
Mysql心路歷程:Mysql各種鎖機制(進階篇)
通過上一篇基本鎖的介紹,基本上Mysql的基礎加鎖步奏,有了一個大概的瞭解。接下來我們進入最後一個鎖的議題:間隙鎖。間隙鎖,與行鎖、表鎖這些要複雜的多,是用來解決幻讀的一大手段。通過這種手段,我們沒必要將事務隔離級別調整到序列化這個最嚴格的級別,而導致併發量大大下降。讀取這篇文章之前,我想,我們要首先還是讀一下我先前的兩篇文章,否則一些理念還真的透徹不了:
一、基礎測試表與資料
為了進行整個間隙鎖的深入,我們要構建一些基礎的資料,本章我們都會用構建的基礎資料來進行,下面是資料表與索引的建立:
create table `t` (
`id` int(11) not null,
`c` int(11) DEFAULT null,
`d` int(11) DEFAULT null,
primary key (`id`),
key `c` (`c`)
) ENGINE=InnoDB;
然後我們插入一些基礎的資料:
insert into t values
(0,0,0),
(5,5,5),
(10,10,10),
(15,15,15),
(20,20,20),
(25,25,25);
另外,我們本次講解,都是使用預設的資料庫隔離級別:可重複讀
二、什麼叫幻讀
好,這個問題,就很關鍵了!我們來細說,幻讀的具體出現的經典場景。其實很簡單,先看下面的具體的復現sql語句:
| sessionA | sessionB | sessionC | |
|---|---|---|---|
| t1 | begin; | ||
| select * from t where d = 5 for update; | |||
| t2 | update t set d = 5 where id = 0; | ||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5) | ||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
針對這一系列的操作,我們來一個個分析:
- sessionA在t1時刻,可見讀的結果是:(5,5,5),d沒有索引,所以是全表掃描,對id為5的那一行,加行鎖的寫鎖
- 由於sessionB再t2時刻,將id為0的資料改了下,所以t3時刻,sessionA的可見讀的結果是:(0,0,5),(5,5,5)
- 由於sessionC再t4時刻,插入了條不存在的資料,所以t6時刻,sessionA的可見讀結果是:(0,0,0)(1,1,5)(5,5,5)
- 如果,我們不新增for update進行可見讀,普通的一致性讀的情況下,由於mvcc的建立快照機制的影響,sessionA一直都會只看到(5,5,5)這一條資料
- update之後,可見讀查出來的多一條資料,並不是幻讀,只有插入之後的可見讀,多讀出來的資料,才叫幻讀。就好比我們本來有兩條原始資料,可是在事務的沒結束之前的前後去讀,分別讀出來2條和3條,多出一條,就好像我在之後讀出的3條資料,是幻影一樣,突然出現了,所以叫幻讀。
- 雖然我們平時幾乎不會使用select for update進行查詢,但是,要記住,update語句之前就是要進行一次for update的select查詢的!
三、幻讀會有什麼影響
大概上,有兩個影響,如下。
1、語義衝突
select * from t where d = 5 for update;
類似的,我們這條語句,其實語義上面是想鎖住所有d等於5的行資料,讓其不能update和insert。然而,我們接下來的sessionB和sessionC裡面,如果沒有相關的解決幻讀的機制存在,那麼都會有問題:
-- sessionB增加點操作
update t set d = 5 where id = 0;
update t set c = 5 where id = 0;
可見第二條sql已經操作了id等於0,d等於5這一行的資料,與之前的鎖所有等於5的行語義上面衝突。
2、資料一致性問題
這個很關鍵,涉及到binglog問題。下面是我們具體操作的sql表格:
| sessionA | sessionB | sessionC | |
|---|---|---|---|
| t1 | begin; | ||
| select * from t where d = 5 for update; | |||
| update t set d = 100 where d = 5; | |||
| t2 | update t set d = 5 where id = 0; | ||
| update t set c = 5 where id = 0; | |||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5); | ||
| update t set c = 5 where id = 1; | |||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
由於,binglog是要等commit之後,才會記錄的(後面文章會有細節的講解),所以,上面這一系列的sql操作,到了binglog裡面會變成下面的樣子:
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/
可以看到,由於我們前面說,只對id等於5這一行,加了行鎖,所以sessionB的操作是可以進行的,所以,最終會發現,我們sessionA裡面的update操作,是最後執行的,如果拿著這個binglog同步從庫的話,必然會導致,(0,5,100)、(1,5,100) 和 (5,5,100)這種資料出現,和主庫完全不一致!(主庫裡面,只有id為5的資料,d才為100)。
那麼我們將所有掃秒到的資料行都加了鎖,會如何呢?那麼,sessionB裡面的第一條update語句將被阻塞,binglog裡面的資料如下:
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
這樣的結果,id為0的這一行的資料,的確能保證資料的一直性,但是,會發現,剛剛插進去的id為1的這一樣,在主庫裡面,d的值為5,但是在從庫裡面執行了binglog之後,會變成100,又會有不一致的情況出現了!
四、初入"間隙鎖"
針對幻讀問題,我們日常理論中經常"背誦"的,是:第三事務隔離級別會出現幻讀情況,只有通過提高隔離級別,到最高級別的序列化,能解決幻讀這樣的問題。但是這樣,每一個時刻只能有一個執行緒操作同一個表,併發性大大的降低,根本無法滿足,高併發的需求,要知道,Mysql這東西,可是各大頂級網際網路公司趨之若鶩的基礎資料庫,怎麼能效率這麼差呢?在這裡,Mysql就引入了間隙鎖的概念。下面我們來看看,間隙鎖如何加鎖。
1、間隙鎖的產生
首先,如果我們使用下面語句進行查詢:
select * from t where d = 5 for update;
這樣,由於d是沒有索引的,那麼會走全表查詢,預設走的是id的主鍵索引,按照id的主鍵值,會產生如下的區間:
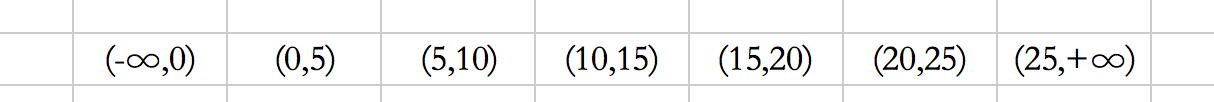
2、如何加間隙鎖
例如上面的select語句中,d是沒有索引的,所以通過id索引進行全表掃面,又因為是for update,那麼,會將表中僅有的六條資料,都加上行鎖,然後,針對上面的六個區間,也會加上間隙鎖。行鎖+間隙鎖就是我們喜聞樂見的:next-key lock了!所以,整體上看也就是7個next-key lock:
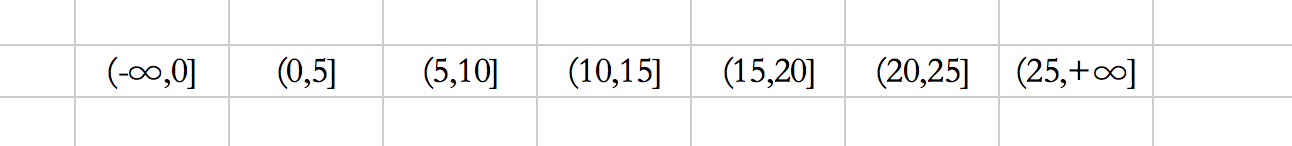
這個+∞是可以進行配置的,給每個索引分配一個不存在的值
3、間隙鎖的特性
前面的文章,我們似乎聊過行鎖之間的互斥形式:
| 讀鎖 | 寫鎖 | |
|---|---|---|
| 讀鎖 | 相容 | 衝突 |
| 寫鎖 | 衝突 | 衝突 |
但是間隙鎖不是。和間隙鎖衝突的,是往這個間隙裡面插入一條資料!這一點也是很好的保持併發性的一個挽回。下面看一個操作:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from t where c = 7 lock in share model; | |
| begin; | |
| select * from t where c = 7 for update; |
雖然,兩個事務,都是真對同一條資料,進行可見讀的查詢,但是並不會阻塞!因為c沒有7的這個值,那結果就是,只會在資料庫裡面加上了(5,10)這個間隙鎖,兩個可見讀並不會因為間隙鎖和互斥衝突!
如果這樣,加上間隙鎖的特性,和行鎖的特性,針對上面章節的sql操作:
| sessionA | sessionB | sessionC | |
|---|---|---|---|
| t1 | begin; | ||
| select * from t where d = 5 for update; | |||
| update t set d = 100 where d = 5; | |||
| t2 | update t set d = 5 where id = 0;(阻塞) | ||
| update t set c = 5 where id = 0; | |||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5);(阻塞) | ||
| update t set c = 5 where id = 1; | |||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
最終生成的binglog就會是:
update t set d=100 where d=5;/* d 改成 100*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
這樣,就解決了資料一致性的問題了,主從庫裡面都能保持一致。
4、間隙鎖帶來的問題
雖然,間隙鎖能比較好的解決上訴我們探討的問題,但是同時也會帶來些麻煩,要我們特別的注意。例如下面的操作,是一段業務上面的虛擬碼:
tx.beginTransaction();
var t = select * from t where id = 9 for update;
if(t){
update t set d = 45 where id = 9;
}else{
insert into t values(9,5,45);
}
tx.commit();
(假設id等於9這一行不存在)這段業務邏輯程式碼,普通情況下,我也經常看到,問題不太會出現,一旦併發量上去了,就會出問題,會造成死鎖,下面我們看看造成死鎖的sql執行序列:
| sessionA | sessionB | |
|---|---|---|
| t1 | begin; | |
| select * from t where id = 9 for update; | ||
| begin; | ||
| t2 | select * from t where id = 9 for update; | |
| insert into t values(9,5,45);(阻塞,等待sessionA的(5,10)的間隙鎖釋放) | ||
| t3 | insert into t values(9,5,45); (阻塞,等待sessionB的(5,10)的間隙鎖釋放,死鎖!) |
當然,InnoDB的自動死鎖檢測,會發現這一點,主動將sessionA回滾,報錯!
五、晉級"間隙鎖"
有關於間隙鎖,是最後一層級的細節所在,所以在判斷是否加、怎麼加、是否會阻塞方面,有非常多的考量。接下來我們來分別來說一下4個細節,分別對應4個例子,來講講,首先我們列出五條規則:
- 加鎖的基本單位是next-key lock,就是針對掃描過的資料進行加間隙鎖
- 索引上進行等值查詢時,給唯一索引加鎖的時候,next-key lock退化為行鎖
- 索引上進行等值查詢時,向右遍歷,最後一個數值不滿足等值的條件的時候,next-key lock退化為間隙鎖,就是前後都是開區間
- 唯一索引的範圍查詢,會訪問到第一個不滿足的條件為止
1、第一條規則
加鎖的基本單位是next-key lock,就是針對掃描過的資料進行加間隙鎖
先來看看幾個sql語句:
select * from t where id = 5 for update;
select * from t where id = 10 lock in share model;
兩個分別對5和10這兩行加了寫鎖與讀鎖,但是最開始,再索引樹上面,首先載入id為5和10的這兩行的時候,加鎖步驟如下:
- 加(0,5)和(5,10)這兩個間隙鎖
- 加5的這一行的行鎖(寫鎖),加10這一行的行鎖(讀鎖)
- 所以目前為止,基礎加鎖的單位為next-key lock
2、第二條規則
索引上進行等值查詢時,給唯一索引加鎖的時候,next-key lock退化為行鎖
還是第一條規則的兩天語句,發現,id是主鍵索引(唯一索引),所以去掉了(0,5)(5,10)的這兩個間隙鎖,所以整個next-key lock變成了單純的行鎖
3、第三條規則
索引上進行等值查詢時,向右遍歷,最後一個數值不滿足等值的條件的時候,next-key lock退化為間隙鎖,就是前後都是開區間
先來看看下面的操作過程:
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; | ||
| update t set d = d+1 where id = 7; | ||
| insert into t values (8,8,8);(阻塞!) | ||
| update t set d = d+1 where id = 10;(成功) |
我們來分析:
- update之前會進行select for update操作,所以就是對id為7的這一行進行可見讀
- 由於7這行記錄不存在,但是7落在了(5,10)這個區間,而根據第一條原則,加鎖基本單位是next-key lock,所以加鎖會加上(5,10)的間隙鎖,和10這一行的行鎖(寫鎖),就是(5,10]
- 由於最後一條記錄10和等值查詢中的7並不相等,所以退化成了間隙鎖,10這個的行鎖解除。
所以根據這個規則,(5,10)這個區間是被鎖住額,所以insert會被阻塞,另外10這一行的行鎖解除,所以sessionC中的update會成功。
4、第四條規則
唯一索引的範圍查詢,會訪問到第一個不滿足的條件為止
看看下面的操作序列:
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; | ||
| select * from t where id > 10 and id <=15 for update; | ||
| update t set d = d+1 where id = 20;(阻塞) | ||
| insert into t values(16,16,16);(阻塞) |
分析:
- 由於10不是等值,15是等值,所以10這一條不會加next-key lock,15會,所以首先加上了(10,15]
- 雖然是唯一索引,但是是區間查詢,並不會停止加鎖的腳步,會繼續向右
- 找到20這條記錄,加上了next-key lock的(15,20]
- 由於不是等值查詢,是範圍查詢,所以應用不了規則三,所以最終形成的鎖是:(10,15],(15,20]
這麼一看,20這一行被行鎖鎖住,而且15,20的區間還有間隙鎖,所以sessionB和sessionC的操作才會阻塞。
5、其他方面的細節
每次加鎖,其實都是鎖索引樹。眾所周知,InnoDB的非主鍵索引的最終葉子節點,都只儲存id主鍵值,然後還要遍歷id主鍵索引,才能搜尋出整條的資料,我們通常將這個過程稱之為:回表。當然,如果select的是一個欄位,這個欄位剛好是id,那麼Mysql就不用進行回表查詢,因為直接在索引樹上就能讀取到值,MySQL會進行這種優化,通常我們稱之為:索引下推。根據這個特性,我們來看看下面的操作序列:
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; | ||
| select id from t where c = 5 lock in share model; | ||
| update t set d = d+1 where id = 5;(成功) | ||
| insert into t values(3,3,3);(阻塞) |
- 只在c這個非唯一索引上,加了行讀鎖,基礎的加鎖單位是(0,5],由於是非唯一索引的查詢,並不能退化為行鎖
- 由於非唯一索引,要繼續往下,加上了(5,10]這一個的next-key lock,由於最右邊的最後一個值,和等值查詢並不相等,所以退化成間隙鎖(5,10),所以sessionC會被阻塞
- 由於sessionA中的可見讀是讀鎖,並且只查詢id的值,所以啟動了索引下推優化,只會加c這個索引上面的行鎖。如果換成for update,那就會順便將主鍵索引上面也加上鎖。所以這裡要分清兩種行鎖的粒度。
- 所以,最後,sessionB能成功的願意是:主鍵索引上並沒有加鎖
六、結束
鎖,在我的能力範圍能,能說的就這麼多,具體還是要用於實踐。接下來,打算寫很重要的兩個日誌檔案的介