介紹儲存引擎等方面的技術創新。
POLARDB 採用共享儲存架構,一寫多讀。共享儲存架構有多個優勢,首先是計算和儲存分離,計算節點和儲存節點可以分開實現彈性縮擴容;其次,POLARDB 突破了 MySQL、PG 等資料庫對於單節點規格和可擴充套件性的限定,能夠實現 100TB 儲存容量以及每個節點100萬 QPS 的效能;此外,POLARDB 能夠提供極致的彈效能力,備份恢復能力也有很大提升。在儲存層,每個資料塊都採用三副本高可用技術,同時對於 Raft 協議進行了修改,通過實現並行式的 Raft 協議保證了三副本資料塊之間的資料一致性,提供了金融級高可用。POLARDB 還能做到100%相容 MySQL 以及 PG 等資料庫生態,可以幫助使用者實現無感知的應用遷移。
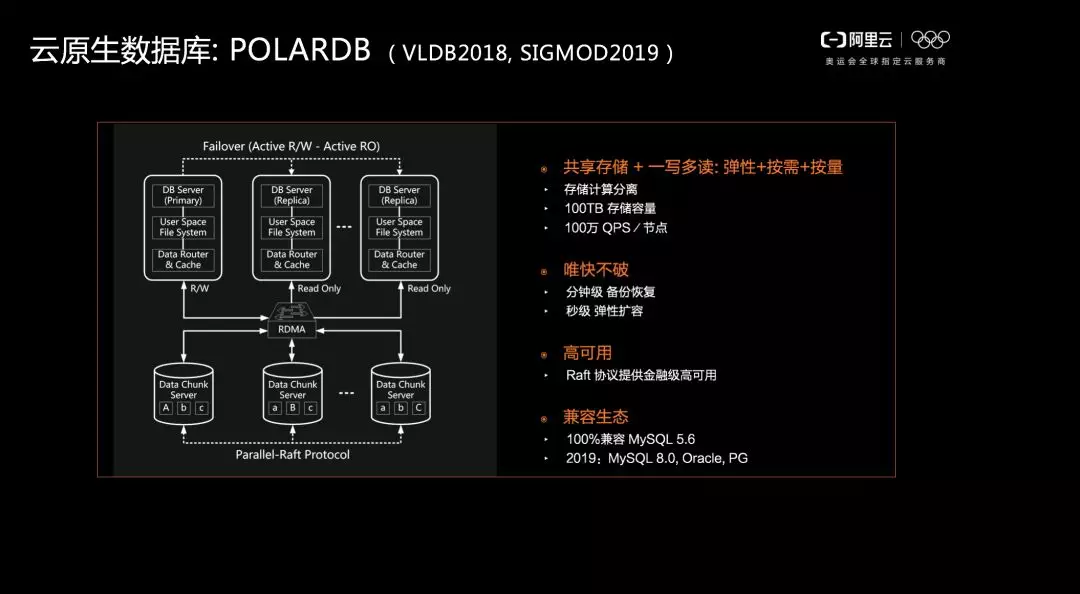
由於底層是共享的分散式儲存,PolarDB 屬於 Active-Active 的架構,主節點負責寫入資料,從節點負責讀取資料,因此,對於進入資料庫的事務而言,主備節點都處於Active 狀態,其好處在於通過一份物理儲存避免了在主從之間不停地做資料同步。
具體而言,POLARDB 有一個 PolarProxy,也就是前面的閘道器代理,下面有 POLARDB 的核心以及 PolarFS,最下面對接的是 PolarStore,利用 RDMA 網路管理底層的分散式共享儲存。PolarProxy 會對客戶需求做分發,將寫請求分配到主節點,而對於讀請求而言,則會根據負載均衡以及讀節點的狀態實現對於讀請求的分配,這樣就能夠儘可能地實現資源的最大化利用以及效能的提升。
POLARDB 共享儲存採用分散式+三副本。其中 Primary 節點負責寫,其他節點負責讀,其下層是 PolarStore,每部分都會有三副本的備份,通過分散式一致性協議保證資料一致性。這樣設計的優勢在於能夠實現儲存與計算分離,同時能夠做到無鎖備份,所以備份可做到秒級。
在一寫多讀的情況下,POLARDB 能夠實現快速伸縮。舉例而言,從2核 vCPU 升級到32核或者從兩個節點擴充套件到4個節點,都能夠在5分鐘之內生效。儲存和計算分離能夠帶來的另一大好處是降低成本,因為儲存和計算節點可以獨立地進行彈性伸縮,充分體現成本優勢。
下圖展示了 POLARDB 如何利用物理日誌實現持續恢復。左側是傳統資料庫的架構,而在 POLARDB 裡面,由於採用了共享儲存,因此可基本保留類似傳統資料庫利用物理日誌進行恢復的過程,通過共享儲存實現持續恢復,做事務的 Snapshot 恢復。
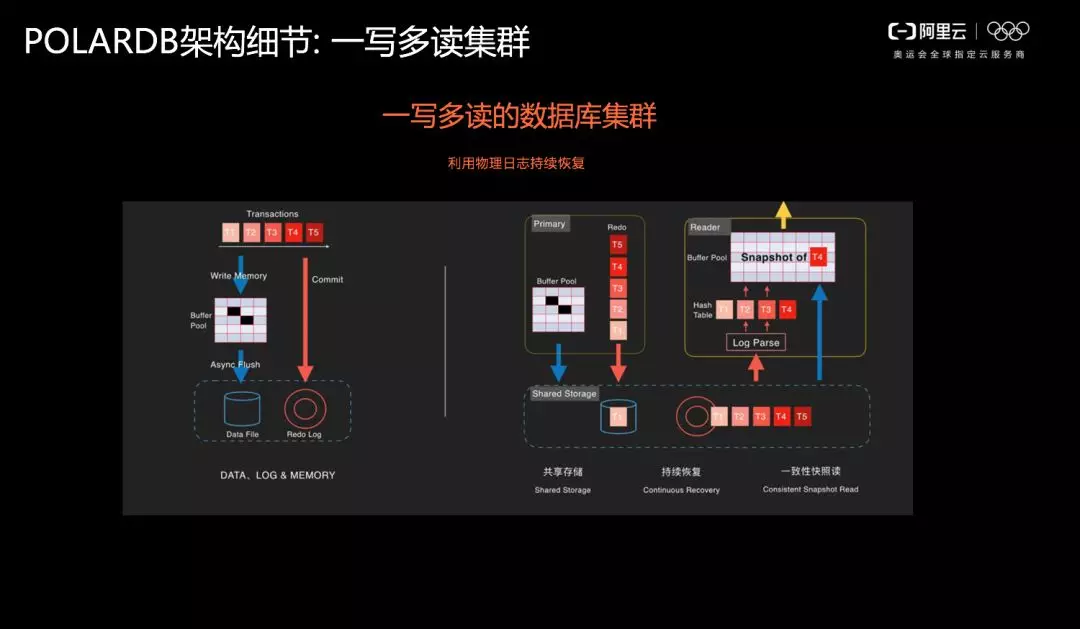
對比一下,如果 MySQL 做主備架構,首先需要在主庫裡面有一個邏輯日誌和物理日誌,在備庫裡面要重放主庫的邏輯日誌,然後再按照主庫的方式做邏輯日誌和物理日誌。而在 POLARDB 裡面,因為是共享儲存,可直接通過一份日誌實現資料恢復,備庫能夠直接將所需要的資料恢復出來,而不需要去重放主庫的邏輯日誌。
POLARDB一寫多讀叢集的另一大優勢是動態 DDL 的支援。在 MySQL 架構下,如要對資料的 Schema 進行修改,需要通過 Binlog 去 Replay 到備庫,因此備庫會存在Blocking 的階段,需要一定時間 Replay 動態的 DDL。而在 POLARDB共享儲存架構下,所有 Schema 資訊以及 metadata 均以表的形式直接儲存在儲存引擎裡面,只要主庫改完了,那麼備庫的元資訊也實時同步更新,因此不會存在 Blocking 的過程。
POLARDB 的 Proxy 最主要的作用就是做讀寫分離、負載均衡、高可用切換以及安全防護等。POLARDB 是一寫多讀架構,當請求進來之後,需要進行讀寫的判斷,將寫請求分發到寫節點,將讀請求分發到讀節點上去,並且對於讀請求做一定的負載均衡。這樣就能保證會話的一致性,並且徹底解決了讀不到最新資料的問題。
無損彈性是 POLARDB 監控的模組之一。分散式儲存需要知道分配多少磁碟量 /Chunk,POLARDB 會監控未使用的 Chunk 量。比如當可用量低於30%的時候,就會在後臺自動地對其進行擴容,這使得應用基本不受影響,可連續寫資料。
對於雲資料庫 POLARDB 而言,以上技術帶來的最大優勢是極致的彈性。這裡我們以一個具體的客戶案例進行說明。如下圖所示,紅線部分指離線資源的消耗情況,這些成本是客戶無論如何都需要付出的,而其上面的部分則是計算資源的需求。
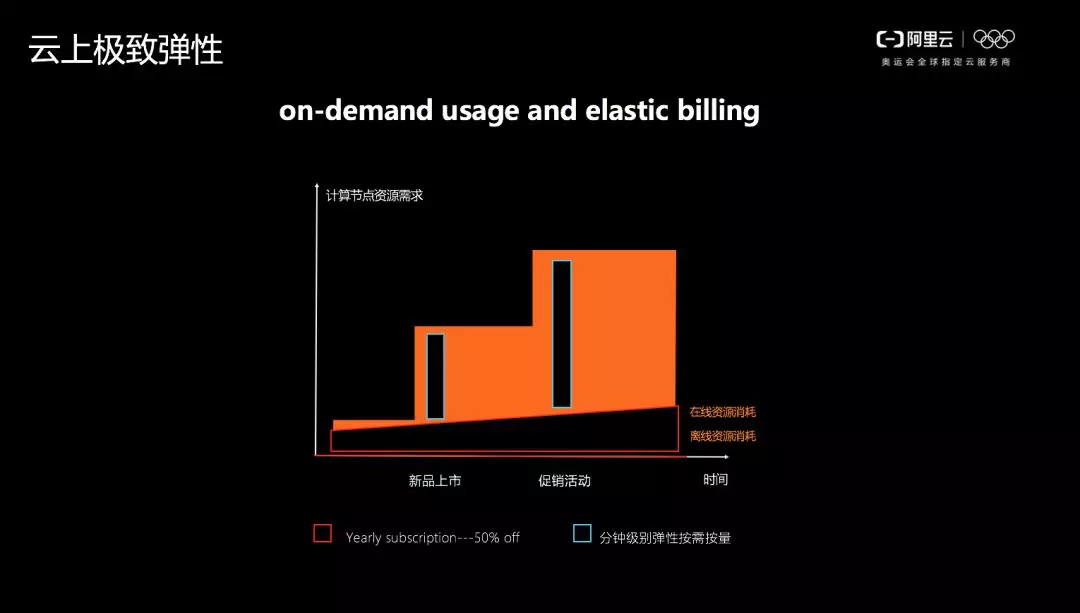
比如客戶在3、4月有新品上市,5月還有促銷活動,這兩個時期計算需求會非常大。如按照傳統架構方式,可能需要在新品上市之前就將容量彈到更大的規模,並且保持這樣的水位,到了後面的促銷階段又需要彈到更高的規格,成本非常高昂。但如果能夠做到極致彈性,比如 POLARDB 的儲存與計算分離,實現快速彈性擴容,那麼使用者就只需在藍色方塊出現之前將容量彈上去,之後再彈下來即可,這樣就能大幅降低成本。
除了雲原生資料庫 POLARDB ,阿里雲資料庫團隊在其他方向還有眾多探索。
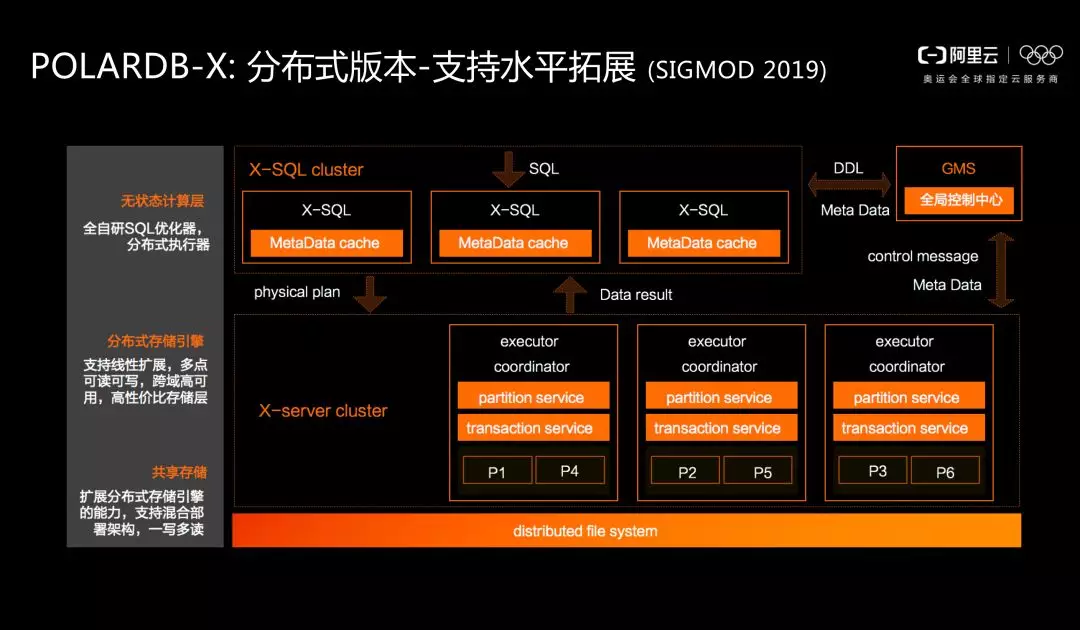
分散式版本 POLARDB-X : 高併發+跨域高可用 支援水平拓展
如果企業需要極致的 Scale out 能力,像阿里巴巴以及傳統行業中的銀行、電力等對高併發、海量資料支撐要求極高的使用者,共享儲存架構只能支援彈至十幾個節點,肯定是不夠的。因此,阿里雲資料庫團隊也採用 Shared Nothing 做水平拓展,將Shared Nothing 與 Shared Storage 相結合,形成 POLARDB-X 。POLARDB-X 支援金融級跨可用區資料強一致, 對支援海量資料下的高併發事務處理有著極好的效能表現。目前,POLARDB-X 在阿里內部已上線應用,利用儲存計算分離、硬體加速、分散式事務處理和分散式查詢優化等技術,成功支援了在雙11這樣的場景下阿里巴巴所有業務核心鏈路資料庫洪峰的挑戰,我們後續將推出商業化版本,敬請期待。
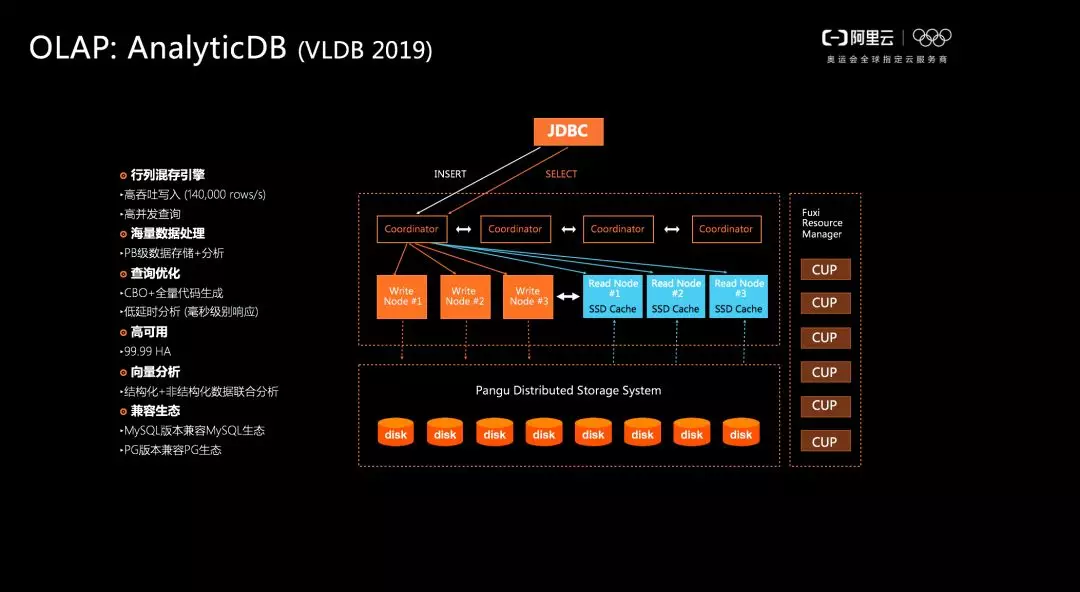
OLAP 資料庫標杆—— AnalyticDB:海量資料 實時高併發線上分析
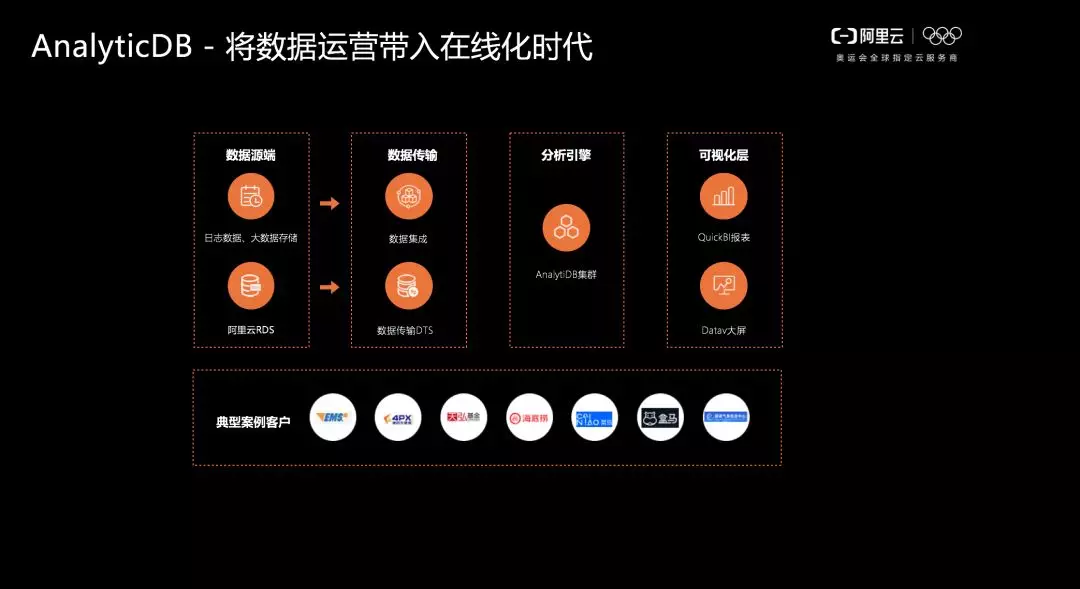
此外在 OLAP 分析型資料庫方向,阿里雲資料庫團隊自主研發了資料庫產品——AnalyticDB,在阿里雲的公有云和專有云上均有售賣。AnalyticDB 擁有幾大核心架構特點:
- 行列混存引擎,能夠支援高吞吐寫入和高併發查詢;
- 支援海量資料處理,對於海量資料能實現秒級分析,完美支援多表、中文以及複雜分析;
- 利用向量化技術,支援結構化資料和非結構化資料的融合處理。
近日,AnalyticDB 打榜 TPC-DS,在價效比方面達到了全球第一,通過了 TPC 官方的嚴苛認證。同時,介紹 AnalyticDB 系統的論文即將在 VLDB 2019 會議上展現。AnalyticDB 的常用應用場景是從 OLTP 應用我們的資料傳輸與同步工具 DTS 至AnalyticDB 進行實時的資料分析。
自治資料庫平臺:智慧調參上線 iBTune (individualized Buffer Tuning)
雲原生資料庫的特點之一是自治化,阿里雲內部有個平臺叫 SDDP(Self-Driving Database Platform——自治化資料庫平臺),SDDP 會對各個資料庫例項進行實時的效能資料採集,並使用機器學習方法建模進行實時調配。
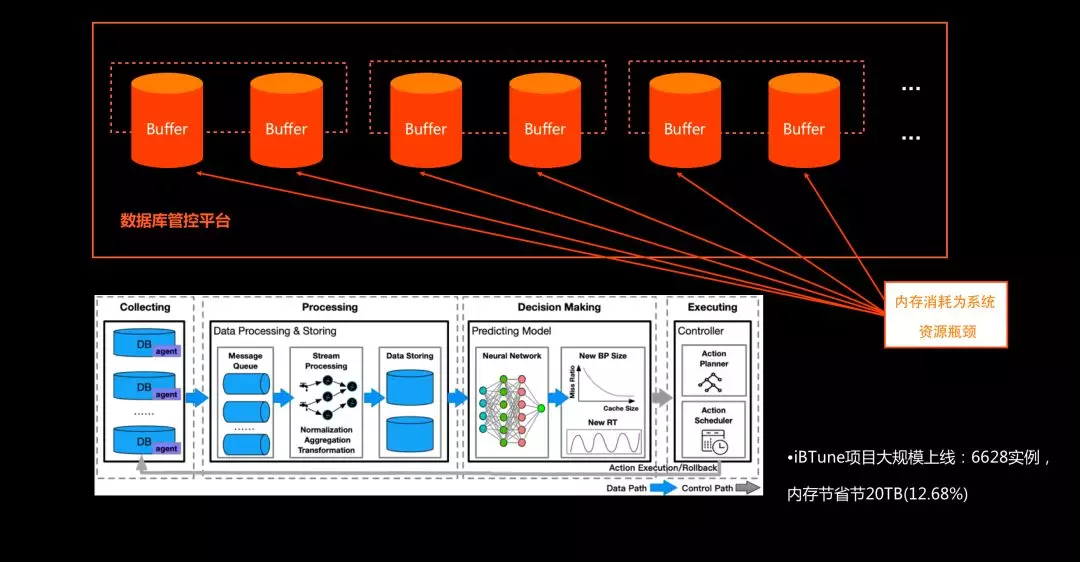
iBTune 的基本思想是,每個資料庫例項都包含一個 Buffer Size,傳統資料庫裡面的Buffer Size 是提前分配好的,不能變化。而在大型企業裡,Buffer 是一個資源池,需要消耗記憶體,因此希望做到彈性自動調配每個例項裡的 BufferSize。比如淘寶商品庫的資料庫例項晚上不需要那麼大的 Buffer,那麼就可以自動將其 Buffer Size 彈下來,到早上再自動彈上去,同時要求不影響其 RT。為了滿足上述需求並進行自動Buffer 優化,阿里雲資料庫團隊構建了 iBTune 系統,目前監控近 7000個數據庫例項,通過長期運營,可平均節省20TB 記憶體。介紹 iBTune 專案的核心技術論文也發表在了今年的 VLDB 2019大會上。
安全上雲是關鍵 多重加密護航資料安全
雲上的資料安全是非常重要的內容,阿里雲資料庫團隊在資料安全方面也做了大量的工作。首先,資料落盤加密,在資料儲存的時候就進行加密。此外,阿里雲資料庫也支援 BYOK,使用者可以將自己的金鑰拿到雲上來實現落盤加密以及傳輸級別的加密。未來,阿里雲資料庫還將在記憶體處理時實現全程加密,對日誌實現可信驗證等。
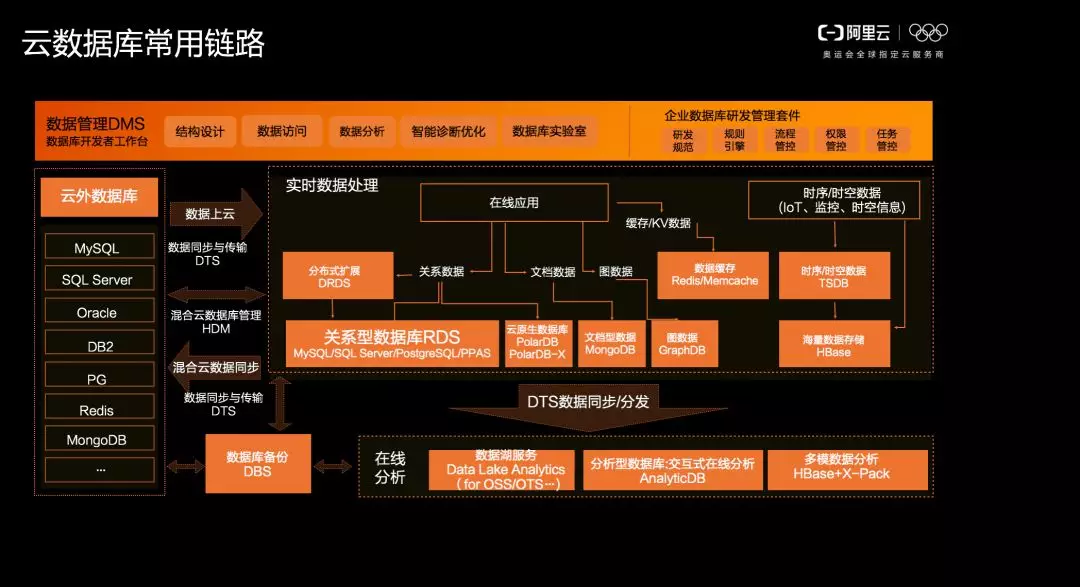
阿里雲企業級資料庫雲服務:全方位運維 全鏈路佈局
阿里雲資料庫按照工具產品、引擎產品以及運營管控的全程資料庫產品分類提供服務。下圖展現的是阿里雲——雲資料庫常用鏈路,通過 DTS 工具將線下資料庫遷移到線上,基於資料需求/分類,分發至關係型資料庫、圖資料庫以及 AnalyticDB 等。
阿里雲資料庫:客戶第一,一切價值來自於服務使用者
目前 POLARDB 資料庫的增勢迅猛,已經服務於通用行業、網際網路金融、遊戲、教育、新零售、多媒體等多個領域的龍頭企業。
而 AnalyticDB 在分析型資料庫市場也有非常出眾的表現,支援實時分析以及視覺化應用。
基於阿里雲資料庫技術,阿里巴巴支援了城市大腦等一系列關鍵專案及雲上雲下的大量客戶。截止目前為止,阿里雲資料庫已經累計支援了近40萬資料庫例項成功上雲。
雲原生是資料庫的新戰場,它為發展了40多年的資料庫行業帶來了許多令人激動的新挑戰和新機遇,阿里巴巴希望與國內外資料庫行業的各位技術同仁一起,將資料庫技術推向更高的境界。
本文作者: 李飛飛
本文來自雲棲社群合作伙伴“ 阿里技術”,如需轉載